基于Transformer架构的新型图像生成模型DART:根据文本描述生成高质量的图像苹果和香港中文大学的研究人员推出新型图像生成模型DART,这个模型的目标是让计算机能够根据文本描述生成高质量的图像。DART是一个基于Transformer架构的模型,它在非马尔可夫框架内统一了自回归...新技术# DART# Transformer架构# 图像生成模型1年前06760
BroadWay:提升文生视频模型的质量,而且不需要额外的训练上海交通大学、中国科学技术大学、香港中文大学和上海人工智能实验室的研究人员推出为BroadWay,它能够提升文生视频模型的质量,而且不需要额外的训练。这就像是给视频生成模型安装了一个“涡轮增压器”,让...新技术# BroadWay# 文生视频模型1年前07550
视频插值方法ViBiDSampler:专门用于在两个关键帧之间生成平滑且逼真的中间帧,从而创建流畅的视频过渡效果韩国科学技术研究院推出视频插值方法ViBiDSampler,这种方法专门用于在两个关键帧之间生成平滑且逼真的中间帧,从而创建流畅的视频过渡效果。ViBiDSampler引入了一种新颖的双向采样策略,以...新技术# ViBiDSampler# 视频插值方法1年前04220
一种在推理阶段组合定制扩散模型的新方法TweedieMix:用于改进多概念融合在基于扩散的图像和视频生成中的应用KRAFTON和韩国科学技术研究院AI研究生院的研究人员推出一种在推理阶段组合定制扩散模型的新方法TweedieMix,它用于改进多概念融合在基于扩散的图像和视频生成中的应用。简单来说,Tweedie...新技术# TweedieMix# 扩散模型1年前04720
字节推出TextToon:在实时环境中将真人的头像转换成卡通化的形象罗切斯特大学和字节跳动的研究人员推出TextToon,它能够在实时环境中将真人的头像转换成卡通化的形象。就像魔法一样,这项技术可以把你从视频中的头像变成你想要的任何卡通风格,比如美国漫画风格、皮克斯动...新技术# TextToon# 字节跳动1年前05720
新型视频生成框架VideoGuide:改善视频生成模型在时间连续性方面的性能,同时保持甚至提高生成视频的图像质量韩国科学技术研究院推出新型框架VideoGuide,它能够改善视频生成模型在时间连续性方面的性能,同时保持甚至提高生成视频的图像质量。这就意味着,使用VideoGuide,可以让现有的视频生成模型在不...新技术# VideoGuide# 视频生成框架1年前04030
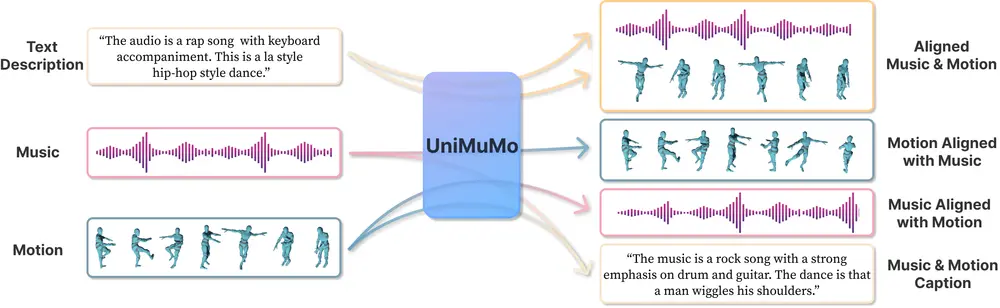
