
单目深度估计(MDE)旨在从单一 RGB 图像中预测场景深度,是 3D 场景理解中的关键任务。近年来,零样本 MDE 的研究取得了显著进展,主要依赖归一化的深度表示和基于蒸馏的学习来提高模型在不同场景中的泛化能力。然而,现有的基于全局归一化的伪标签蒸馏方法存在一个问题:它们可能会放大噪声伪标签,从而降低蒸馏效果。
- 项目主页:https://distill-any-depth-official.github.io
- GitHub:https://github.com/Westlake-AGI-Lab/Distill-Any-Depth
- 模型:https://huggingface.co/xingyang1/Distill-Any-Depth
- Demo:https://huggingface.co/spaces/xingyang1/Distill-Any-Depth
为了解决这一问题,来自浙江工业大学、西湖大学、兰州大学和南洋理工大学的研究人员推出了一款新单目深度估计模型Distill-Any-Depth。该方法通过系统分析不同的深度归一化策略,并结合跨上下文蒸馏和多教师机制,显著提升了单目深度估计的准确性和鲁棒性。
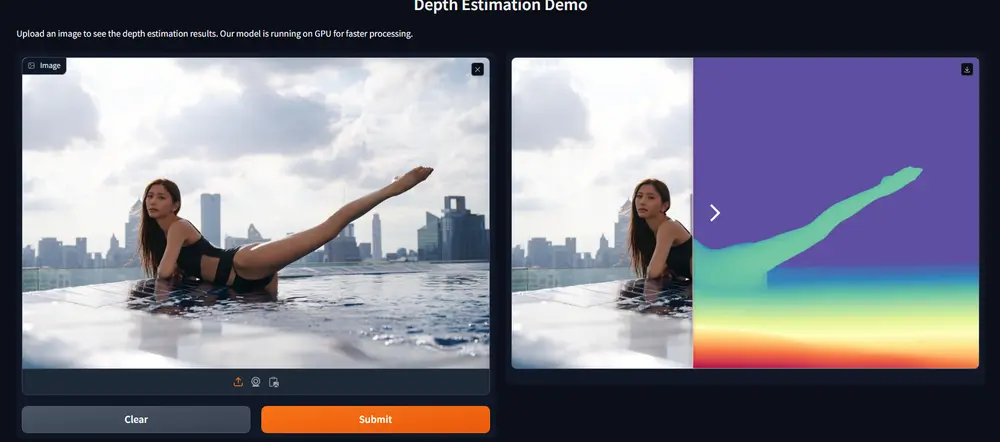
主要功能
- 深度估计:从单张RGB图像中预测场景的深度信息。
- 零样本泛化(Zero-shot Generalization):在没有目标数据集标注的情况下,模型能够泛化到多样化的场景。
- 知识蒸馏:利用教师模型生成的伪标签(pseudo-labels)来监督学生模型的训练,从而提升学生模型的性能。

方法概述
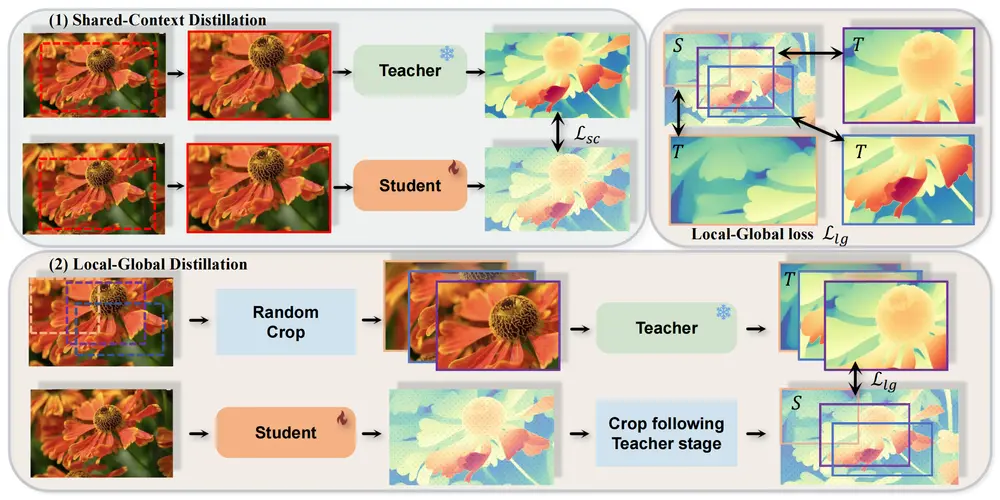
1. 跨上下文蒸馏
跨上下文蒸馏的核心思想是结合局部和全局深度信息以提高学生模型的预测能力。具体包括以下两种情况:
- 共享上下文蒸馏:教师和学生模型使用相同的图像进行蒸馏。
- 局部-全局蒸馏:教师模型预测重叠图像块的深度,而学生模型预测完整图像。通过引入局部-全局损失,确保局部和全局预测之间的一致性,使学生模型能够学习精细细节和广泛结构。
这种方法的优势在于:
- 提高了伪标签的质量,减少了噪声的影响。
- 允许学生模型同时捕获局部细节和全局结构。
2. 归一化策略
研究人员比较了四种归一化策略:
- 全局范数:对整个图像进行归一化。
