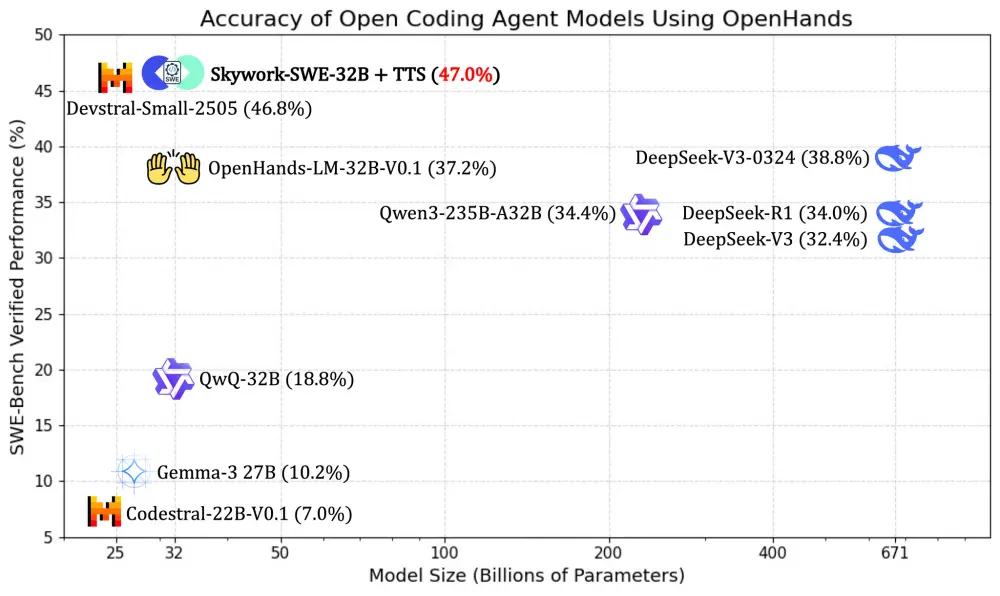
昆仑万维开源代码模型 Skywork-SWE-32B:用消费级显卡部署 AI 工程师的新可能今天,昆仑万维正式宣布开源其最新推出的代码智能体 Skywork-SWE-32B,该模型专为软件工程(SWE)任务设计,在 SWE-bench Verified 基准测试中达到 38.0% 的 pas...大语言模型# Skywork-SWE-32B# 代码模型# 昆仑万维7个月前03100
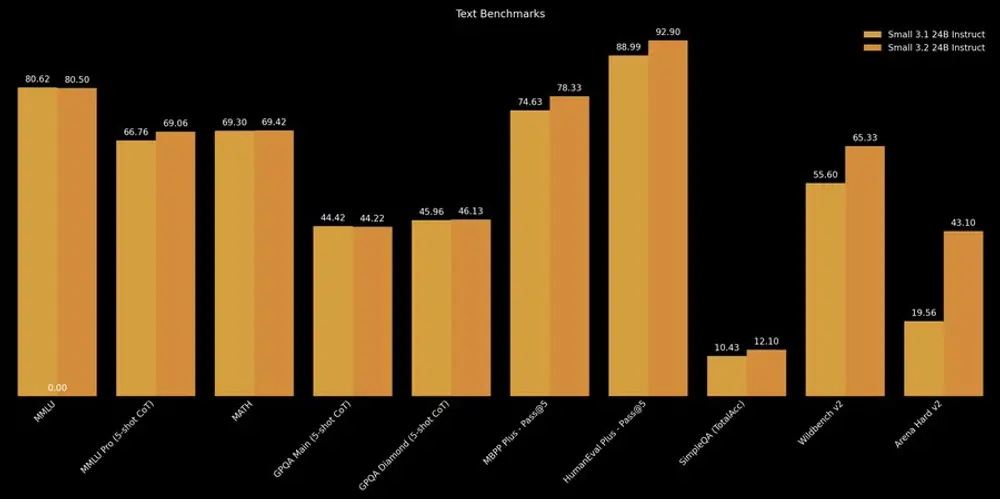
Mistral AI 发布 Mistral Small 3.2:小幅迭代,体验提升Mistral AI 推出了其中型模型系列的新版本——Mistral Small 3.2。这是对上一版 Mistral Small 3.1 的一次轻量级升级,在多个关键使用场景中带来了显著优化。 模型...大语言模型# Mistral AI# Mistral Small 3.27个月前01250
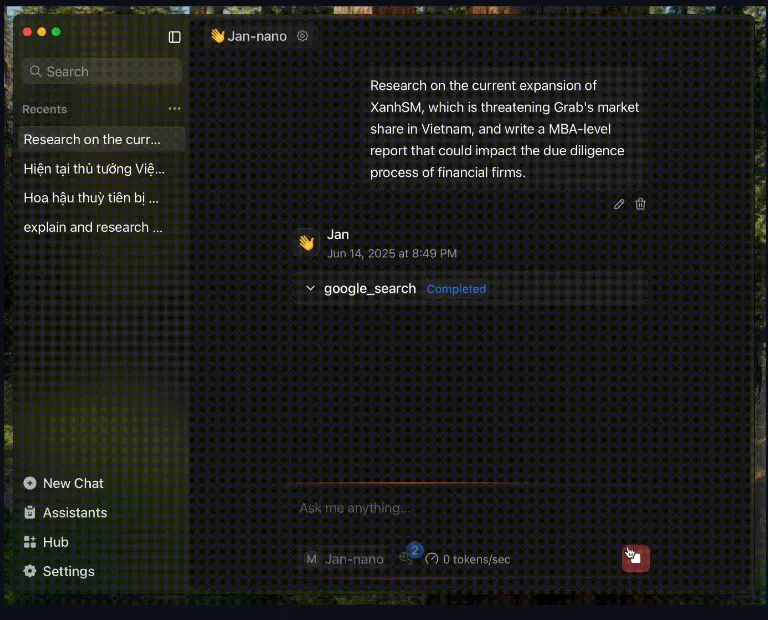
Jan-Nano:40亿参数的紧凑型研究专用语言模型正式上线Menlo发布一款专为深度研究任务设计的小型语言模型 Jan-Nano 。该模型拥有 40亿参数规模,在保证轻量级部署的同时展现出强大的推理能力。此模型基于 Qwen3-4B 构建,并经过 DAPO ...大语言模型# Jan-Nano# 小型语言模型8个月前02990
