阿里通义实验室开源 Fun-CineForge:首个影视级多场景 AI 配音大模型,攻克“音画同步”与“多人对话”难题在 AI 语音合成(TTS)日益普及的今天,将其应用于专业影视制作仍面临巨大挑战:口型对不上、情感不到位、多人对话混乱、画面遮挡时声音消失…… 阿里通义实验室正式宣布开源 Fun-CineForge ...语音模型# Fun-CineForge# 通义实验室# 配音大模型2周前0230
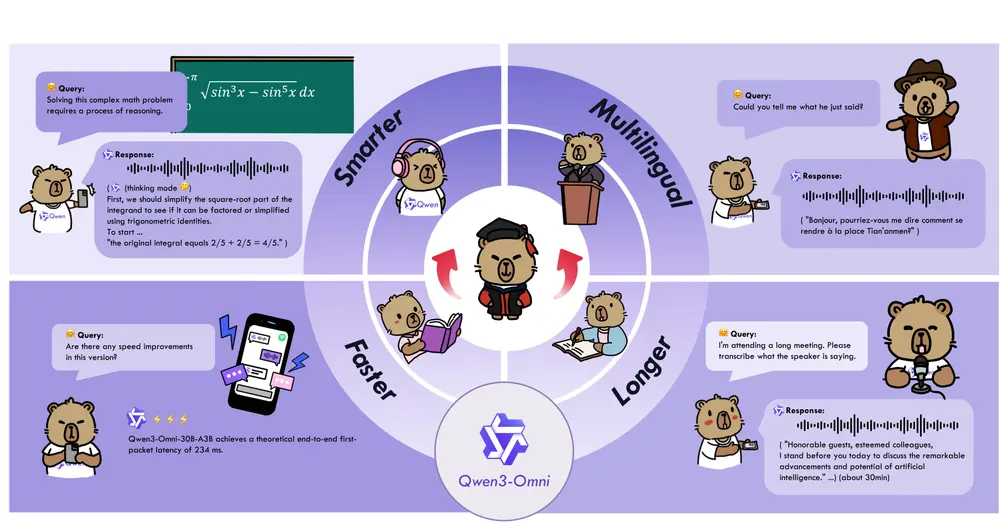
阿里通义实验室推出Qwen3-Omni:支持文本、语音、图像、视频的全模态大模型通义实验室正式推出 Qwen3-Omni——一款统一处理多模态输入并支持流式文本与语音输出的大语言模型。该模型已在 Qwen API 平台上线,开发者可通过接口体验其在音频对话、跨模态理解与指令执行方...多模态模型# Qwen3-Omni# 通义实验室6个月前02270
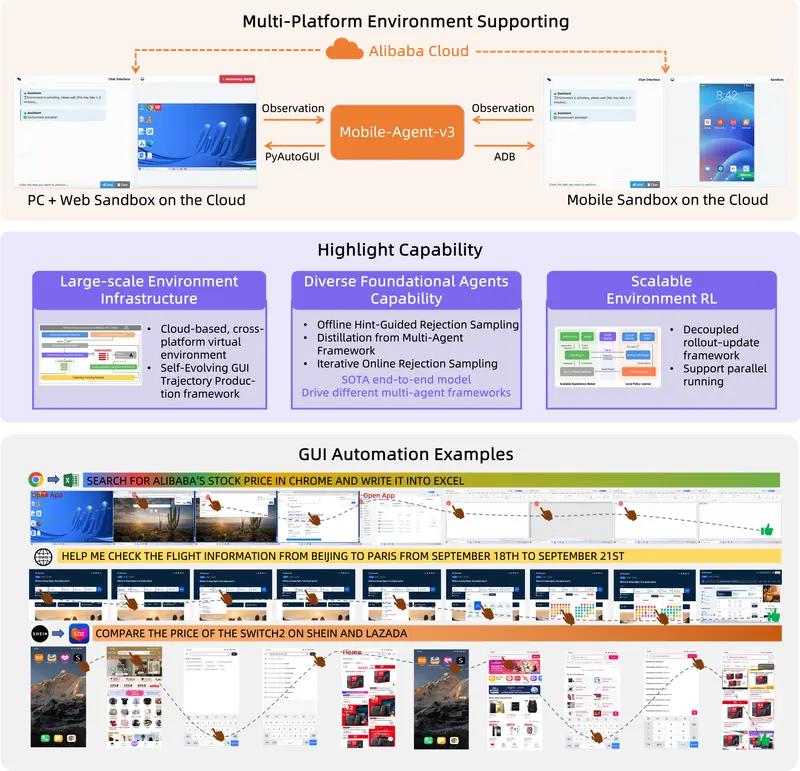
阿里通义实验室推出 Mobile-Agent-v3 框架:为图形用户界面(GUI)任务的自动化带来了全新的解决方案在当今数字化时代,自动化技术的发展日新月异。