
谷歌正在为其 Gemini 聊天机器人引入一项重要升级:全新的 AI 图像模型 Gemini 2.5 Flash Image。该模型不仅提升了图像生成质量,更在编辑精度、角色一致性与多图融合方面实现了显著突破。

这项更新已于今天向所有 Gemini 应用用户开放,同时通过 Gemini API、Google AI Studio 和 Vertex AI 平台提供给开发者使用,标志着谷歌在 AI 图像生成领域的又一次关键布局。

核心能力:让图像编辑真正“听懂”你的需求
Gemini 2.5 Flash Image 的核心目标是:基于自然语言指令,实现更可控、更一致的图像编辑。
与许多现有工具相比,它在以下场景中表现尤为突出:
- 将照片中人物的衬衫颜色从蓝色改为红色,面部特征和背景保持不变;
- 给宠物换装后,五官和毛发细节依然可辨;
- 多次编辑同一人物(如换发型、换场景),外貌始终保持一致。
这类“细微但关键”的一致性,正是当前多数 AI 图像工具的短板。例如,在 ChatGPT 或 Grok 中执行类似操作,常会出现人脸扭曲、肢体变形或背景错乱等问题。
而 Gemini 2.5 Flash Image 通过深度优化视觉编码器与扩散模型的协同机制,在保持语义理解的同时,强化了对主体结构的保留能力。
“我们真正推动了视觉质量的进步,以及模型遵循指令的能力。”
——Nicole Brichtova,Google DeepMind 视觉生成模型产品负责人
用户早已“尝鲜”:“nano-banana”背后的秘密
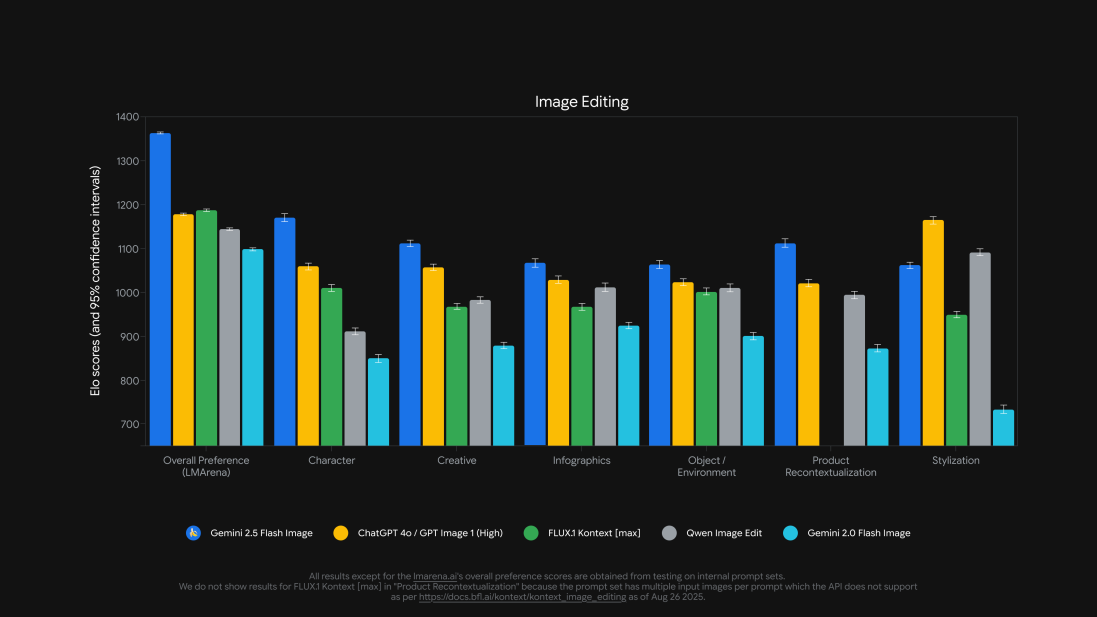
在过去几周,不少用户在众包评测平台 LMArena 上对一个名为“nano-banana”的匿名图像编辑器给予了高度评价——响应快、效果准、细节稳。
如今谷歌正式确认:“nano-banana”就是 Gemini 2.5 Flash Image 的测试代号。
这一命名或许带有调侃意味(早期测试中大量香蕉示例引发热议),但也反映出该模型在真实用户反馈中的强劲表现。据谷歌称,该模型在 LMArena 和其他基准测试中已达到当前开源与闭源系统中的领先水平。
功能亮点:不只是修图,更是创意协作
Gemini 2.5 Flash Image 支持多种高级图像操作,适用于个人用户与开发者。
