SSAM 2增强版SAMURAI:专门设计用于视觉物体跟踪Segment Anything Model 2 (SAM 2) 是一个在物体分割任务中表现出色的模型,但在视觉物体跟踪方面仍面临一些挑战。特别是在处理拥挤场景中快速移动或自我遮挡的物体时,SAM 2...新技术# SAMURAI# SSAM 21年前06220
SageAttention2:适用于即插即用推理加速的精确4位注意力机制尽管线性层的量化技术已经广泛应用于深度学习模型中,但在加速注意力机制方面的应用仍然有限。为了提高注意力计算的效率并保持高精度,清华大学的研究团队提出了 SageAttention2,这是一个基于低精度...新技术# SageAttention2# 推理加速1年前03130
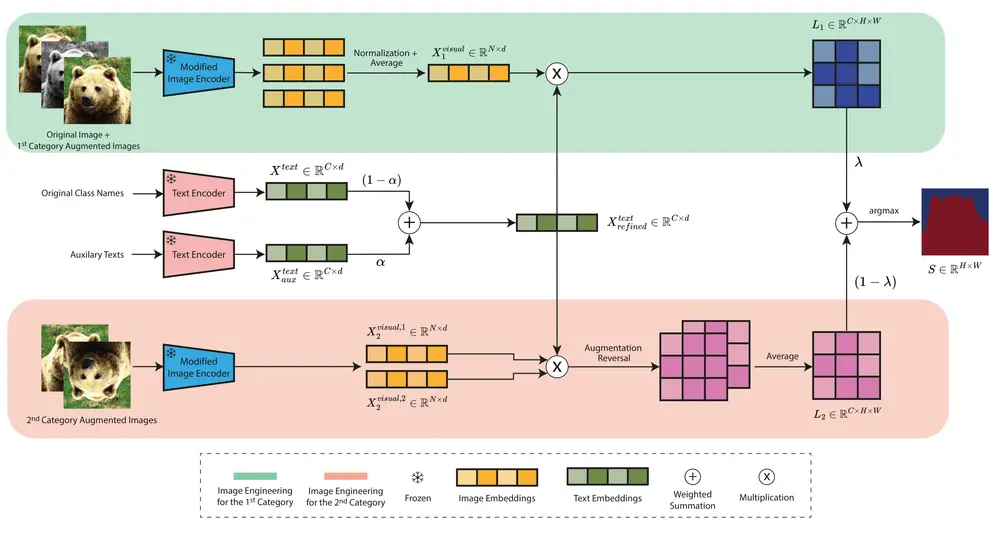
ITACLIP:通过图像、文本和架构增强提升无需训练的语义分割近年来,基础视觉语言模型(VLMs)的发展彻底改变了计算机视觉领域的研究方向。这些模型,尤其是 CLIP,不仅推动了开放词汇计算机视觉任务的研究,还在多个领域取得了显著成果。然而,尽管 VLMs 在开...新技术# ITACLIP# 语义分割1年前03840
CSpD:用于加速自回归图像生成模型的推理过程中国科学院大学、中国科学院自动化研究所和中国铁塔的研究人员介绍了一种名为“Continuous Speculative Decoding”(CSpD)的技术,用于加速自回归(Autoregressiv...新技术# CSpD# 推理加速1年前03080
新型推理加速技术SmoothCache:提高DiT模型在不同模态(如图像、视频和语音合成)任务中的推理效率DiT架构因其强大的生成能力而在图像、视频和语音合成等多个领域展现出巨大潜力。然而,由于在推理过程中需要反复评估计算密集型的注意力和前馈模块,DiT架构的计算成本较高,这成为其广泛应用的一大障碍。为了...新技术# SmoothCache# 推理加速1年前02870
视频编辑方法STABLEV2V:解决视频编辑中形状一致性问题中国科学技术大学的研究人员推出视频编辑方法STABLEV2V,旨在解决视频编辑中形状一致性问题。STABLEV2V通过一系列顺序过程来编辑视频:首先编辑第一帧视频,然后建立交付动作与用户提示之间的对齐...新技术# STABLEV2V# 视频编辑1年前05540