阿里通义实验室作为行业内的创新先锋,于近期推出了令人瞩目的Mobile-Agent-v3框架,为图形用户界面(GUI)任务的自动化带来了全新的解决方案。 G...多模态模型# Mobile-Agent-v3# 图形用户界面# 通义实验室7个月前01,1020
阿里发布 Qwen3-4B 双模型:小参数,大能力,原生支持 256K 上下文在大模型“军备竞赛”愈演愈烈的今天,阿里巴巴通义实验室反其道而行之,推出两款 40 亿参数级别 的小型语言模型: Qwen3-4B-Instruct-2507:面向多语言、高响应速度的通用指令模型 Q...大语言模型# Qwen3-4B-Instruct-2507# Qwen3-4B-Thinking-2507# 通义实验室8个月前04280
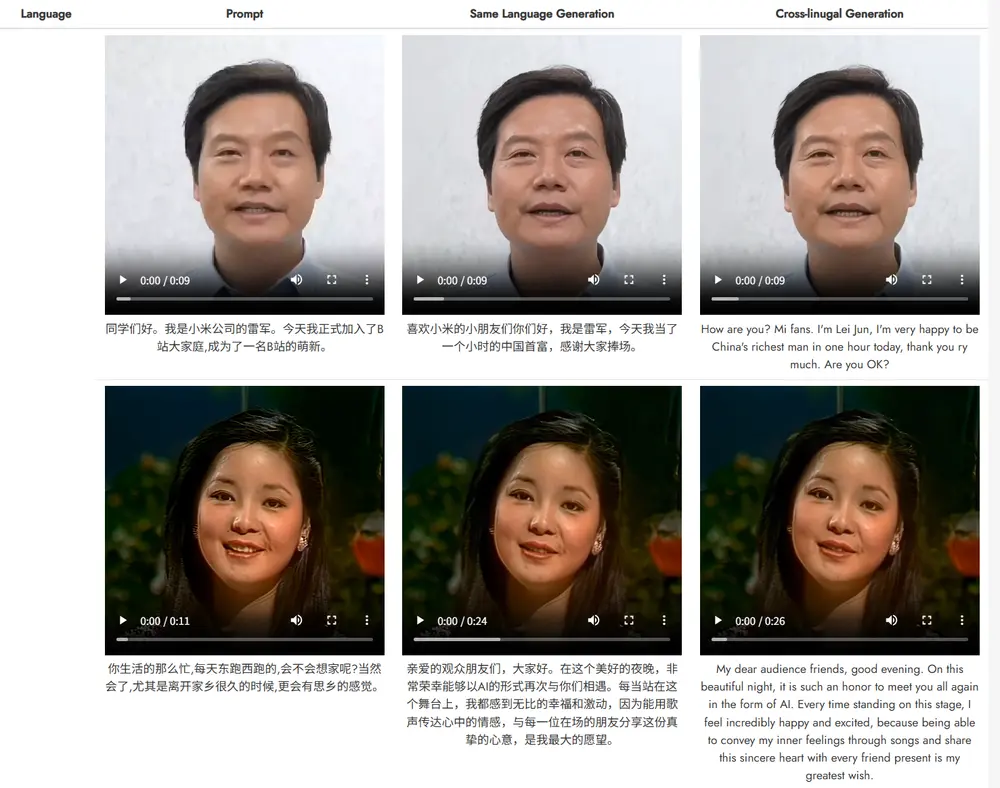
新型实时文本驱动的说话头像生成框架OmniTalker :在零样本场景下同时生成同步的语音和说话头像视频,同时保留语音风格和面部风格阿里通义实验室推出新型实时文本驱动的说话头像生成框架OmniTalker ,能够在零样本(zero-shot)场景下同时生成同步的语音和说话头像视频,同时保留语音风格和面部风格。OmniTalker ...新技术# OmniTalker# 通义实验室12个月前06560