- 混合范数:结合全局和局部归一化。
- 局部范数:仅对局部区域进行归一化。
- 无范数:不进行任何归一化。
通过实验发现,不同的归一化策略对伪标签的质量有显著影响。最终选择的混合范数策略能够在减少噪声的同时保留更多的细节信息。
3. 多教师机制
为了进一步提升蒸馏效果,研究人员引入了多教师蒸馏框架。该框架利用多个深度估计模型的互补优势,生成更高质量的伪标签。在每个训练迭代中,随机选择一个教师模型为未标记图像生成伪标签。这种机制不仅提高了模型的鲁棒性,还增强了其泛化能力。
实验结果
1. 室内外场景的 SOTA 性能
研究人员在多个基准数据集上验证了 Distill-Any-Depth 的性能,包括室内场景(如 NYUv2 和 ScanNet)和室外场景(如 KITTI、DIODE 和 ETH3D)。实验结果表明,该方法在定量和定性指标上均显著优于现有方法。
- 在 DIODE 数据集上,Distill-Any-Depth 的平均绝对误差(MAE)比基线方法降低了 15%。
- 在 ETH3D 数据集上,该方法在复杂室外环境中表现出更强的泛化能力。
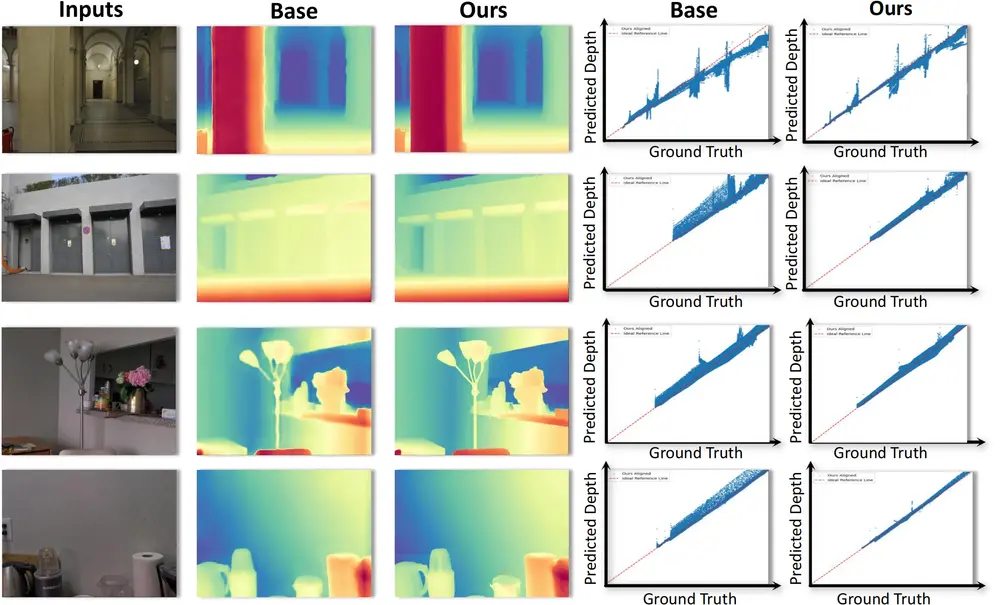
2. 可视化比较
与最先进的方法(如 MiDaS v3.1、DepthAnythingv2 和 Marigold)相比,Distill-Any-Depth 生成的深度图具有更精细的粒度和更详细的边缘。特别是在黑色箭头指示的关键区域,该方法展现了更高的准确性。
3. 消融研究
研究人员通过消融实验验证了各模块的有效性:
- 跨上下文蒸馏:显著提高了模型对局部细节的捕捉能力。
- 混合范数策略:有效减少了噪声伪标签的影响。
- 多教师机制:提升了模型的鲁棒性和泛化能力。
4. 零样本预测
在野外图像上的零样本预测实验中,Distill-Any-Depth 表现出卓越的泛化能力,能够准确估计复杂场景中的深度细节。这证明了该方法在实际应用中的潜力。
技术亮点
- 跨上下文蒸馏:通过结合局部和全局深度信息,提高了伪标签的质量。
- 混合范数策略:优化了深度归一化过程,减少了噪声伪标签的影响。
- 多教师机制:充分利用多个教师模型的互补优势,提升了模型的鲁棒性和泛化能力。
- 广泛的适用性:不仅适用于经典深度模型的蒸馏,还可扩展到生成模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











