小红书 Hi Lab 发布 1420 亿参数 MoE 大模型 dots.llm1:推理仅激活 140 亿参数,性能媲美 Qwen2.5-72B小红书 Hi Lab 团队近日正式开源了其自研大规模 MoE 文本大模型 dots.llm1,该模型总参数量高达 1420 亿(142B),但在每次推理时仅激活 140 亿(14B)参数,实现了高效能...大语言模型# dots.llm1# 小红书8个月前03070
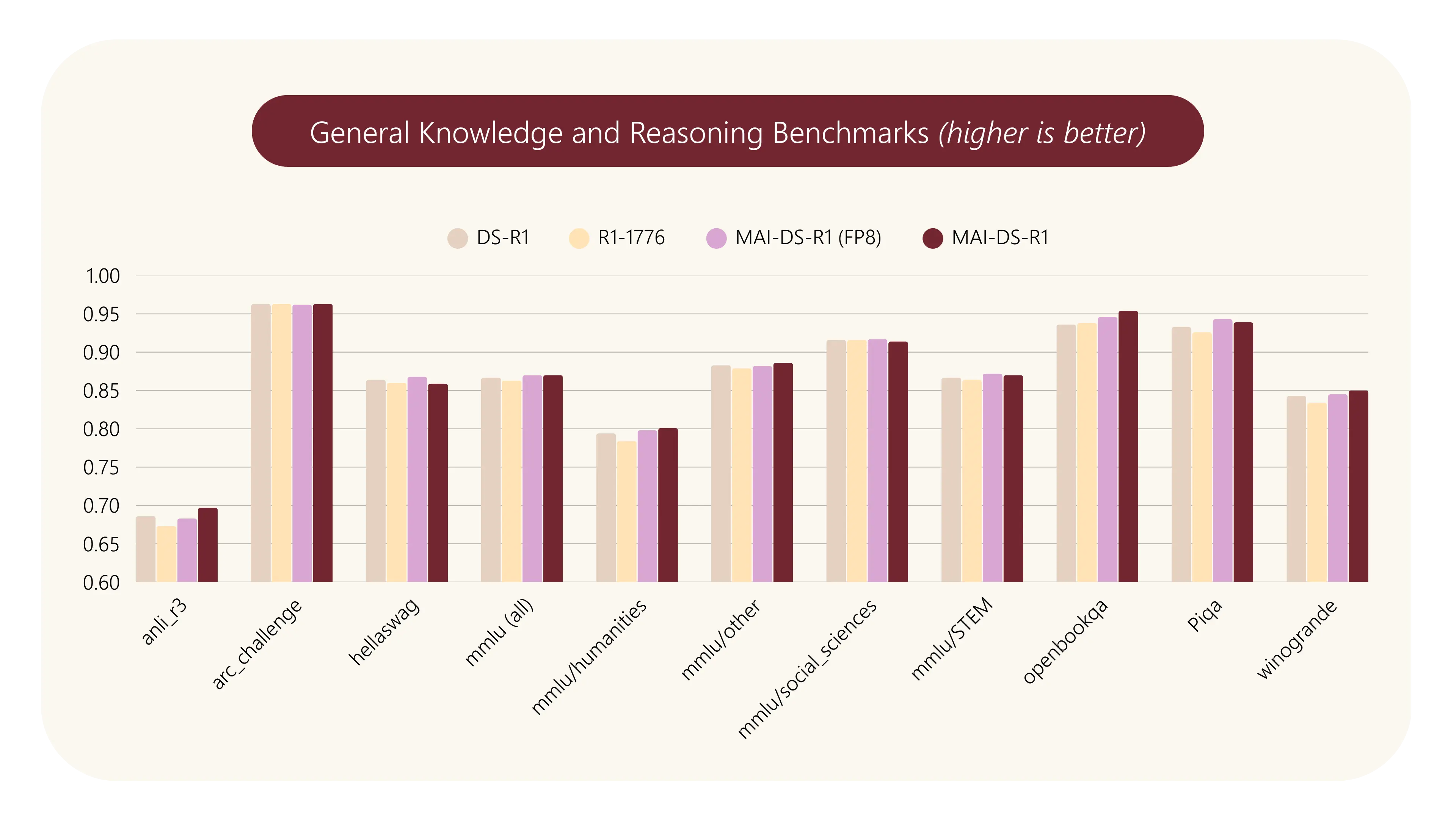
MAI-DS-R1:微软团队基于DeepSeek-R1 推理模型进行后训练的版本MAI-DS-R1 是一个由微软 AI 团队对 DeepSeek-R1 推理模型进行后训练的版本,提升其对受限话题的响应能力并改善其风险状况,同时保持推理能力和竞争力。简单来说就是把欧美的偏见加进去...大语言模型# DeepSeek-R1# MAI-DS-R1# 微软10个月前03070
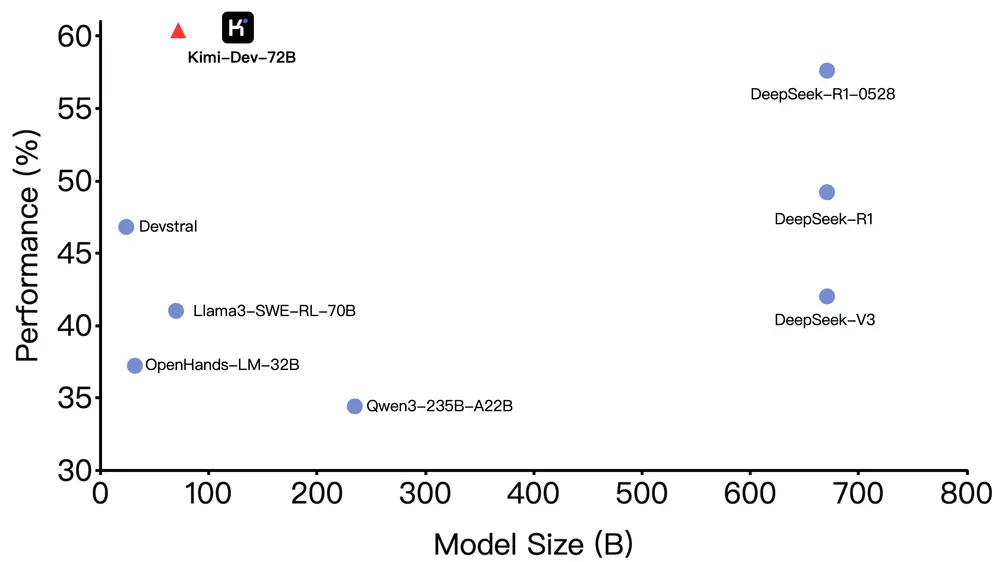
月之暗面推出Kimi-Dev-72B:为软件工程任务打造的新一代开源编码大模型月之暗面推出一款全新的开源编码大语言模型 Kimi-Dev-72B,专为软件工程任务设计。该模型基于 Qwen2.5-72B 微调而来,在 SWE-bench Verified 测试中取得了 60.4...大语言模型# Kimi-Dev-72B# 月之暗面8个月前03060
深度求索发布 DeepSeek-V3.1:混合思考模式 + 128K 上下文,API 同步升级并支持 Anthropic 格式深度求索(DeepSeek)正式推出 DeepSeek-V3.1 —— 一个在架构设计、推理效率和智能体能力上全面升级的新版本模型。此次更新不仅提升了性能,更引入了混合思考模式,让同一个模型可灵活适应...大语言模型# DeepSeek-V3.1# 深度求索5个月前03050
