daVinci-MagiHuman:单流架构重塑音视频生成,1080p 仅需 38 秒的开源新标杆在 AI 生成内容(AIGC)领域,音视频联合生成一直被视为“皇冠上的明珠”。然而,现有的开源方案往往陷入两难:要么采用复杂的多流架构导致推理缓慢、难以优化,要么为了速度牺牲了人物表情与语音的自然度...视频模型# daVinci-MagiHuman# 视频生成7天前01200
UniVideo:滑铁卢大学与快手推出统一视频生成与编辑模型,支持理解、生成、编辑一体化长久以来,视频 AI 能力被割裂为多个独立任务: 理解:靠视觉语言模型(如 Qwen-VL) 生成:依赖扩散模型(如 Sora、HunyuanVideo) 编辑:需专门的编辑网络或掩码引导 这种碎片化...视频模型# UniVideo# 视频生成# 视频编辑3个月前0240
LTX-2 首日集成 ComfyUI,支持同步音视频生成与多模态控制开源音视频生成模型 LTX-2 已于发布当日集成至 ComfyUI 核心,成为首个在 ComfyUI 中获得原生支持的同步音视频基础模型。用户无需安装额外插件,即可直接调用其音画协同生成能力。 LTX...工作流# ComfyUI# LTX-2# 视频生成3个月前0550
ComfyUI-LTXVideo:扩展 LTX-2 视频生成能力的自定义节点集LTX-2 已正式集成至 ComfyUI 核心,所有用户均可直接ComfyUI官方节点和工作流。而 ComfyUI-LTXVideo(由 Lightrick 开发)则在此基础上,提供一套增强型自定义节...插件# ComfyUI-LTXVideo# LTX-2# 视频生成3个月前0840
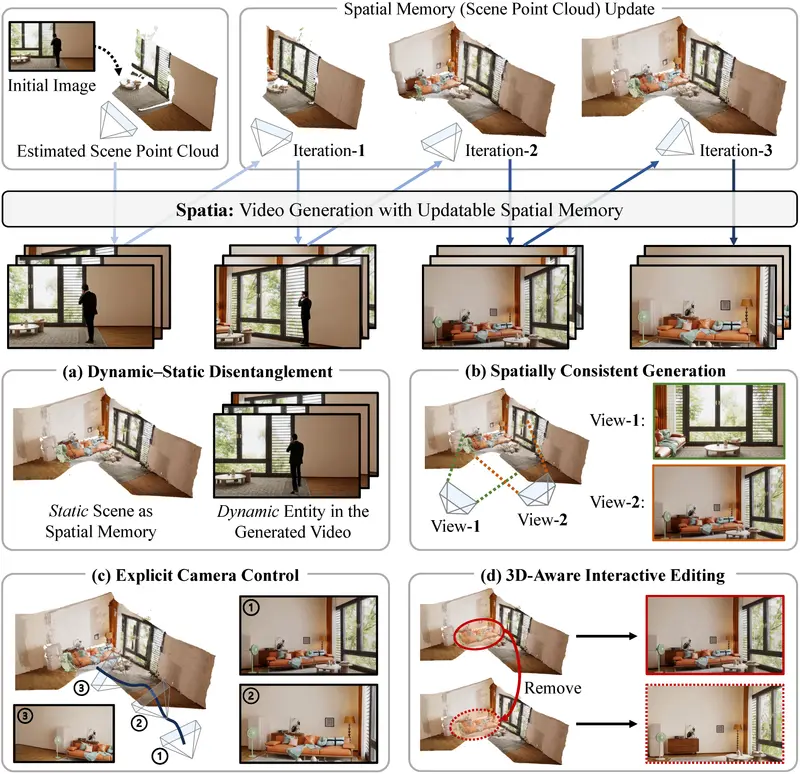
