新型视频生成技术“CVD(协作视频扩散)”:生成从多个不同摄像机轨迹视角下观察同一场景的一致性视频斯坦福大学和香港中文大学的研究人员推出新型视频生成技术“协作视频扩散”(Collaborative Video Diffusion,简称CVD),这项技术的核心目标是能够生成从多个不同摄像机轨迹视角下...新技术# CVD# 协作视频扩散# 视频生成2年前01,0290
字节跳动推出新型视频生成技术CamTrol:为现有的视频扩散模型增添摄像机运动操控功能中国科学技术大学和字节跳动的研究人员推出新型视频生成技术CamTrol,这是一种无需训练的、强大的解决方案,可以为现有的视频扩散模型增添摄像机运动操控功能。简单来说,就是可以在不经过额外训练的情况下...新技术# CamTrol# 字节跳动# 视频生成2年前08810
高质量人类动作视频生成框架MimicMotion:依据任意运动指令生成高质感、任意长度的视频内容腾讯和上海交通大学的研究人员推出高质量人类动作视频生成框架MimicMotion,依据任意运动指令生成高质感、任意长度的视频内容。简单来说,MimicMotion是一个可以制作出逼真人类动作视频的智能...新技术# MimicMotion# 视频生成2年前08570
新型视频生成框架ConFiner:结合多个专家模型的能力,以一种高效且无需训练的方式,生成高质量且连贯的视频内容悉尼大学、东南大学、中南大学、上海交通大学、商汤科技研究院和香港科技大学的研究人员推出新型视频生成框架ConFiner,它通过一系列现成的扩散模型专家(diffusion model experts...新技术# ConFiner# 视频生成2年前08290
图像和视频生成框架StoryDiffusion:能够生成一系列内容一致的图像和视频来自南开大学和字节跳动的研究人员推出一种新的图像和视频生成框架StoryDiffusion,这项技术的核心在于它能够生成一系列内容一致的图像和视频,这对于讲述一个故事或者展示一个连贯的场景来说非常重要...新技术# StoryDiffusion# 图像生成# 视频生成2年前08050
新型视频生成模型HPDM:通过分层处理和上下文融合技术,生成高分辨率视频Snap、阿卜杜拉国王科技大学和特伦托大学的研究人员推出新型视频生成模型Hierarchical Patch Diffusion Models(HPDM,分层补丁扩散模型),这个模型专门设计用于高分辨...新技术# HPDM# 分层补丁扩散模型# 视频生成2年前07670
FreeNoise:通过噪声调度实现无需调参的长视频生成来自腾讯人工智能实验室、南洋理工大学、香港科技大学的研究人员提出了一种利用预训练的视频扩散模型生成高质量长视频的方法FreeNoise,它能够使模型在生成更长时间视频时保持内容的一致性,无需对模型进行...新技术# AI视频# FreeNoise# 噪声2年前07250
无需训练的新策略FasterCache:加速高质量视频生成的视频生成模型的推理视频生成是当前 AI 领域的一个热点研究方向,特别是基于扩散模型的方法。然而,这些模型的推理速度通常较慢,限制了它们在实际应用中的效率。香港大学、南洋理工大学 S-Lab 和上海人工智能实验室的研究人...新技术# FasterCache# 视频生成1年前06790
DragAnything:视频生成中任意对象的运动控制来自快手、浙江大学和新加坡国立大学的研究团队推出DragAnything,它是一种用于视频生成和控制的方法,它利用实体表示法来实现对视频生成中任意对象的运动控制。 项目主页 GitHub 论文 例如...新技术# DragAnything# 视频生成# 运动控制2年前06650
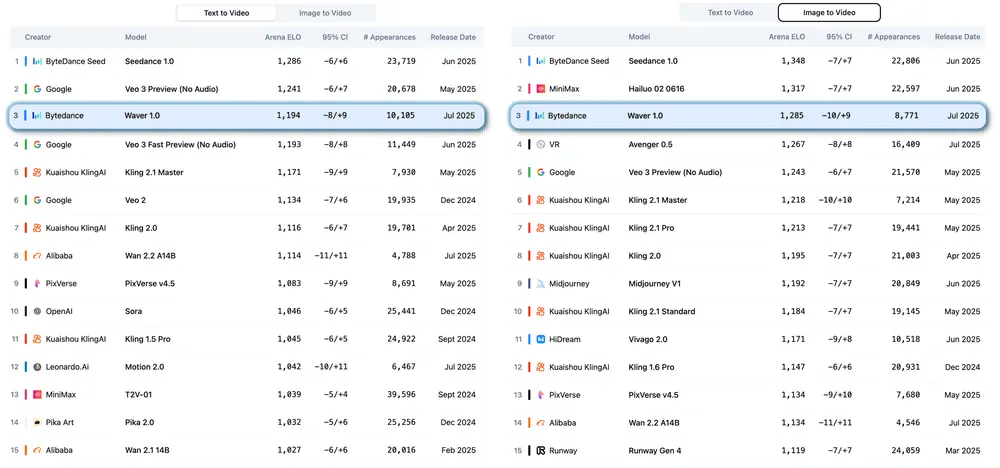
字节跳动 Waver 项目组推出一体化视频生成模型Waver 1.0:同时支持文生图、图生视频及文生图生成字节跳动 Waver 项目组近期正式推出 Waver 1.0 一体化视频生成模型,凭借多模态生成能力、高分辨率支持及卓越的运动建模效果,在视频生成领域实现重要突破,为工业级视频创作需求提供了全新解决方...视频模型# Waver 1.0# 字节跳动# 视频生成7个月前06470
新型框架Uni3C:通过3D增强技术实现对视频生成中相机和人体运动的精确控制阿里达摩院、复旦大学和湖畔实验室的研究人员推出新型框架Uni3C,旨在通过3D增强技术实现对视频生成中相机和人体运动的精确控制。Uni3C通过将相机控制和人体运动控制统一到一个框架中,解决了现有方法中...新技术# Uni3C# 人体运动# 视频生成11个月前06380
无需额外训练的新型过渡视频生成方法TVG:在不同场景或画面之间流畅过渡的视频效果索贝媒体智能实验室、四川大学网络科学与工程学院、数据保护与智能管理教育部重点实验室(四川大学)和中国电子科技大学的研究人员推出一种无需额外训练的新型过渡视频生成方法TVG,它是一种无需训练就能生成平滑...新技术# TVG# 视频生成2年前06270