Reka AI 正式发布了其推理模型 Reka Flash 3.1,这是其 21 亿参数模型 Reka Flash 3 的重要升级版本。该模型在代码生成、智能体任务微调等方面表现尤为突出,并作为 Reka Research 智能体系统的核心推理模块,用于在网页和私有文档中搜索信息、回答复杂问题。
本次升级的核心在于其强化学习(Reinforcement Learning, RL)训练流程的全面优化,使得 Reka Flash 3.1 在多个关键任务上取得了显著性能提升。
核心能力亮点
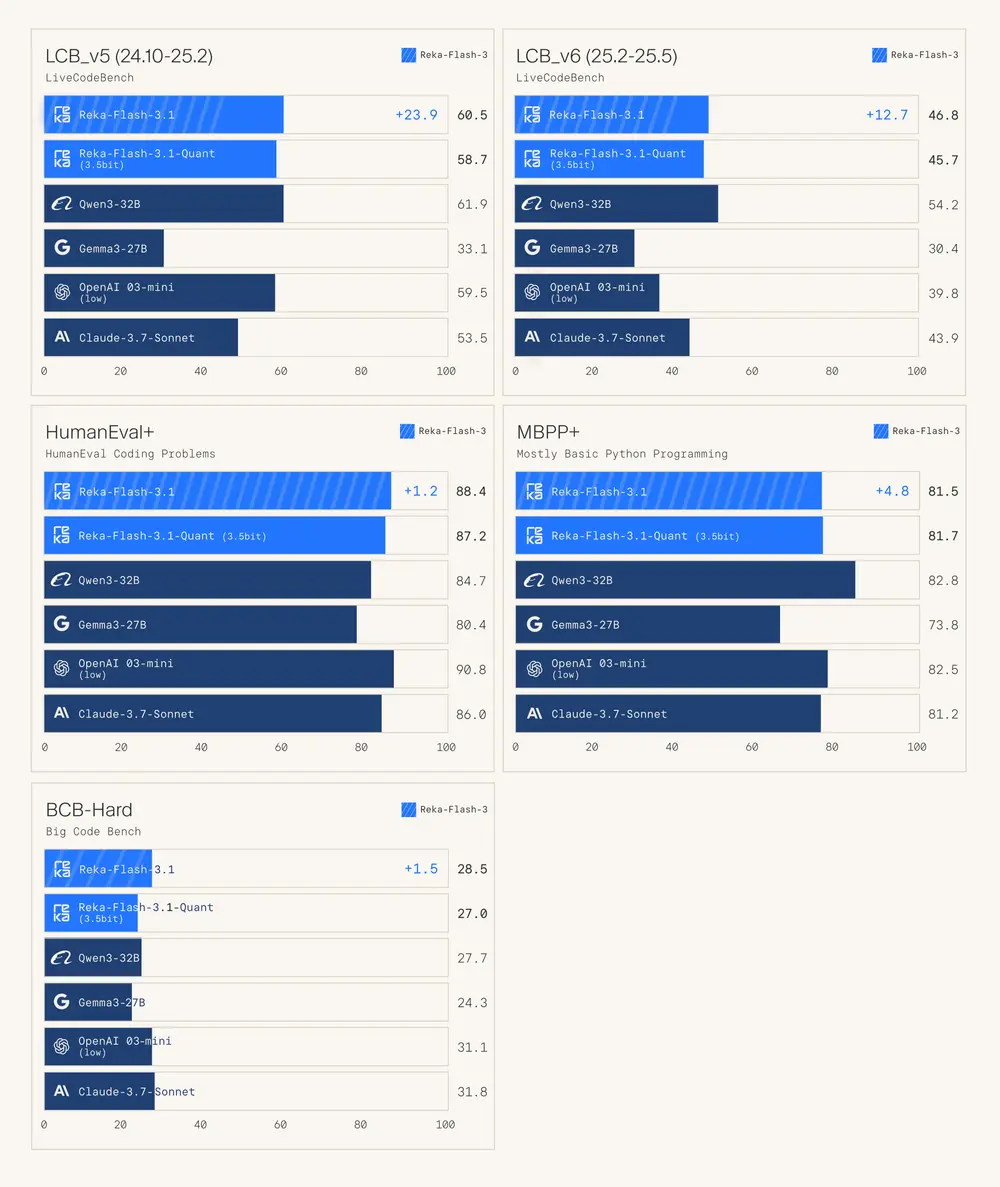
- ✅ 强大的代码生成能力:在 LiveCodeBench v5 上相较 Reka Flash 3 提升了 10 个百分点。
- ✅ 智能体任务适配性高:适合作为智能体系统中的基础规划器,支持复杂任务分解与执行。
- ✅ 多模型对比表现优异:在编码任务中表现与 Qwen3-32B、o3-mini 和 Gemini 2.5 Flash Thinking 等主流模型相当甚至更优。
- ✅ Llama 兼容格式发布:便于部署与集成,开发者可使用任意支持 Llama 格式的库运行该模型。
技术亮点解析
1. 基于强化学习的训练优化
Reka Flash 3.1 的训练流程包括两个主要阶段:
- 监督微调(SFT):使用合成数据和公开数据集进行初始训练;
- 大规模强化学习(RLOO):使用可验证奖励函数进一步优化模型输出。
这一强化学习阶段采用了以下关键技术:
- REINFORCE 变体算法:结合动态采样策略,提升探索效率;
- Token 级损失计算:更精细地控制生成质量;
- 基于梯度范数的智能裁剪:增强训练稳定性;
- DAPO 风格的长样本处理机制:提升模型在复杂任务上的泛化能力;
- 在线策略更新(On-policy):每次 rollout 后立即更新,保持策略一致性;
- 训练样本去重机制:避免 RL 与 SFT 数据重叠,防止负向轨迹影响训练效果。
这些改进共同推动了 Reka Flash 3.1 在多个任务上的性能跃升。
2. 奖励函数设计
Reka Flash 3.1 的强化学习训练中,使用了可验证奖励函数,主要包括:
- 数学任务奖励:基于 Numina-1.5 数据集构建,过滤无效、重复和过于简单的样本;
- 代码任务奖励:聚焦高难度编码问题,确保每个样本包含多个测试用例;
- 防奖励欺骗机制:将多选题转化为填空题,防止模型利用规则漏洞。
这些奖励机制确保了训练过程的稳定性和生成结果的可靠性。
3. 分布式训练与执行机制
为了提升训练效率,Reka 团队采用了分布式执行机制:
- 每个 rollout 完成后立即执行测试;
- 支持并行化训练流程;
- 提升整体训练吞吐量。
实验评估结果
| 模型名称 | LiveCodeBench v5 提升幅度 |
|---|---|
| Reka Flash 3 → 3.1 | ↑10 个百分点 |
此外,在 AIME2024 和 LCB-v5 等数学与编码任务上的性能随着训练迭代逐步提升,验证了其强化学习系统的有效性。
应用场景示例
Reka Flash 3.1 被用于构建 Reka Research 智能体系统,其典型应用场景包括:
- 网页与文档浏览:自动搜索网页和私有文档以回答复杂问题;
- 代码编写与调试:辅助开发者快速生成高质量代码;
- 任务分解与执行:作为智能体核心推理模块,支持多步骤任务的规划与实现。
快速部署方式
Reka Flash 3.1 以 Llama 兼容格式发布,开发者可使用任意支持 Llama 架构的库(如 Transformers、Llama.cpp、vLLM 等)进行部署。模型已发布在 Hugging Face 平台,支持开源下载与使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...