在视频生成领域,动作控制是连接静态图像与动态叙事的关键环节。然而,现有方法普遍存在两个瓶颈:一是控制粒度粗糙(如仅用边界框控制整体移动),二是依赖额外模型(如光流估计器),导致推理复杂、误差累积、难以扩展。
- 项目主页:https://wan-move.github.io
- GitHub:https://github.com/ali-vilab/Wan-Move
- 模型:https://huggingface.co/Ruihang/Wan-Move-14B-480P
- ComfyUI:https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled/tree/main/WanMove
为解决这些问题,阿里通义实验室、清华大学、香港大学、香港中文大学的研究团队提出了 Wan-Move —— 一个无需额外动作编码器、直接通过点轨迹注入动作信息的视频生成框架。该方法在保持模型架构简洁的同时,实现了商业级的动作精度与视觉保真度。
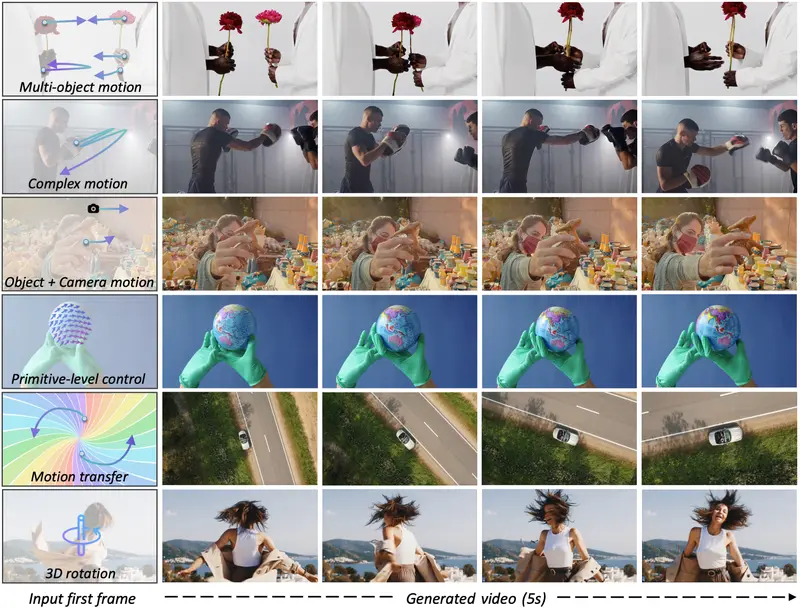
核心创新:动作轨迹直接注入条件特征
Wan-Move 的核心思想是:不在模型外部估计动作,而是将动作信息直接写入 I2V(图像到视频)模型的条件特征中。
具体流程如下:
- 动作表示:使用点轨迹(point trajectories)描述对象的运动,可涵盖从简单平移、局部形变到复杂交互的各类动作;
- 空间映射:将像素空间中的轨迹点映射到扩散模型的潜在空间坐标;
- 特征复制:将首帧的潜在特征沿轨迹路径逐帧复制,利用潜在空间的平移等变性(translation equivariance),让每个视觉元素“知道该如何移动”;
- 条件更新:将更新后的潜在特征作为新的条件输入 I2V 模型(如 Wan2.1),无需修改模型结构或引入额外模块。
这一设计彻底绕过了光流估计、动作编码器等中间环节,大幅降低计算开销与误差传递。
主要功能与优势
✅ 精确动作控制
- 支持点轨迹、边界框、分割掩码等多种引导方式;
- 可控制单对象、多对象的独立运动,适用于复杂交互场景。
✅ 高质量生成
- 在 MoveBench 基准上,Wan-Move 在 FID、FVD、PSNR、SSIM、端点误差(EPE) 等指标上全面优于现有方法;
- 用户研究显示,其在动作准确性与视觉质量上胜率显著,与商业产品 Kling 1.5Pro 的 Motion Brush 相当,甚至在动作细节上更优。
✅ 架构简洁,易于集成
- 仅需微调现有 I2V 模型(如 Wan2.1);
- 无需额外网络、无需光流预处理,推理流程与标准 I2V 一致;
- 已由开源社区开发者 Kijai 集成至 ComfyUI 封装器,支持本地一键部署。
✅ 可扩展性强
- 可在大规模数据集上训练,适应不同场景(如 3D 旋转、相机运动、运动迁移等);
- 模块化设计支持快速迁移到其他 I2V 架构。
技术生态与可用性
- 基础模型基于 Wan2.1(通义 Wan 系列);
- 开源社区已集成至 ComfyUI,用户可本地运行,无需云端依赖;
- 支持灵活的动作引导输入,适配从简单移动到复杂多对象交互的多样化需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...