基于 SEED-X 的新型多模态大语言模型SEED-Story:根据用户提供的文本和图片生成长篇的图文故事香港科技大学(广州)、腾讯、香港中文大学和香港科技大学的研究人员推出新型多模态大语言模型SEED-Story,它能够根据用户提供的文本和图片生成长篇的多模态故事。这些故事不仅包含丰富的叙事文本,还包括...新技术# SEED-Story# 图文故事# 多模态大语言模型2年前01,1480
新型图像到3D框架Unique3D:从单视图图像高效生成高质量的3D网格模型清华大学和AVAR的研究人员推出新型图像到3D框架Unique3D,它能够从单视图图像高效生成高质量的3D网格模型。Unique3D的核心优势在于它能够在短时间内生成高保真度、细节丰富且具有强泛化能力...新技术# 3D网格模型# Unique3D2年前01,1350
新型实时端到端目标检测系统YOLOv10:快速地识别图像中的多个对象,并且告诉用户这些对象的具体位置清华大学的研究人员推出新型实时端到端目标检测系统YOLOv10,目标检测是计算机视觉领域的一个重要任务,它的目的是识别出图像中的对象,并确定它们的位置。例如,你在玩一个视频游戏,需要快速识别并射击屏幕...新技术# YOLOv10# 清华大学# 目标检测2年前01,1320
基于大语言模型的新型文本编码器LI-DiT:灵活地将尖端的大语言模型融入文本转图像生成模型商汤研究院、香港中文大学移动计算实验室和上海人工智能实验室的研究人员推出新型文本编码器LI-DiT(LLM-Infused Diffusion Transformer),旨在充分发挥大语言模型的潜力...新技术# LI-DiT# 文本编码器2年前01,1290
索尼推出音频-视觉生成模型Visual Echoes:根据一张图片生成与之相对应的音频,或者反过来,根据一段音频生成匹配的图片索尼推出新型音频-视觉生成模型Visual Echoes,这个模型能够根据一张图片生成与之相对应的音频,或者反过来,根据一段音频生成匹配的图片。这种技术在多模态生成领域具有很大的潜力,因为它能够将视觉...新技术# Visual Echoes# 音频-视觉生成模型2年前01,1220
新型视图合成技术InstantSplat:在极短的时间内(大约40秒)从稀疏的、没有相机姿态信息的图像中重建和渲染出新视角的3D场景来自德克萨斯大学奥斯汀分校、英伟达、厦门大学、佐治亚理工学院、斯坦福大学和南加州大学推出新型视图合成技术InstantSplat,它能够在极短的时间内(大约40秒)从稀疏的、没有相机姿态信息的图像中重...新技术# 3D场景# InstantSplat2年前01,0980
影眸科技推出新型大型3D生成模型CLAY:帮助人们将脑海中的创意轻松转化为精细的三维数字结构上海科技大学、影眸科技和华中科技大学的研究人员推出新型大型3D生成模型CLAY,它的主要任务是帮助人们将脑海中的创意轻松转化为精细的三维数字结构。就像孩子们用黏土塑造出各种形状的物体一样,CLAY能够...新技术# 3D生成模型# CLAY# 影眸科技2年前01,0940
attribute-control:对文生图模型生成的图像中的特定属性进行精细控制来自慕尼黑工业大学的研究人员推出attribute-control,它能够对文本到图像(T2I)模型生成的图像中的特定属性进行精细控制。 项目主页 GitHub Demo 开发团队发现,在常用的基于t...新技术# attribute-control# 文生图模型# 精细控制2年前01,0900
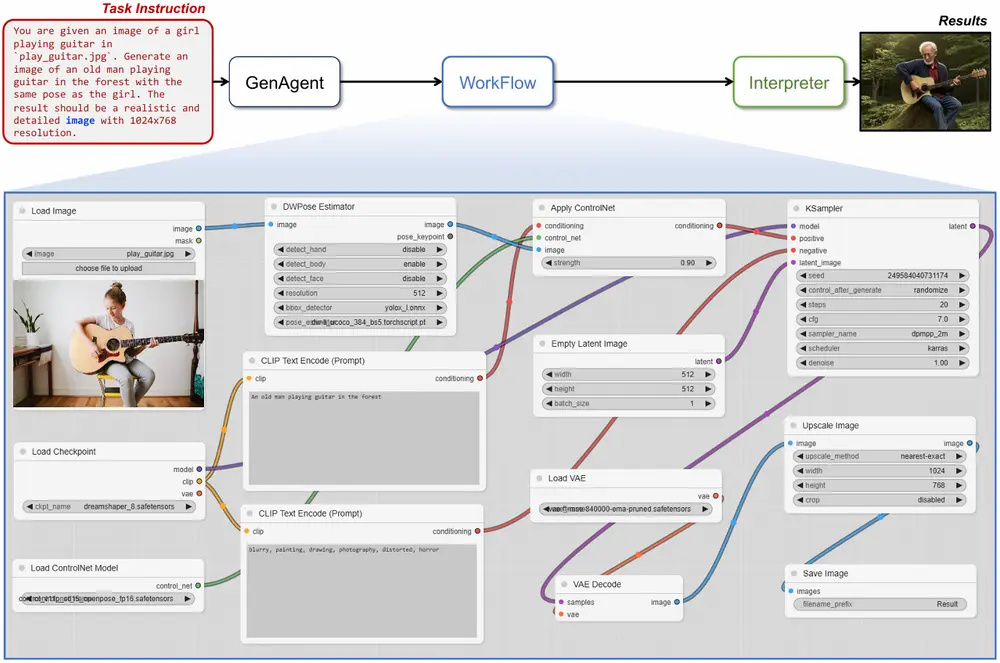
基于大语言模型的框架GenAgent:用于自动生成复杂的工作流程,以构建协作式人工智能系统上海人工智能实验室推出一个基于大语言模型的框架GenAgent,用于自动生成复杂的工作流程,以构建协作式人工智能(AI)系统,相比单一的大型模型,GenAgent提供了更大的灵活性和可扩展性。这种系统...新技术# GenAgent2年前01,0800
实时渲染技术Octree-GS:用于实时渲染三维场景,特别适用于处理大型和复杂场景来自上海人工智能实验室、同济大学、中国科学技术大学和香港中文大学的研究团队推出Octree-GS(八叉树-高斯球体),这是一种用于实时渲染三维场景的方法,特别适用于处理大型和复杂场景。 项目主页 Gi...新技术# Octree-GS# 三维场景# 实时渲染2年前01,0800
基于人类与场景互动数据集Trumans开发的动作生成模型来自北京大学人工智能研究院、BIGAI通用人工智能国家重点实验室、北京大学CFCS计算机学院和北京理工大学的研究团队创建一个详细的人类与场景互动数据集trumans,并开发出一种先进的动作生成模型,为...新技术# Trumans# 动作生成模型2年前01,0530
高效灵活的对象检测工具YOLO-World来自腾讯AI实验室、华中科技大学EIC学院的研究人员推出高效实时开放词汇对象检测框架YOLO-World,旨在通过视觉语言模型和大规模数据集的预训练,增强YOLO(You Only Look Once...新技术# YOLO-World# 对象检测工具# 腾讯AI实验室2年前01,0520