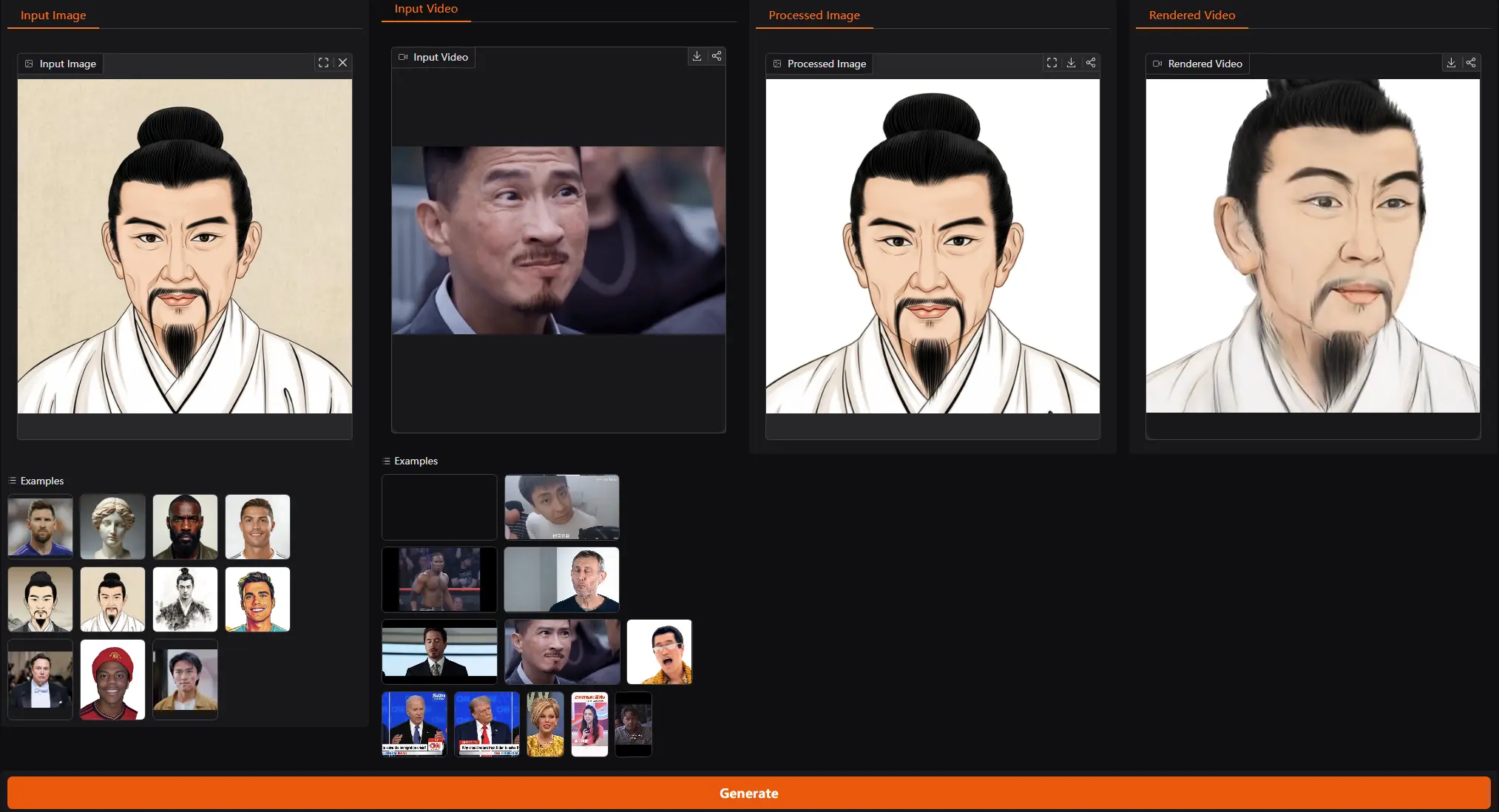
阿里巴巴通义实验室推出新型单次拍摄可动画化的高斯头部模型 LAM:能够从单张图像中生成可动画化且可渲染的高斯头像阿里巴巴通义实验室推出新型单次拍摄可动画化的高斯头部模型 LAM(Large Avatar Model),能够从单张图像中生成可动画化且可渲染的高斯头像。与以往需要大量视频序列训练或依赖辅助神经网络进...视频模型# LAM# 通义实验室# 高斯头像12个月前04670
阿里通义实验室 Wan 团队推出一体化视频编辑框架 VACE阿里通义实验室 Wan 团队近日推出了一款专为视频创建和编辑设计的一体化视频编辑框架——VACE。该框架集成了多种视频任务,包括参考到视频生成(R2V)、视频到视频编辑(V2V)和蒙版视频到视频编辑...视频模型# VACE# Wan# 通义实验室1年前05220
阿里通义实验室开源R1-Omni:用强化学习解锁全模态大模型的新潜力随着DeepSeek R1的发布,强化学习在大模型领域的潜力得到了进一步挖掘。Reinforcement Learning with Verifiable Reward(RLVR)方法为多模态任务提供...多模态模型# R1-Omni# 全模态大模型# 强化学习1年前02270