多模态统一模型UniMuMo:能够处理文本、音乐和动作(运动)数据,并在这三种模式之间生成内容香港中文大学、华盛顿大学、不列颠哥伦比亚大学、麻省大学阿默斯特分校、 MIT-IBM Watson AI 实验室和思科研究院的研究人员推出多模态统一模型UniMuMo,它能够处理文本、音乐和动作(运动...新技术# UniMuMo# 多模态统一模型1年前04900
图像生成框架OmniBooth:根据用户的多模态指令(如文本提示或图像参考)来生成具有空间控制和实例级定制化的图像香港科技大学和华为诺亚方舟实验室的研究人员推出图像生成框架OmniBooth,它可以根据用户的多模态指令(如文本提示或图像参考)来生成具有空间控制和实例级定制化的图像。简单来说,用户可以指定多个对象的...新技术# OmniBooth# 图像生成框架1年前05420
半策略偏好优化方法SePPO:用于优化和微调文生图模型,使其更好地符合人类的审美和偏好罗切斯特大学、普渡大学、延世大学、腾讯 AI 实验室和华盛顿大学的研究人员推出半策略偏好优化方法SePPO,用于优化和微调扩散模型(如用于生成图像的模型),使其更好地符合人类的审美和偏好,而无需依赖外...新技术# SePPO# 半策略偏好优化# 文生图模型1年前04550
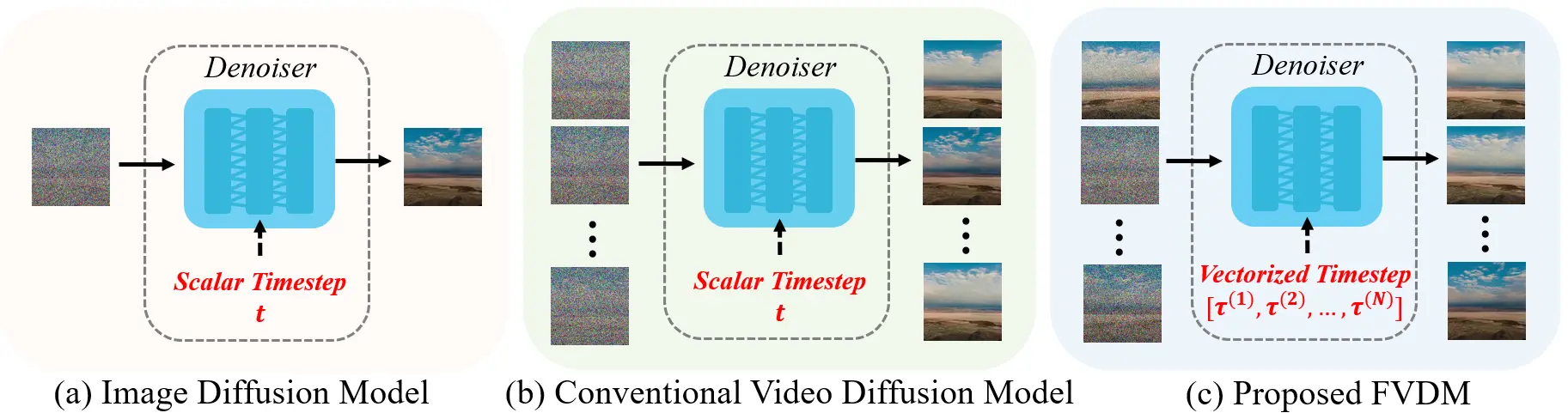
帧感知视频扩散模型FVDM:时间步向量化方法,提高了视频生成任务的质量和灵活性香港城市大学、大湾区大学、国防科技大学、香港中文大学和岭南大学的研究人员推出了一种新的视频扩散模型,称为帧感知视频扩散模型(Frame-Aware Video Diffusion Model,简称FV...新技术# FVDM# 帧感知视频扩散模型1年前04860
新型图像生成框架ControlAR:根据空间控制信息生成可控制的高质量图像华中科技大学信息与通信学院、香港大学计算机科学系和vivo AI 实验室的研究人员推出新型图像生成框架ControlAR,它能够根据空间控制信息生成可控制的高质量图像。简单来说,ControlAR能够...新技术# ControlAR# 图像生成框架1年前05310
新型端到端模型DnD-Transformer:提高了图像生成任务的质量和效率,为图像生成领域带来了新的可能北京大学、阿里巴巴集团、威斯康星大学麦迪逊分校和北京理工大学的研究人员推出新型端到端模型DnD-Transformer,这是一种用于高效细粒度图像生成的二维自回归Transformer。简单来说,这个...新技术# DnD-Transformer# 图像生成1年前04680