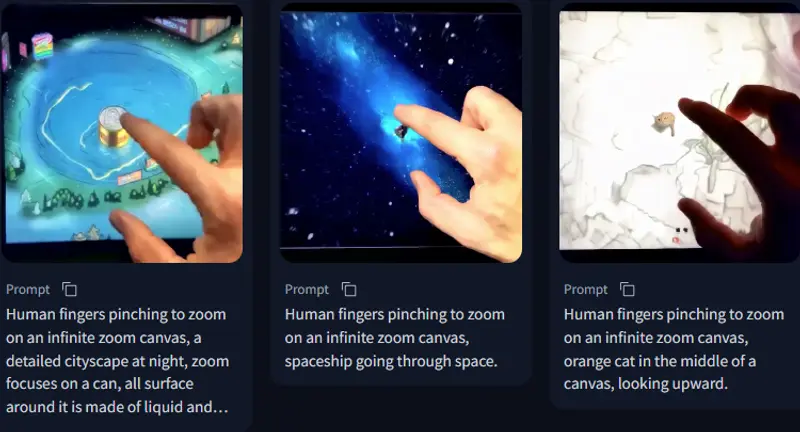
InfiniteZoom-Mochi:基于视频生成模型Mochi的LoRA,专注于无限缩放艺术风格InfiniteZoom-Mochi是一个视频生成模型Mochi的LoRA,专注于无限缩放艺术风格。无限缩放艺术风格是一种独特的视觉效果,通过不断放大图像的某个部分,创造出一种无限深入的感觉。应用此L...视频模型# InfiniteZoom-Mochi# 无限缩放10个月前02590
Rhymes AI开源图生视频模型Allegro-TI2V:根据用户提供的提示和图像生成视频Rhymes AI之前开源了视频生成模型Allegro,近期它们又推出了Allegro-TI2V。作为原始Allegro模型的迭代,Allegro-TI2V提供了前所未有的能力,将文本描述和图像转化为...视频模型# Allegro-TI2V# Rhymes AI10个月前02960
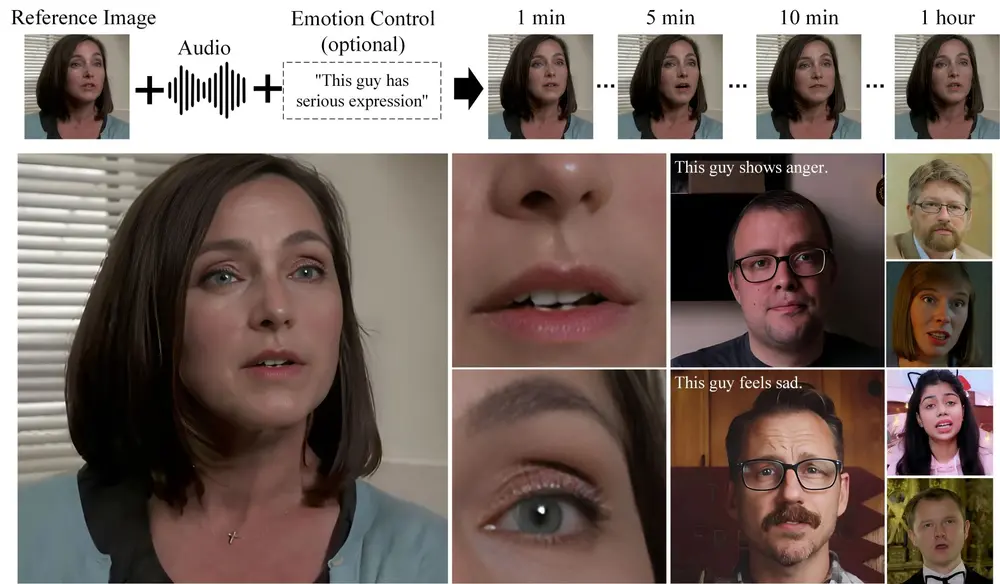
半身人体动画生成框架 EchoMimicV2:利用参考图像、音频剪辑和一系列手部姿势来生成高质量的动画视频随着计算机图形学和人工智能的发展,生成高质量的人类动画变得越来越重要。特别是,当涉及到创建生动、自然的动画时,音频、姿势或运动图等条件的引入大大提升了动画的真实性和表现力。然而,这些增强的方法也带来了...视频模型# EchoMimicV2# 动画生成10个月前04390
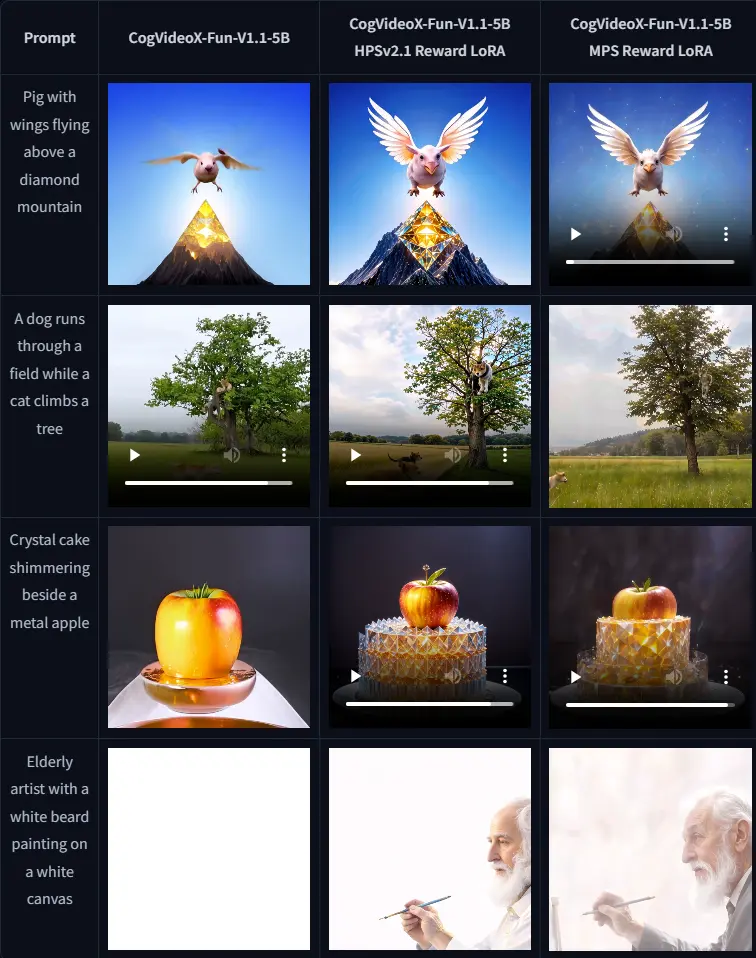