Spatia:基于可更新空间记忆的长期一致视频生成框架传统视频生成模型在生成长视频时,常因高维时空信号的复杂性而难以维持长期的空间与时间一致性——场景结构漂移、物体位置突变、相机运动不连贯等问题普遍存在。 项目主页:https://zhaojingjin...视频模型# Spatia# 视频生成3个月前0330
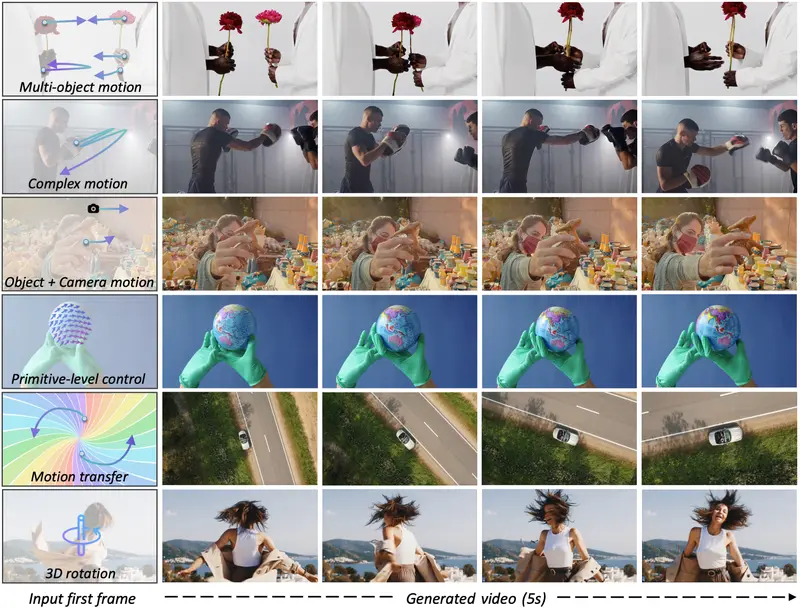
阿里通义联合多所高校推出 Wan-Move:无需额外模块,实现高精度动作控制的视频生成框架在视频生成领域,动作控制是连接静态图像与动态叙事的关键环节。然而,现有方法普遍存在两个瓶颈:一是控制粒度粗糙(如仅用边界框控制整体移动),二是依赖额外模型(如光流估计器),导致推理复杂、误差累积、难以...百科# Wan-Move# 动作控制# 视频生成4个月前0770
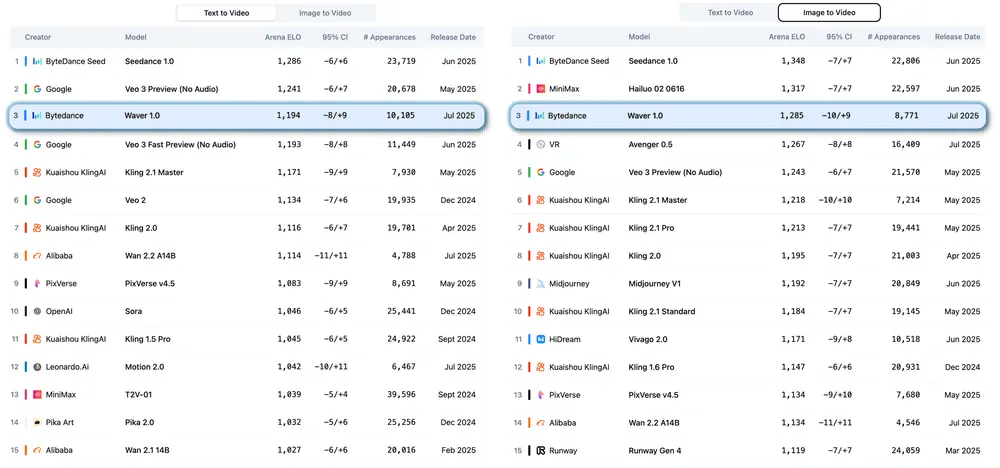
字节跳动 Waver 项目组推出一体化视频生成模型Waver 1.0:同时支持文生图、图生视频及文生图生成字节跳动 Waver 项目组近期正式推出 Waver 1.0 一体化视频生成模型,凭借多模态生成能力、高分辨率支持及卓越的运动建模效果,在视频生成领域实现重要突破,为工业级视频创作需求提供了全新解决方...视频模型# Waver 1.0# 字节跳动# 视频生成7个月前06470
南大、复旦联合英伟达提出LongVie:可控超长视频生成突破1分钟,解决时间不一致难题可控超长视频生成(如生成1分钟以上、场景与动作精准可控的视频)是AI生成领域的核心挑战——现有方法在短视频生成中表现尚可,但扩展到长视频时,常出现时间不一致(帧间突变、物体位置漂移)与视觉质量下降(颜...视频模型# LongVie# 视频生成7个月前01610
