NXN Labs推出新型虚拟试穿框架Voost:通过一个统一的扩散变换器同时实现虚拟试穿(试穿目标服装)和虚拟试脱(从人像中重建原始服装)功能NXN Labs推出新型虚拟试穿框架Voost,通过一个统一的扩散变换器(Diffusion Transformer)同时实现虚拟试穿(试穿目标服装)和虚拟试脱(从人像中重建原始服装)功能。 项目主页...新技术# Voost# 虚拟试穿7个月前03430
长上下文调优训练范式LCT:通过将预训练的单镜头视频扩散模型扩展到场景级视频生成,以生成具有视觉和动态一致性的多镜头视频内容香港中文大学和字节跳动的研究人员提出了一种名为 Long Context Tuning(LCT,长上下文调优)的训练范式,通过将预训练的单镜头视频扩散模型扩展到场景级视频生成,以生成具有视觉和动态一致...新技术# LCT# 训练范式# 长上下文调优1年前03430
西湖大学推出一款具备自我进化能力的 GUI 代理AppAgentX西湖大学 AGI 实验室张驰团队近日推出一款具备自我进化能力的 GUI 代理——AppAgentX,它能够在持续执行任务的过程中不断学习并优化自身行为模式,从而实现更高效的操作,为自动化任务执行带来了...新技术# AI智能体# AppAgentX# GUI 代理1年前03430
个性化面部老化方法MyTimeMachine:根据个人特定的照片集合来训练一个个性化的年龄转换模型,实现从儿童到老年的个性化面部年龄变化面部老化是一个复杂的过程,受到多种因素的影响,如性别、种族、生活方式等。尽管现有的面部老化技术能够生成逼真的老化图像,但它们通常无法准确预测特定个体的老化过程,因为这些技术缺乏个性化处理。为了克服这一...新技术# MyTimeMachine# 年龄# 面部老化1年前03430