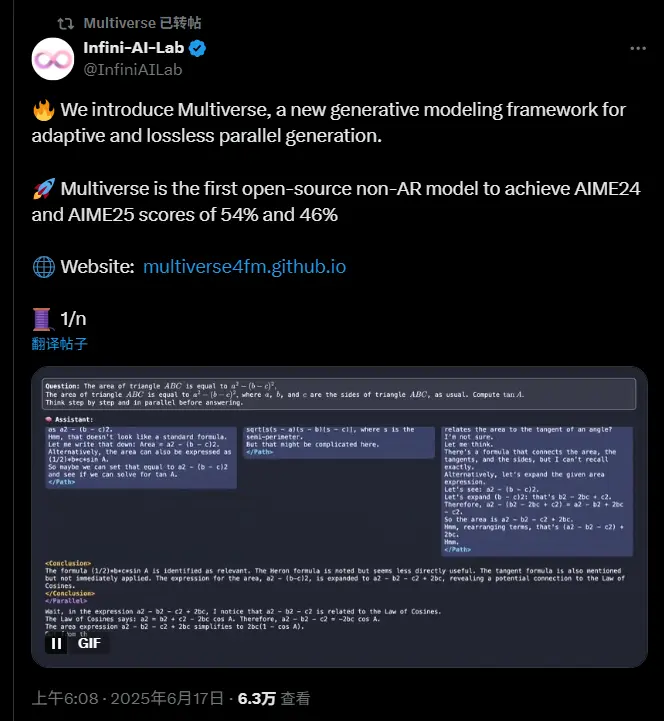
Multiverse:全球首个开源的非自回归并行推理框架,推理速度提升2倍卡内基梅隆大学与英伟达联合推出了一项具有突破性的生成模型框架——Multiverse。这是全球首个开源的非自回归(Non-Autoregressive)并行推理框架,在保持与主流自回归模型(AR-LL...大语言模型# Multiverse# 推理框架8个月前01760
MiniMax发布全球首款开源大规模混合注意力推理模型MiniMax-M1近日,MiniMax 宣布推出全新大语言模型 MiniMax-M1,这是全球首款开源的大规模混合注意力推理模型,专为复杂任务和长上下文场景设计。 GitHub:https://github.com/M...大语言模型# MiniMax# MiniMax-M18个月前02240
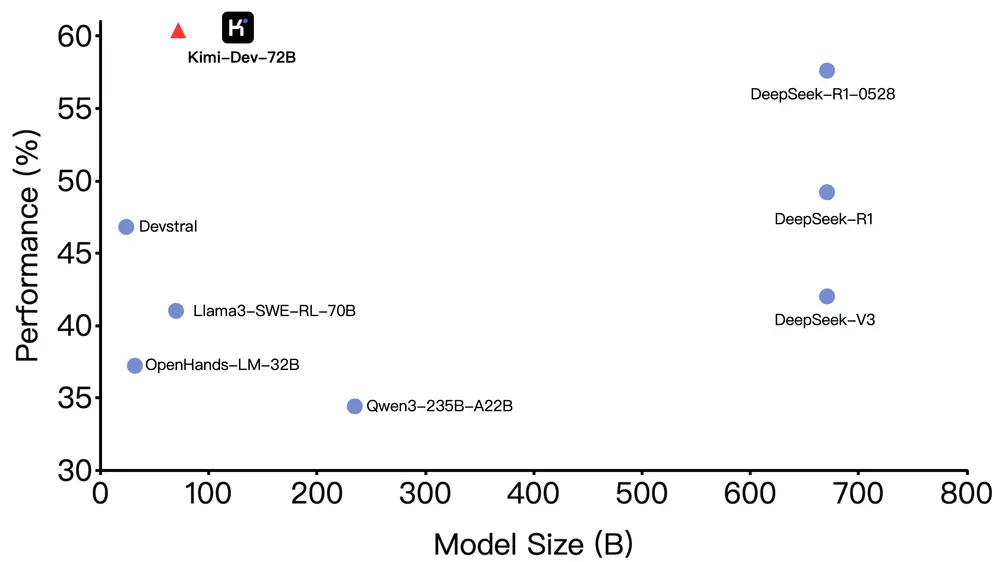
月之暗面推出Kimi-Dev-72B:为软件工程任务打造的新一代开源编码大模型月之暗面推出一款全新的开源编码大语言模型 Kimi-Dev-72B,专为软件工程任务设计。该模型基于 Qwen2.5-72B 微调而来,在 SWE-bench Verified 测试中取得了 60.4...大语言模型# Kimi-Dev-72B# 月之暗面8个月前03060