阿里巴巴通义实验室开源视频生成模型 Wan2.1在AI技术的浪潮中,视频生成技术正逐渐成为新的热点。阿里巴巴集团通义实验室紧跟技术前沿,于2月21日宣布开源其先进的视频生成模型——WanX 2.1。然而,在发布过程中出现了一个小插曲,模型名称由Wa...视频模型# AI视频# Wan2.1# WanX 2.11年前02530
阿里通义实验室推出高保真角色图像动画生成框架Animate Anyone 2阿里通义实验室推出高保真角色图像动画生成框架Animate Anyone 2,它不仅利用运动信号来驱动角色动画,还从驱动视频中提取环境表示,使角色动画能够与环境自然地融合。前代技术Animate An...新技术# Animate Anyone 2# 通义实验室1年前02620
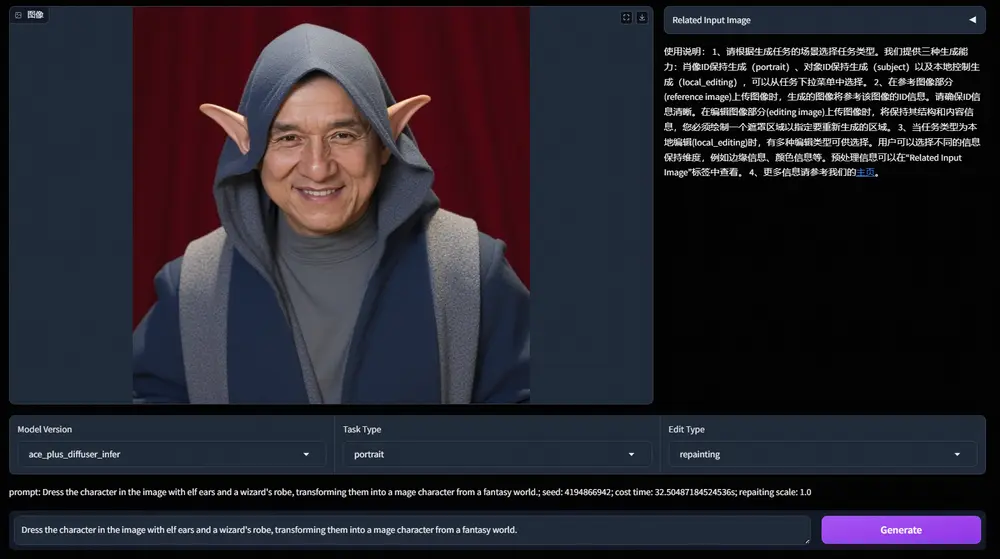
通义实验室推出基于指令的图像生成和编辑框架ACE++:基于FLUX.1-dev模型,实现多种图像生成和编辑任务阿里巴巴通义实验室推出基于指令的图像生成和编辑框架ACE++,这是之前介绍过的新型多模态生成模型ACE升级版,ACE++ 通过改进的长上下文条件单元(LCU++)和两阶段训练方案,能够高效地利用预训练...图像模型# ACE# FLUX.1-dev# 图像生成1年前03520