LightX2V:轻量级视频生成推理框架,统一支持多种模态输入随着多模态生成模型的发展,文本到视频(T2V)、图像到视频(I2V)等任务逐渐成为研究热点。然而,不同模型往往使用不同的推理流程,导致部署与调用复杂、资源占用高。 为此,研究人员推出了一个全新的轻量级...视频模型# LightX2V# 视频生成9个月前02770
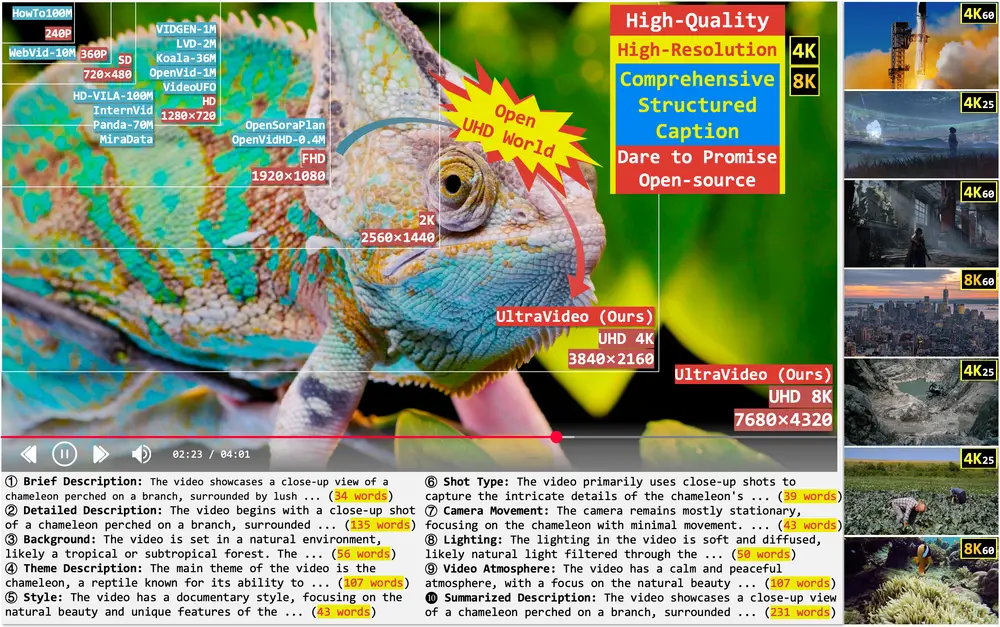
UltraVideo 与 UltraWAN:首个支持原生 UHD 视频生成的开源数据集与模型随着高质量视频内容需求的快速增长,如电影级超高清(UHD)制作、沉浸式媒体和短视频创作,对文本到视频(T2V)模型的能力提出了更高要求。 然而,现有公开数据集在分辨率、图像质量及字幕细节方面存在明显不...视频模型# UltraVideo# UltraWAN# UltraWanComfy9个月前04390
Character.AI 发布全新多媒体功能:视频生成和社交动态功能AI 角色平台 Character.AI 宣布推出一系列重大更新,标志着其从传统的文本对话平台向多模态互动创作平台迈出关键一步。这些新功能包括: AvatarFX(视频生成模型) 场景(沉浸式叙事) ...早报# Character.AI# 视频生成10个月前01860
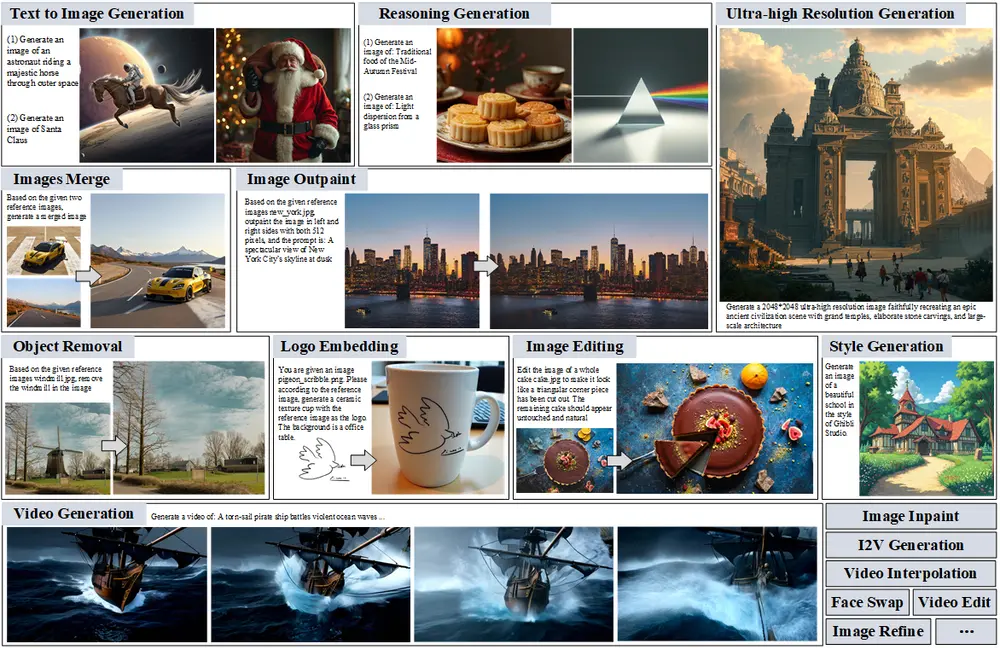
基于 ComfyUI 平台构建的协作式 AI 系统ComfyMind:打造稳定、灵活、可扩展的通用生成平台随着生成模型的飞速发展,“通用生成(General-Purpose Generation)”正成为 AI 领域的新焦点。它旨在通过一个统一系统,支持图像、视频、文本等多种模态任务的生成与编辑,为复杂创...新技术# ComfyMind# 图像生成# 视频生成10个月前03410