基于预训练流模型的新型文本驱动图像编辑方法FlowEdit:适用于SD3和Flux模型使用预训练的文本到图像(T2I)扩散或流模型编辑真实图像是一项具有挑战性的任务。传统的方法通常涉及将目标图像反转为对应的噪声图,然后根据新的文本提示重新生成图像。然而,仅靠反转变换往往无法获得满意的结...新技术# FlowEdit# 图像编辑1年前03420
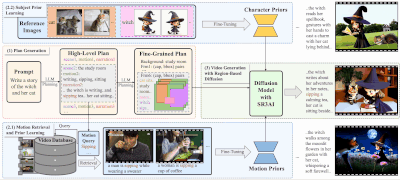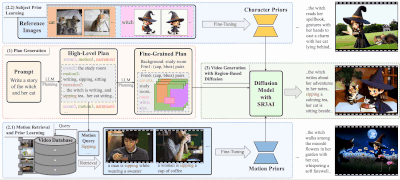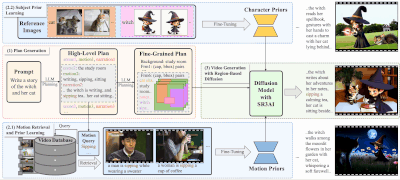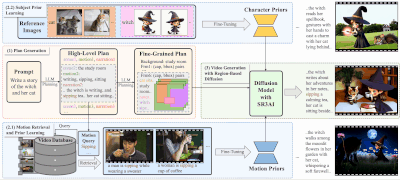
新型故事视频生成框架DreamRunner:根据文本脚本生成长篇、多动作、多场景的视频,适用于CogVideoX模型故事讲述视频生成(SVG)是一项旨在从文本脚本创建长时间、多动作、多场景视频的任务。这种技术在媒体和娱乐领域的内容创作中具有巨大潜力,但同时也面临着诸多挑战,包括但不限于: 物体需要展示一系列精细、复...新技术# DreamRunner# 视频生成1年前03420
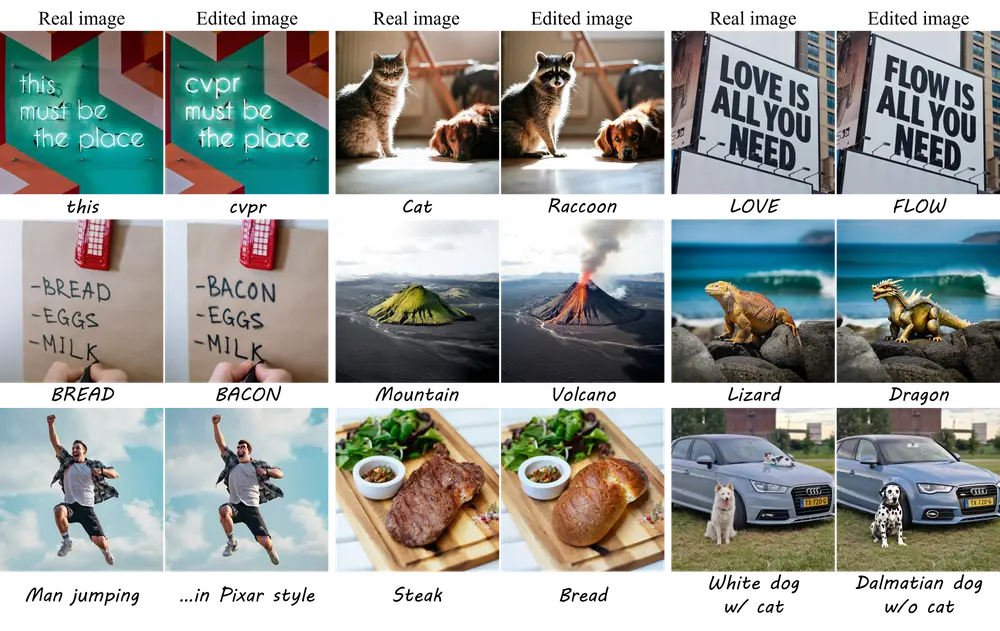
X-Planner:基于 MLLM 的图像编辑任务规划系统,让复杂指令也能精准执行在图像编辑领域,用户常常需要执行诸如“将这张照片转换为赛博朋克风格”或“让图中的动物看起来像是在庆祝圣诞节”这样的复杂操作。这些任务不仅要求模型理解抽象指令,还需准确定位并修改图像中的特定区域。 然而...新技术# X-Planner# 图像编辑8个月前03410
零样本多实例视频编辑框架MIVE:能够对视频中的多个独立对象进行精确编辑,而不影响视频中的其他部分近年来,基于人工智能的视频编辑技术取得了显著进展,用户可以通过简单的文本提示轻松编辑视频。然而,现有的零样本视频编辑方法主要集中在全局或单一对象的编辑上,这可能导致视频其他部分发生意外变化。当需要对多...新技术# MIVE# 视频编辑1年前03410
