新型多层透明图像生成方法ART:通过全局文本提示和匿名区域布局直接生成具有多个透明图层的图像微软亚洲研究院、清华大学、北京大学和中国科学技术大学的研究人员推出新型多层透明图像生成方法Anonymous Region Transformer (ART) ,通过全局文本提示和匿名区域布局直接生成...图像模型# ART# 透明图像12个月前02940
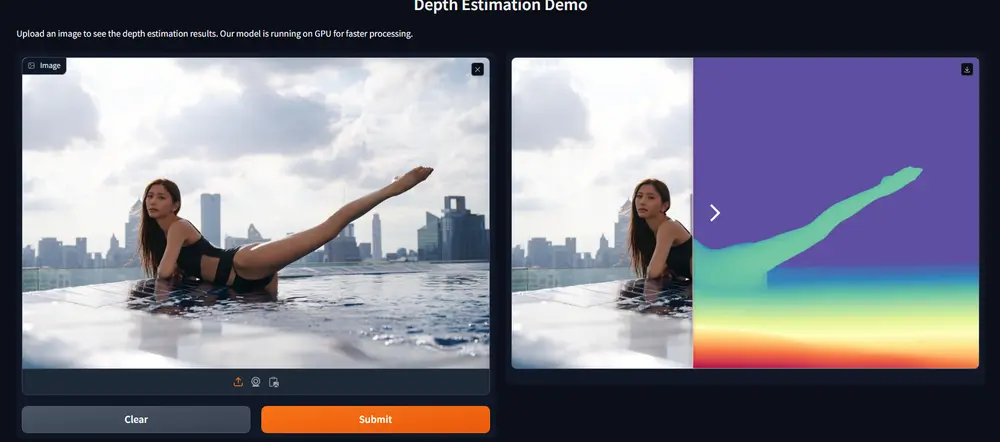
新单目深度估计模型Distill-Any-Depth:新型知识蒸馏框架的单目深度估计方法单目深度估计(MDE)旨在从单一 RGB 图像中预测场景深度,是 3D 场景理解中的关键任务。近年来,零样本 MDE 的研究取得了显著进展,主要依赖归一化的深度表示和基于蒸馏的学习来提高模型在不同场景...图像模型# Distill-Any-Depth# 深度估计模型# 知识蒸馏框架12个月前04200
SliderSpace:自动分解文生图模型的视觉能力,将其转化为简单的滑块控件,使用户能够更直观地控制生成结果扩散模型(Diffusion Models)在生成高质量图像方面表现出色,但其生成过程的黑箱性质限制了用户的控制能力。为了增强扩散模型的可控性和可解释性,来自美国东北大学和 Adobe Researc...图像模型# Adobe Research# SliderSpace# 东北大学1年前05450