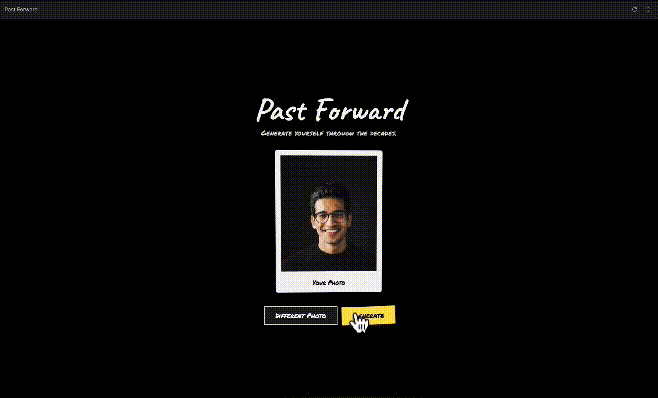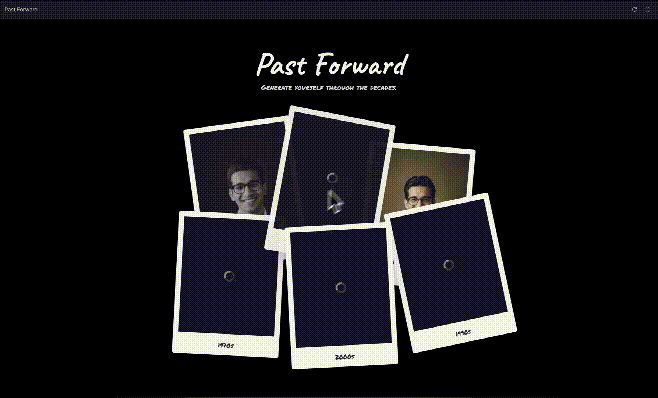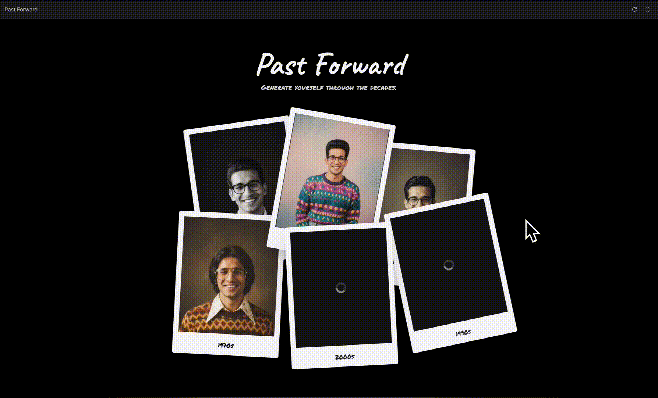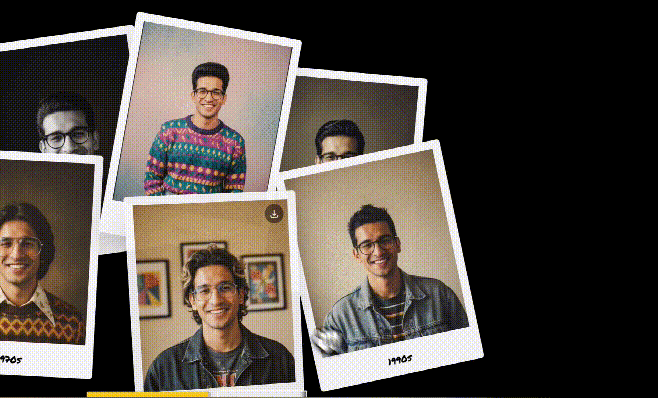
1. 角色一致性(Character Consistency)
- 可将同一人物置于不同场景(如海滩、雪山、办公室);
- 支持多角度生成,适合产品展示或角色设定;
- 宠物、家人照片编辑后仍“一眼认出”。
示例:上传一张自拍照,让模型生成你在 60 年代穿复古风、在 90 年代打篮球、在未来穿宇航服的图像——但脸始终是你。
2. 多图融合(Multi-Image Fusion)
- 支持上传多张参考图,合成新场景;
- 可结合人物照片、室内环境图与配色方案,一键生成装修预览;
- 适用于家居设计、广告创意、内容创作等场景。
示例:上传你的照片 + 客厅空镜 + 色卡,模型生成你坐在新风格客厅中的逼真图像。
3. 多轮编辑(Iterative Editing)
- 编辑后的图像可再次作为输入继续修改;
- 支持“空房间 → 刷墙 → 加家具 → 调灯光”的渐进式改造;
- 每次只改局部,其余内容保持不变。
4. 风格迁移(Style Transfer)
- 提取一张图像的纹理或色彩风格,应用到另一对象上;
- 如:用花瓣的质感设计雨靴,用蝴蝶翅膀图案制作连衣裙。
5. 原生世界知识(World Knowledge)
- 模型具备对现实世界的语义理解;
- 能识别手绘草图并转化为专业图表;
- 支持教育、工程、设计等需要上下文理解的场景。
示例:画一个简笔画电路图,Gemini 可识别元件并生成标准示意图。
四、面向开发者:全面接入 AI Studio 与 API
除了面向消费者的 Gemini 应用,Google 也同步向开发者开放能力:
- Google AI Studio:提供可视化界面,支持用自然语言快速构建图像应用(如“做个滤镜工具”);
- Gemini API / Vertex AI:企业可集成至自有系统,用于自动化内容生成、电商展示等;