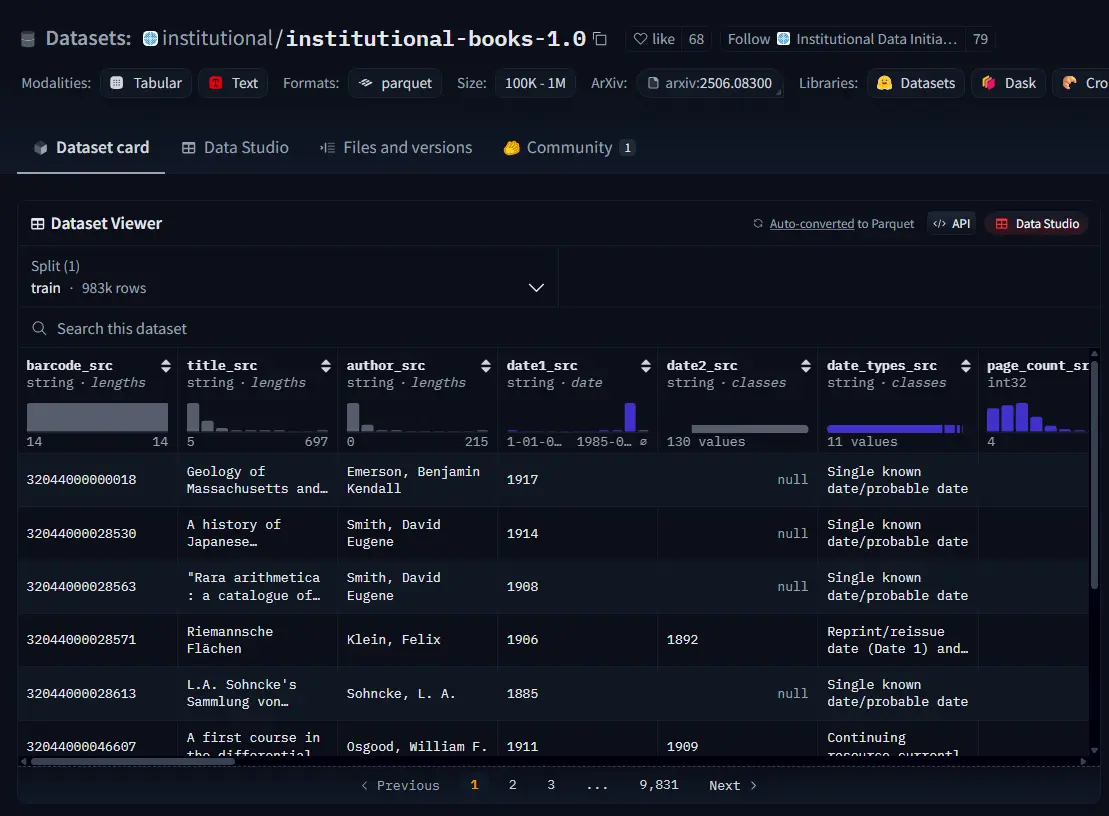
微软与 OpenAI 支持,哈佛法学院发起:首个大规模公共 AI 图书数据集正式开源上周,由微软与 OpenAI 联合资助、起源于哈佛大学法学院图书馆研究计划的 机构资料计划(Institutional Data Initiative,简称 IDI)宣布开源其首个大型 AI 数据集...大语言模型# OpenAI# 哈佛法学院# 微软8个月前02450
Mistral发布首款推理模型Magistral,挑战Gemini 2.5 Pro与Claude Opus法国AI实验室 Mistral AI 正式发布了其首个推理模型家族——Magistral,标志着这家以开源著称的AI公司正式进军高阶推理领域。 该系列包括两个版本: Magistral Small(2...大语言模型# Magistral# Mistral AI# 推理模型8个月前01360
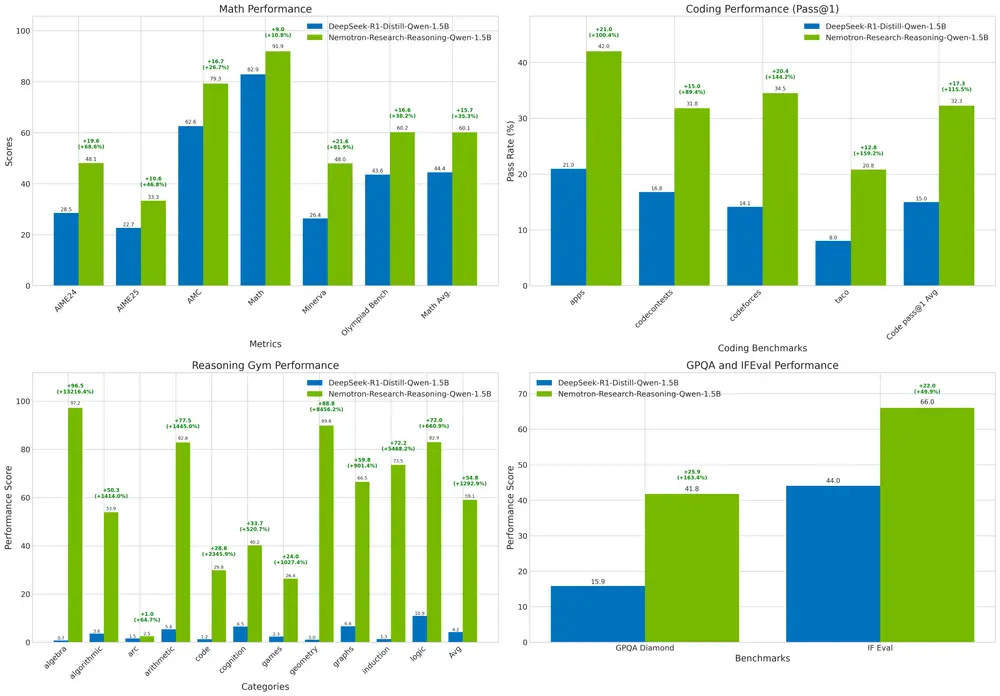
英伟达推出一款专为复杂推理任务设计的开源模型 — Nemotron-Research-Reasoning-Qwen-1.5B英伟达近日发布了一款专为复杂推理任务设计的开源模型 —— Nemotron-Research-Reasoning-Qwen-1.5B,该模型参数量为 1.5B,在数学、编程、科学问题和逻辑谜题等任务上...大语言模型# Nemotron-Research-Reasoning-Qwen-1.5B# 英伟达8个月前01170