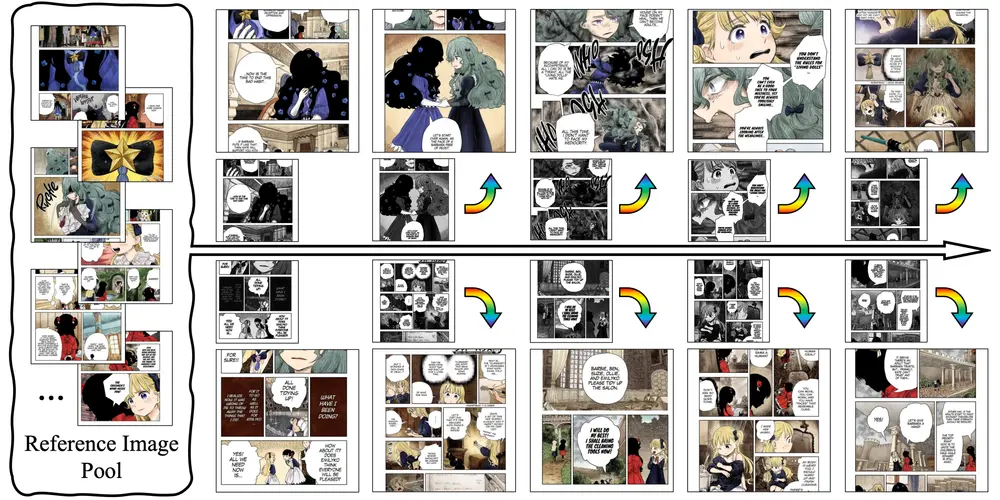
基于DiT模型的多领域程序化序列生成框架MakeAnything:根据文本描述或图像生成分步骤的教程新加坡国立大学的研究团队推出 MakeAnything,这是一个基于DiT模型的多领域程序化序列生成框架,能够根据文本描述或图像生成分步骤的教程,也就是生成一致性图片序列。 GitHub:https...图像模型# DiT模型# MakeAnything1年前02890
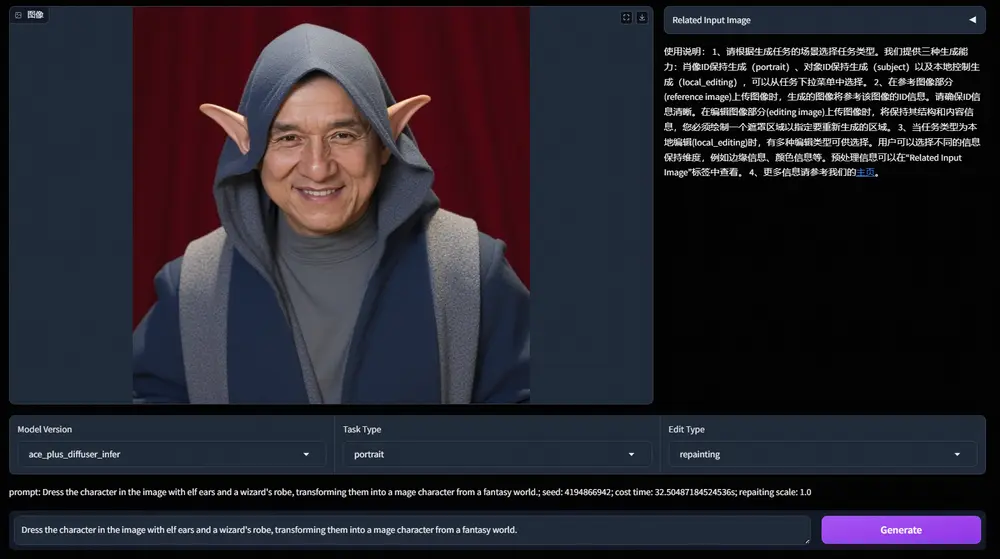
通义实验室推出基于指令的图像生成和编辑框架ACE++:基于FLUX.1-dev模型,实现多种图像生成和编辑任务阿里巴巴通义实验室推出基于指令的图像生成和编辑框架ACE++,这是之前介绍过的新型多模态生成模型ACE升级版,ACE++ 通过改进的长上下文条件单元(LCU++)和两阶段训练方案,能够高效地利用预训练...图像模型# ACE# FLUX.1-dev# 图像生成1年前03500
上海AI实验室发布Lumina系列图像生成模型的最新成果—Lumina-Image 2.0上海AI实验室正式发布了Lumina系列图像生成模型的最新成果——Lumina-Image 2.0。这一版本不仅提高了图像生成的效率,还通过其统一且透明的设计理念,为用户提供了更加流畅和便捷的使用体验...图像模型# Lumina-Image 2.01年前02890
