背景移除模型BEN:自动从图像中移除背景,生成二值掩码和前景图像BEN(Background Erasure Network)是由Prama LLC推出的一款深度学习模型,旨在自动从图像中移除背景,生成二值掩码和前景图像。 模型:https://huggingfa...图像模型# BEN# 背景移除模型12个月前05140
SliderSpace:自动分解文生图模型的视觉能力,将其转化为简单的滑块控件,使用户能够更直观地控制生成结果扩散模型(Diffusion Models)在生成高质量图像方面表现出色,但其生成过程的黑箱性质限制了用户的控制能力。为了增强扩散模型的可控性和可解释性,来自美国东北大学和 Adobe Researc...图像模型# Adobe Research# SliderSpace# 东北大学11个月前05120
小红书推出图像生成模型StoryMaker:不仅能保持面部一致性,还能保持服装、发型和身体的一致性,从而通过一系列图像促进故事的创作小红书推出图像生成模型StoryMaker,它专门设计用于在文本到图像的生成过程中保持人物的一致性。这种一致性不仅限于人物的面部特征,还包括服装、发型和身体特征。通过这种方式,StoryMaker能够...图像模型# StoryMaker# 小红书12个月前05100
nano-banana正式版!谷歌发布全新图像模型Gemini 2.5 Flash Image,更精准的 AI 图像编辑谷歌正在为其 Gemini 聊天机器人引入一项重要升级:全新的 AI 图像模型 Gemini 2.5 Flash Image。该模型不仅提升了图像生成质量,更在编辑精度、角色一致性与多图融合方面实现了...图像模型# AI 图像编辑# Gemini 2.5 Flash Image# nano-banana5个月前05080
Momo XL:基于SDXL的动漫风格模型Momo XL 是一个基于 Stable Diffusion XL (SDXL) 的动漫风格模型,经过微调后,能够生成具有详细和生动美学的优质动漫风格图像。这款模型专为艺术家和动漫爱好者设计,提供了多...图像模型# Momo XL# SDXL# 动漫风格12个月前04980
基于 GenAI 的视觉内容创作控制框架ZenCtrl:利用单张主体图像生成多视角、多样化场景的高分辨率图像,无需额外微调ZenCtrl 是一款基于 GenAI 的视觉内容创作控制框架,专注于利用单张主体图像生成多视角、多样化场景的高分辨率图像,无需额外微调。它通过精细的控制能力和模块化设计,为创作者提供了一个强大且灵活...图像模型# OminiControl# ZenCtrl# 图像控制框架9个月前04950