- OpenRouter.ai:已接入该模型,覆盖其 300 万+ 开发者社区;
- fal.ai:合作推出生成媒体开发支持。
- 模板:https://aistudio.google.com/apps/bundled/codrawing
- pixshop:https://aistudio.google.com/apps/bundled/pixshop
定价信息(预览阶段):
- 输出:每 100 万 token 收费 $30.00
- 单张图像约消耗 1290 输出 token → 单次生成成本约 $0.039
- 输入与其他模态沿用 Gemini 2.5 Flash 标准定价
注:目前处于预览阶段,未来几周将转为稳定版本。
为何此时发力 AI 图像?
AI 图像生成已成为科技巨头竞争的核心战场。
- OpenAI 在今年 3 月推出 GPT-4o 原生图像生成功能后,ChatGPT 使用量激增,一度因大量用户生成宫崎骏风格图像导致 GPU 资源紧张;
- Meta 上周宣布将引入 Midjourney 技术,强化其 AI 图像能力;
- Black Forest Labs 凭借 FLUX 模型在多项基准测试中领先;
- 用户期待从“能画”转向“能精修、能控制”。
谷歌此次推出 Gemini 2.5 Flash Image,正是为了在这一关键赛道上缩小与 OpenAI 的差距。
尽管谷歌CEO 孙达尔·皮柴(Sundar Pichai)在财报电话会上透露 Gemini 已有 4.5 亿月活用户,但相比 ChatGPT 的每周超 7 亿用户,仍有明显差距。强化图像能力,有助于提升用户粘性与使用频率。
安全机制:水印 + 内容限制双管齐下
Google 并未忽视 AI 图像带来的风险。
内容管控:
- 明确禁止生成“非自愿亲密图像”;
- 服务条款中强化对敏感内容的限制;
- 相比之下,Grok 等部分竞品尚未建立同等防护。
防伪措施:
- 所有生成或编辑的图像均嵌入 SynthID 数字水印(不可见元数据);
- 同时添加可见水印标识,便于公众识别 AI 内容。
尽管如此,社交媒体浏览者未必会主动查看水印,因此平台责任与用户教育仍需同步推进。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