专注于精确角色细节转录的线稿上色模型MangaNinja香港大学、香港科技大学、通义实验室和蚂蚁集团的研究人员合作推出了一款专注于精确角色细节转录的线稿上色模型——MangaNinja。MangaNinja专门用于将线稿图像转换为彩色图像,同时保持与参考图...图像模型# MangaNinja# 线稿上色模型1年前03110
用文生图的新型规模感知变换器SWITTI:基于现有的下一代规模预测自回归(AR)模型Yandex Research、俄罗斯国立研究型大学高等经济学院、莫斯科物理技术学院和Skoltech科大的研究人员推出新型规模感知变换器SWITTI,它用于文本到图像的合成。SWITTI基于现有的下...图像模型# AR模型# SWITTI1年前03870
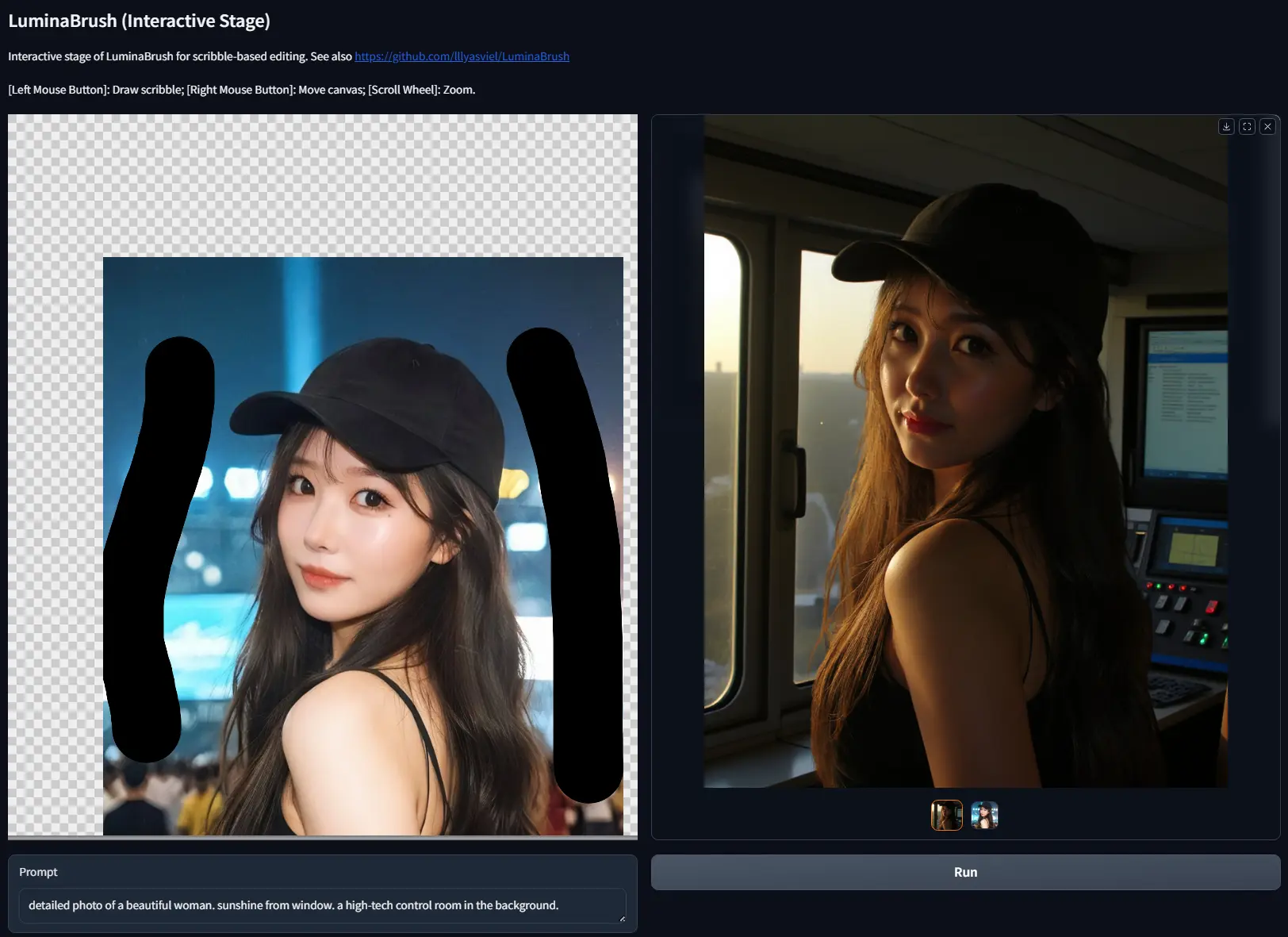
lllyasviel推出交互式图像光照绘制新框架LuminaBrushControlNet的作者lllyasviel继推出IC-Light系列之后,再次推出了一个全新的项目——LuminaBrush。这个项目旨在为用户提供一种简单而强大的方式,在图像上绘制和调整光照效果...图像模型# LuminaBrush# 光照绘制1年前03400