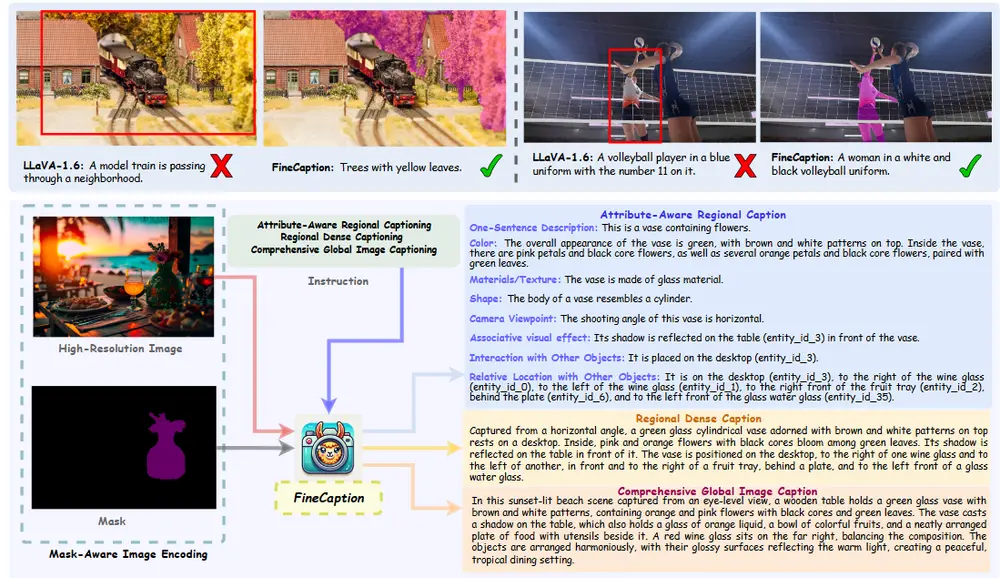
视觉-语言模型FINECAPTION:专注于在任意位置和任意粒度级别上进行组合式图像描述随着大型视觉语言模型(VLMs)的出现,多模态任务的发展取得了显著进展。这些模型在图像和视频字幕、视觉问答以及跨模态检索等应用中展现了强大的推理能力。然而,尽管VLMs具有卓越的表现,它们在细粒度图像...新技术# FINECAPTION# 视觉-语言模型1年前03410
新型虚拟试穿方法MN-VTON:通过单个生成网络实现高质量的虚拟试穿效果,挑战了当前依赖双网络范式的主流方法虚拟试穿(VTON)作为电子商务领域的一项关键技术,能够帮助消费者真实地预览服装在自己身上的效果。然而,早期的VTON技术受限于单一生成网络,在保留细粒度的服装细节方面存在不足。为了解决这个问题,研究...新技术# MN-VTON# 虚拟试衣1年前03400
任务偏好优化TPO:通过视觉任务对齐来提升多模态大语言模型的性能上海人工智能实验室、浙江大学、中国科学技术大学、上海交通大学、中国科学院深圳先进技术研究院和南京大学的研究人员推出一种名为任务偏好优化(Task Preference Optimization, TP...新技术# TPO# 任务偏好优化# 多模态大语言模型1年前03400
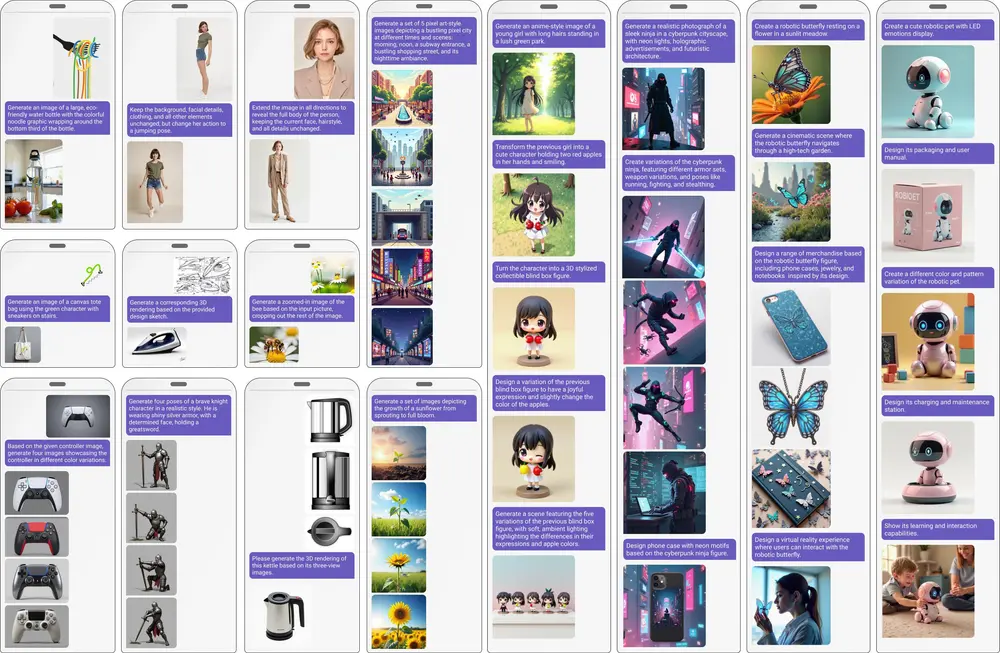
阿里通义实验室推出一个零样本、通用且交互式的视觉生成框架ChatDiT:允许用户通过自由形式的自然语言指令与系统交互,创建交织文本-图像文章、多页画册、编辑图像近年来,预训练扩散Transformer(DiTs)在上下文生成能力方面展现了巨大的潜力,能够以最小的架构修改或无需修改的情况下无缝适应多样化的视觉任务。这些能力通过跨多个输入和目标图像的自注意力令牌...新技术# ChatDiT# 视觉生成框架1年前03400