CogVideoX-Fun-V1.1-Reward-LoRAs:通过奖励反向传播技术训练Lora,以优化CogVideoX-Fun-V1.1生成的视频CogVideoX-Fun-V1.1-Reward-LoRAs是通过奖励反向传播技术训练Lora,以优化CogVideoX-Fun-V1.1生成的视频,使其更好地与人类偏好保持一致。 地址:https...视频模型# CogVideoX-Fun-V1.1# CogVideoX-Fun-V1.1-Reward-LoRAs10个月前03380
智谱AI推出CogVideoX 开源模型的升级版本CogVideoX1.5-5B智谱技术团队对于旗下开源视频生成模型CogVideoX进行了升级,今天释出了CogVideoX1.5-5B 系列模型,相比于原有模型,CogVideoX v1.5 将包含 5/10 秒、768P、16...视频模型# CogVideoX1.5-5B# 智谱AI# 智谱清影10个月前06170
挚文集团推出HelloMeme:用于生成表情包视频挚文集团推出HelloMeme,它通过在文本到图像的基础模型中集成空间编织注意力(Spatial Knitting Attentions, SK Attentions)来嵌入高水平和高保真度的条件,以...视频模型# HelloMeme# 表情包视频10个月前04180
Genmo推出开源视频生成模型天花板Mochi 1,型需 4 块英伟达H100 显卡才可运行Genmo是一家专注于视频生成的AI初创公司,之前都是默默无闻,其官方视频生成产品也是半死不活,但他们在昨天突然放大招开源了一款视频生成模型Mochi 1,号称其性能可与领先的闭源/专有竞争对手(如R...视频模型# Genmo# Mochi 1# 视频生成模型10个月前04890
Rhymes AI开源视频生成模型Allegro:从简单的文本提示生成高质量的 6 秒视频Rhymes AI在推出多模态原生模型Aria后,又在昨天开源了视频生成模型Allegro,Allegro 使用户能够从简单的文本提示生成高质量的 6 秒视频,帧率为 15 帧每秒,分辨率为 720P...视频模型# Allegro# Rhymes AI# 视频生成模型10个月前04370