三阶段扩散模型框架ColorFlow:专门用于解决黑白图像的自动着色问题ColorFlow 是由清华大学和腾讯ARC实验室提出的一个创新性三阶段扩散模型框架,专门用于解决黑白图像序列的自动着色问题。该模型旨在确保角色和对象的身份(ID)在着色过程中得到一致保留,同时生成高...图像模型# ColorFlow1年前03350
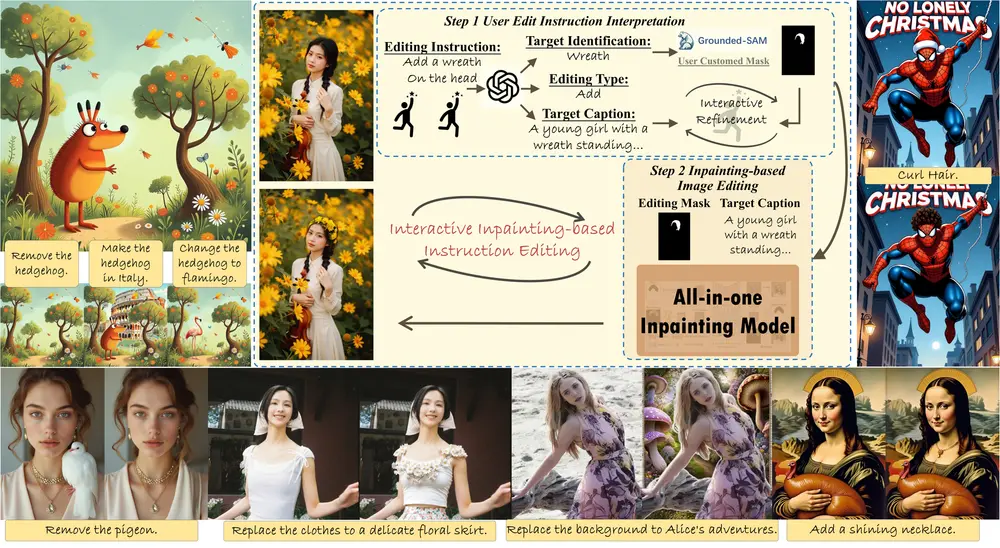
基于修复的指令引导图像编辑框架BrushEdit:通过自然语言指令进行无缝编辑,包括添加对象、移除元素或进行结构性更改等多样化编辑操作图像编辑技术近年来在基于反演(inversion-based)和基于指令(instruction-based)的方法上取得了显著进步。然而,这些方法各自存在局限性: 基于反演的方法:在处理重大修改(如...图像模型# BrushEdit# 图像编辑1年前03300
新型插件式适应方法EasyRef:允许扩散模型根据多个参考图像和文本提示进行条件生成在个性化生成任务中,扩散模型(Diffusion Models)已经取得了显著的成就。传统的无需调优的方法通常通过平均多个参考图像的图像嵌入作为注入条件来编码,但这种与图像无关的操作无法在图像之间进行...图像模型# EasyRef# 扩散模型1年前03080