新型虚拟试穿技术FitDiT:专为优化DiT模型的虚拟试穿性能而设计尽管基于图像的虚拟试穿技术已取得显著进展,但在生成高保真度和适应性强的拟合图像上仍面临诸多挑战。尤其在纹理感知维护和尺寸感知拟合等关键领域,现有方法往往难以达到理想效果,这限制了技术的整体实用性。为应...新技术# FitDiT# 虚拟试穿12个月前03620
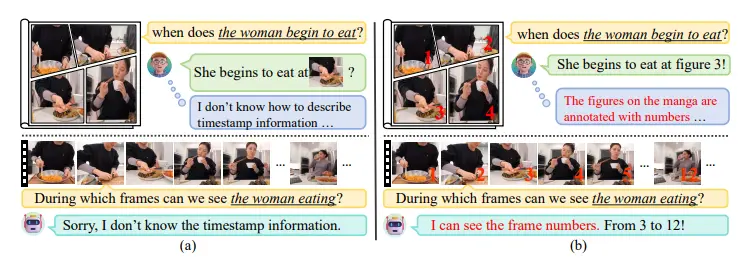
NumPro:增强视频大语言模型在视频时间定位任务中的表现东南大学、马克斯普朗克信息学研究所、腾讯微信和加州大学伯克利分校的研究人员推出了一个名为Number-Prompt(NumPro)的方法,它旨在增强视频大语言模型(Vid-LLMs)在视频时间定位(V...新技术# NumPro# 视频大语言模型1年前02820
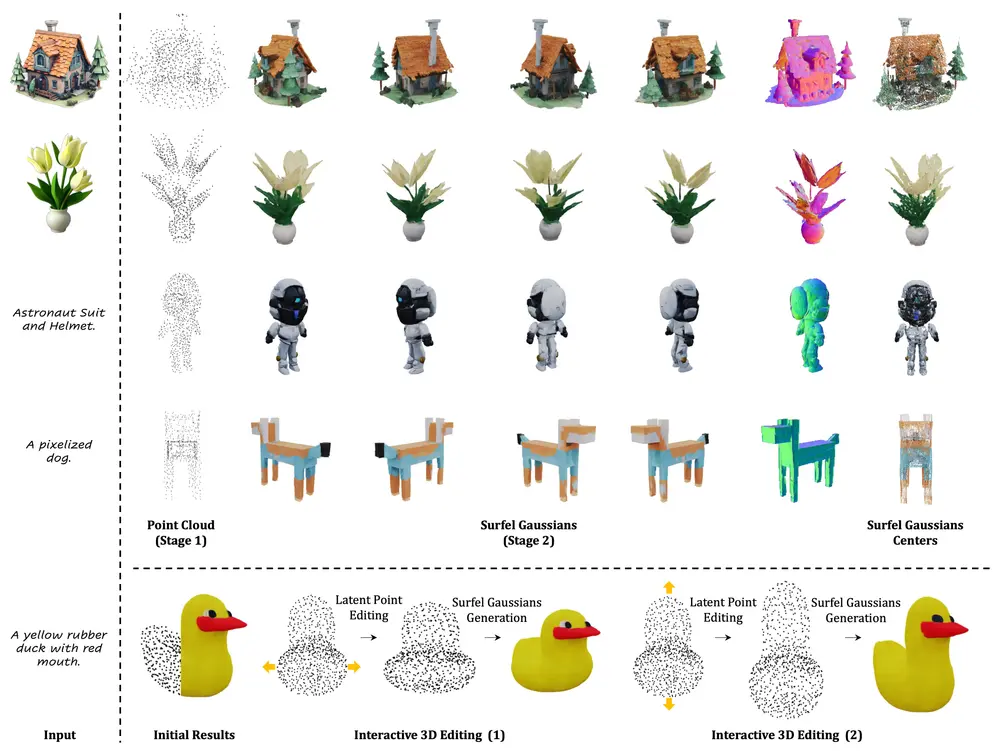
新型3D生成框架GaussianAnything:根据单视图图像或文本条件生成高质量且可编辑的3D模型新加坡南洋理工大学、上海人工智能实验室和北京大学的研究人员推出新型3D生成框架GaussianAnything,它能够根据单视图图像或文本条件生成高质量且可编辑的3D模型。这个框架通过一个级联的3D扩...新技术# 3D生成框架# GaussianAnything1年前02890
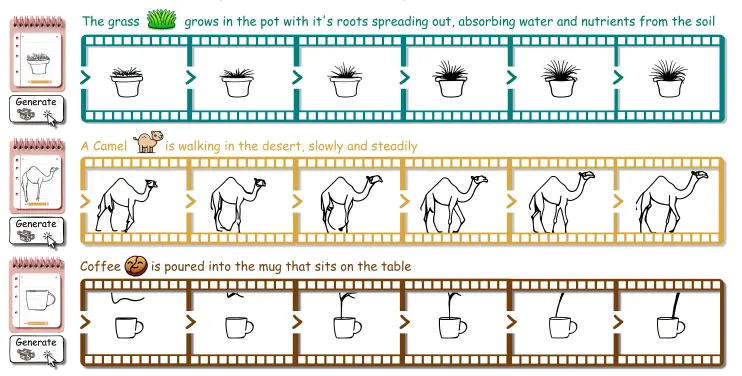
FlipSketch:将静态绘图转换为文本引导的草图动画草图动画作为一种强大的视觉叙事工具,从简单的手工翻页涂鸦发展到了专业的工作室制作,为创作者提供了无限的想象空间。然而,传统的动画制作过程复杂,不仅需要一支熟练的艺术家团队来绘制关键帧和中间帧,还要求艺...新技术# FlipSketch# 草图动画1年前03670
统一的控制视频生成方法AnimateAnything:实现对视频内容的精确和一致性的操控,包括相机轨迹、文本提示和用户运动注释等多种条件视频生成是一个复杂而多样的任务,涉及多个条件的控制,如摄像机轨迹、文本提示和用户运动注释。现有的方法通常只能在特定条件下生成视频,缺乏灵活性和一致性。为了解决这些问题,浙江大学 CAD&CG ...新技术# AnimateAnything# 视频生成1年前03480
RF-Solver和RF-Edit:提高校正流模型在图像和视频编辑中的反演精度基于校正流的DiT模型,如FLUX和OpenSora,在图像和视频生成领域展示了卓越的性能。然而,这些模型在反演过程中存在不准确的问题,这限制了它们在图像和视频编辑等下游任务中的有效性。为了解决这一问...新技术# RF-Edit# RF-Solver1年前04850