肖像图像动画Hallo2:用于制作高分辨率、长时间的人像动画基于潜在扩散的生成模型在肖像图像动画方面取得了显著进展,特别是在短时视频合成方面。例如,Hallo 模型已经展示了令人印象深刻的结果。然而,这些模型在生成长时间视频时面临外观漂移和时间伪影等问题。为了...视频模型# Hallo2# 肖像图像10个月前04210
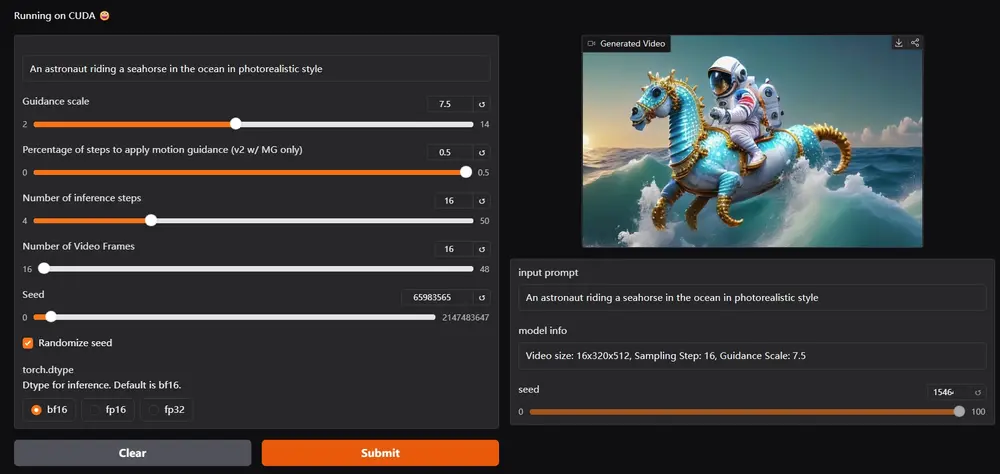
新型视频生成模型Pyramidal Flow:提高视频生成的效率,同时保持生成视频的高质量北京大学、快手科技和北京邮电大学的研究人员推出新型视频生成模型Pyramidal Flow,这个模型的目的是提高视频生成的效率,同时保持生成视频的高质量。可以想象一下,你想制作一个视频,里面有一只小猫...视频模型# Pyramidal Flow# 视频生成模型10个月前04790
新型视频生成模型T2V-Turbo-v2:基于VideoCrafter2模型提炼,提升视频生成的质量和效率加州大学圣巴巴拉分校、加州大学洛杉矶分校、亚马逊 AGI和滑铁卢大学的研究人员推出新型视频生成模型T2V-Turbo-v2,它旨在提升基于扩散的文本到视频(T2V)生成的质量和效率。简单来说,这项技术...视频模型# T2V-Turbo-v2# 视频生成模型10个月前07360
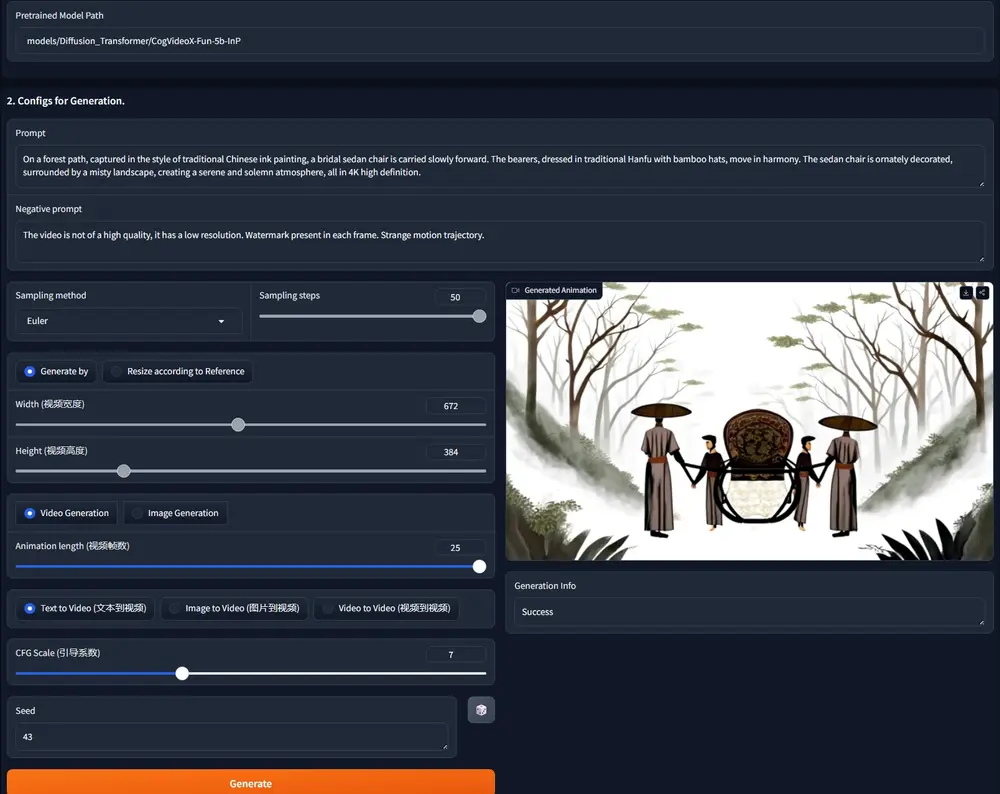
CogVideoX-Fun:基于CogVideoX结构修改后模型CogVideoX-Fun是一个基于CogVideoX结构修改后的的pipeline,是一个生成条件更自由的CogVideoX,可用于生成AI图片与视频、训练Diffusion Transformer...视频模型10个月前03770