新型文生图架构Diffusion-RWKV:基于RWKV模型,为改进图像生成任务而设计昆仑万维推出新型文生图架构Diffusion-RWKV,它是为了改进图像生成任务而设计的。这个架构是基于RWKV模型,这是一种在自然语言处理(NLP)领域中使用的模型,但经过了特别的修改,使其更适合处...图像模型# Diffusion-RWKV# RWKV模型# 文生图架构12个月前04890
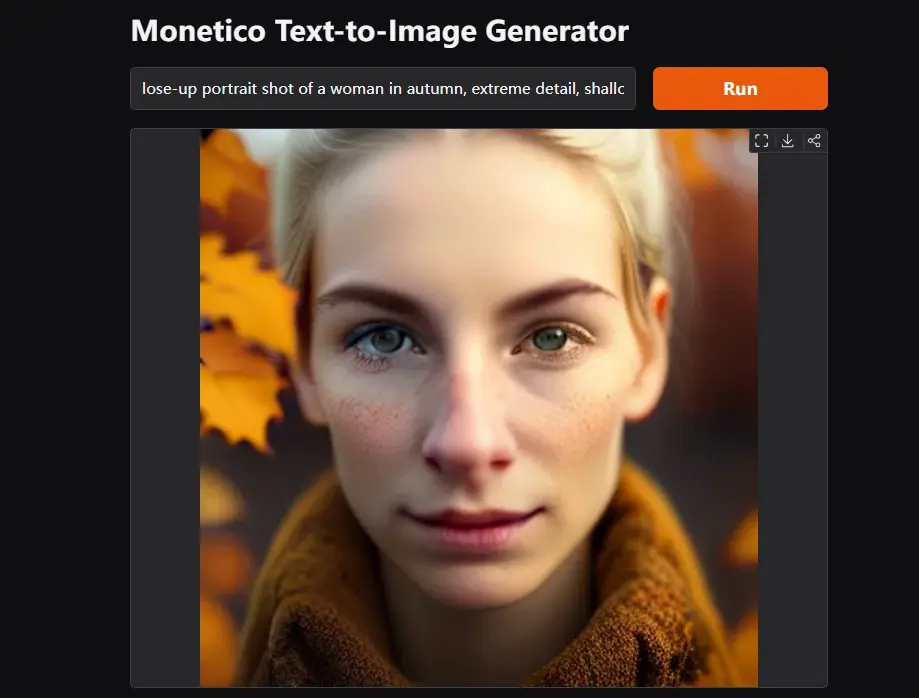
Collov Labs推出非自回归掩码图像建模的文本到图像合成模型MoneticoCollov Labs 最近在8块H100 GPU上训练了一周时间,推出了新的非自回归掩码图像建模的文本到图像合成模型——Monetico。这款模型能够生成高分辨率图像,并且被设计为在消费级显卡上高效...图像模型# Monetico# 文生图模型12个月前04780
高容量真实世界图像恢复模型DreamClear:结合隐私安全的数据处理流程(GenIR)和DiT技术,以实现对低质量图像的高质量恢复现实世界中的图像恢复(IR)面临着显著的挑战,主要是缺乏高容量模型和全面的数据集。为了解决这些问题,中国科学院自动化研究所、中国科学院大学人工智能学院、字节跳动公司和中国科学技术大学的研究人员提出了一...图像模型# DreamClear# 图像恢复模型12个月前04770
Anzhc 开源系列 YOLO 模型:专注细粒度图像分割与分类任务在图像检测与分割领域,高质量的专用模型往往能显著提升下游任务的表现。开发者 Anzhc 基于自建标注数据集,训练并开源了一系列面向特定视觉任务的 YOLO 模型,涵盖面部、眼部、头部、胸部等细粒度目标...图像模型# YOLO 模型# 图像分割6个月前04690
Stability AI推出其最新的图像生成模型系列Stable Diffusion 3.5(SD3.5):更具可定制性和多功能性,同时在性能上也有所提升在经历了一系列由技术故障和许可变更引发的争议后,Stability AI宣布了其最新的图像生成模型系列—Stable Diffusion 3.5(SD3.5),新的Stable Diffusion 3...图像模型# SD3.5# Stability AI# Stable Diffusion 3.512个月前04630
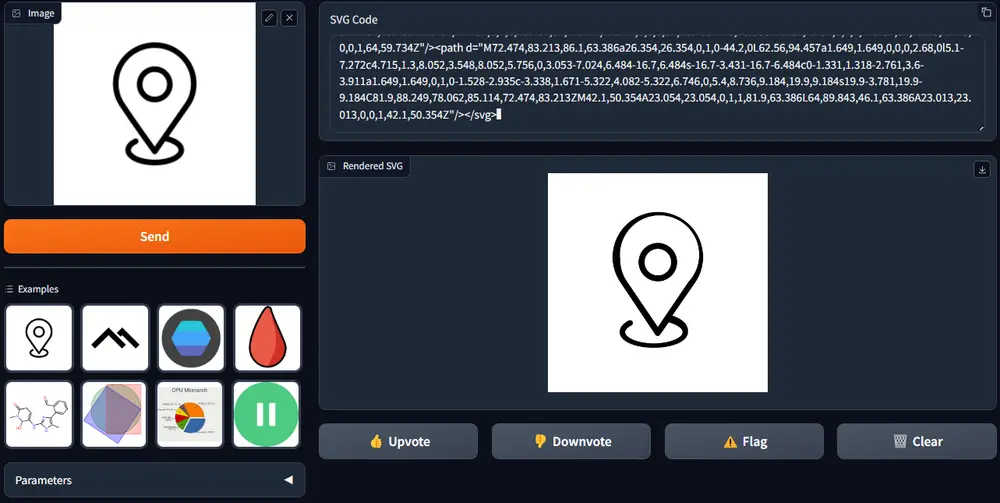
StarVector:利用多模态大语言模型(MLLM)从图像和文本生成SVG代码ServiceNow Research、魁北克人工智能研究所、加拿大 CIFAR 人工智能主席、不列颠哥伦比亚大学、高等工程技术学院和苹果的研究人员推出StarVector,利用多模态大语言模型(ML...图像模型# StarVector# SVG代码# 多模态大语言模型10个月前04590