上海交通大学发布SmallThinker 系列模型:专为设备端部署设计的原生混合专家(MoE)语言模型由上海交通大学 IPADS 实验室、人工智能学院与 Zenergize AI 联合研发的 SmallThinker 系列模型,是一组专为设备端部署设计的原生混合专家(MoE)语言模型。其核心目标是在资...大语言模型# SmallThinker# 上海交通大学6个月前03050
卷麻了!阿里在除夕夜推出超大规模的 MoE 模型 Qwen2.5-Max过去,有一种观点认为,持续增加数据规模和模型参数可能是通向人工通用智能(AGI)的一条可行路径。然而,无论是对于稠密模型还是MoE(Mixture of Experts)模型而言,整个大模型社区在训练...大语言模型# MoE# Qwen2.5-Max# 阿里12个月前03020
清华、蚂蚁等联合发布ASearcher:开源大规模强化学习搜索代理由清华大学交叉信息研究院、蚂蚁研究院、强化学习实验室与华盛顿大学的研究团队联合推出 ASearcher —— 一个面向大规模在线强化学习(Reinforcement Learning, RL)的开源搜...大语言模型# ASearcher# inclusionAI6个月前02990
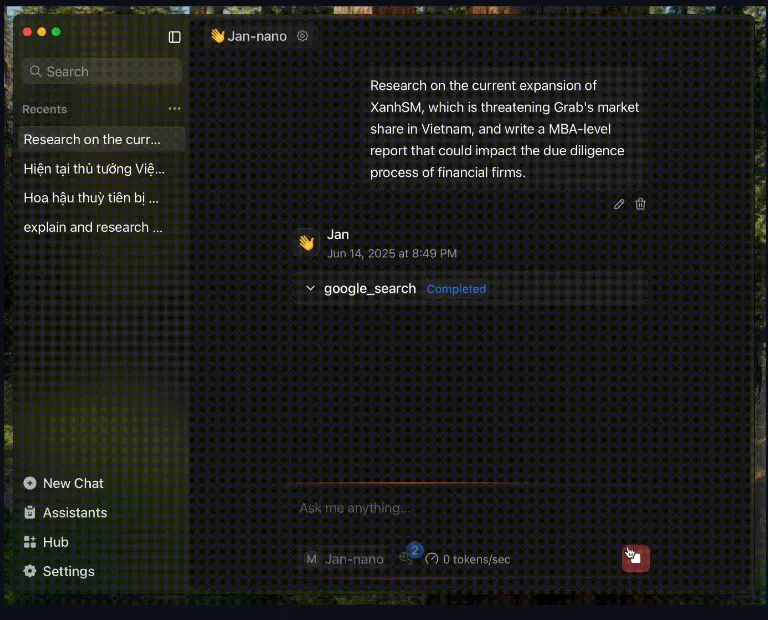
Jan-Nano:40亿参数的紧凑型研究专用语言模型正式上线Menlo发布一款专为深度研究任务设计的小型语言模型 Jan-Nano 。该模型拥有 40亿参数规模,在保证轻量级部署的同时展现出强大的推理能力。此模型基于 Qwen3-4B 构建,并经过 DAPO ...大语言模型# Jan-Nano# 小型语言模型8个月前02990