小红书 Hi Lab 发布 1420 亿参数 MoE 大模型 dots.llm1:推理仅激活 140 亿参数,性能媲美 Qwen2.5-72B小红书 Hi Lab 团队近日正式开源了其自研大规模 MoE 文本大模型 dots.llm1,该模型总参数量高达 1420 亿(142B),但在每次推理时仅激活 140 亿(14B)参数,实现了高效能...大语言模型# dots.llm1# 小红书8个月前03090
面壁智能发布 MiniCPM 4.0:端侧大模型效率再升级,极限提速 220 倍!6 日晚,面壁智能正式发布了新一代高效端侧大语言模型 MiniCPM 4.0。该系列模型以极致轻量化和高效推理为核心目标,结合自研 CPM.cu 推理框架 和稀疏注意力机制,在端侧设备上实现了惊人的性...大语言模型# MiniCPM 4.0# 面壁智能8个月前03430
EleutherAI 发布首个大规模许可训练数据集 The Common Pile v0.1近日,开源人工智能研究组织 EleutherAI 正式发布了名为 The Common Pile v0.1 的全新训练数据集。该数据集据称是目前用于训练 AI 模型的最大合法授权+公共领域文本集合之一...大语言模型# EleutherAI# The Common Pile v0.1# 数据集8个月前03150