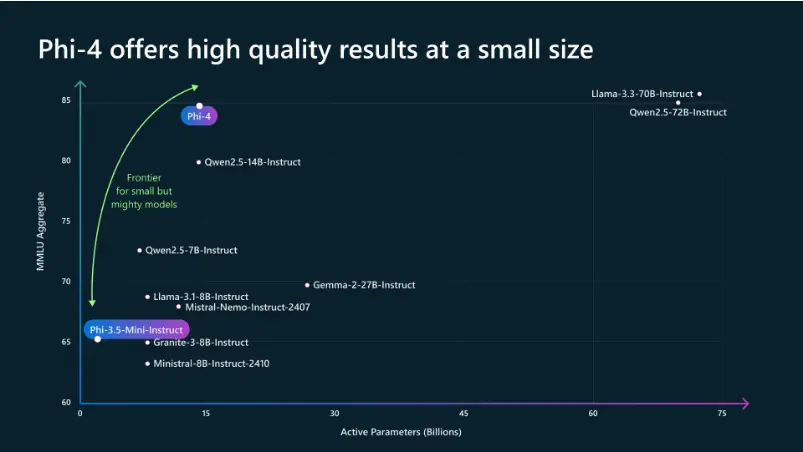
微软正式开源了Phi-4:拥有140亿参数的小型语言模型去年12月,微软推出了其Phi系列的最新成员——Phi-4,该模型在解决数学问题等方面展现了显著的进步。这些进步主要得益于训练数据质量的提升,特别是采用了高质量的合成数据集和人类生成的内容数据集。然而...大语言模型# Phi-4# 微软12个月前02980
华为开源盘古 Embedded-7B-V1.1:支持“快慢思考”的高效大模型华为正式开源新一代高效大语言模型 —— openPangu-Embedded-7B-V1.1。该模型是基于昇腾 NPU 从零训练的 7B 级别密集架构模型(不含词表 Embedding),在通用能力...大语言模型# openPangu-Embedded-7B-V1.1# 华为# 盘古5个月前02970
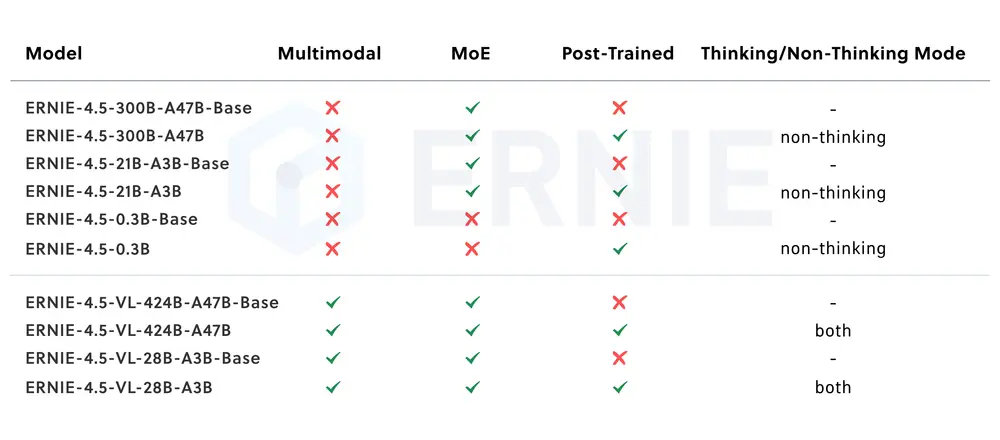
百度开源 ERNIE 4.5:覆盖 0.3B 到 424B 参数的大型语言模型系列百度正式开源了其最新的 ERNIE 4.5 系列,这是继 ERNIE 系列之后又一重磅发布的基础语言模型家族。该系列包含 10 款不同规模与架构的模型,从仅 0.3B(十亿)参数的小型密集模型 到高达...大语言模型# ERNIE 4.5# 百度7个月前02930
腾讯推出混元自研深度思考模型 T1 正式版:吐字快、能秒回,擅长超长文处理腾讯正式推出了其自主研发的深度思考模型——混元 T1 正式版。这款模型以其快速响应、擅长处理超长文本及强大的推理能力而著称,标志着腾讯在AI领域的又一重要进展。 项目主页:https://tencen...大语言模型# 混元 T1# 腾讯11个月前02920