图像质量评估体系HPSv3:用“人类偏好”重新定义图像生成质量评估当AI画出一张“森林中休息的鹿”,我们如何判断它画得好不好? 是看它是否包含“鹿”和“树木”?还是看光影是否自然、构图是否美观、整体是否令人愉悦?显然,后者更贴近人类的真实审美。然而,当前大多数文本到...图像模型# HPSv3# 图像质量评估体系6个月前03740
腾讯混元提出 X-Omni:用强化学习突破离散自回归图像生成瓶颈在当前多模态生成模型的发展中,研究者始终在探索一个统一的建模范式:能否用类似语言模型“预测下一个词”的方式,来生成图像?这种被称为“下一令牌预测(next-token prediction)”的自回归...图像模型# X-Omni# 腾讯混元6个月前03730
JarvisArt:由AI驱动的照片修饰智能体,释放你的艺术创造力来自厦门大学、香港科技大学(广州)、字节跳动、新加坡国立大学等机构的研究人员联合推出了一项令人瞩目的新成果 —— JarvisArt。这是一个由多模态大语言模型(MLLM)驱动的照片修饰智能体,能够理...图像模型# JarvisArt# 照片修饰智能体7个月前03700
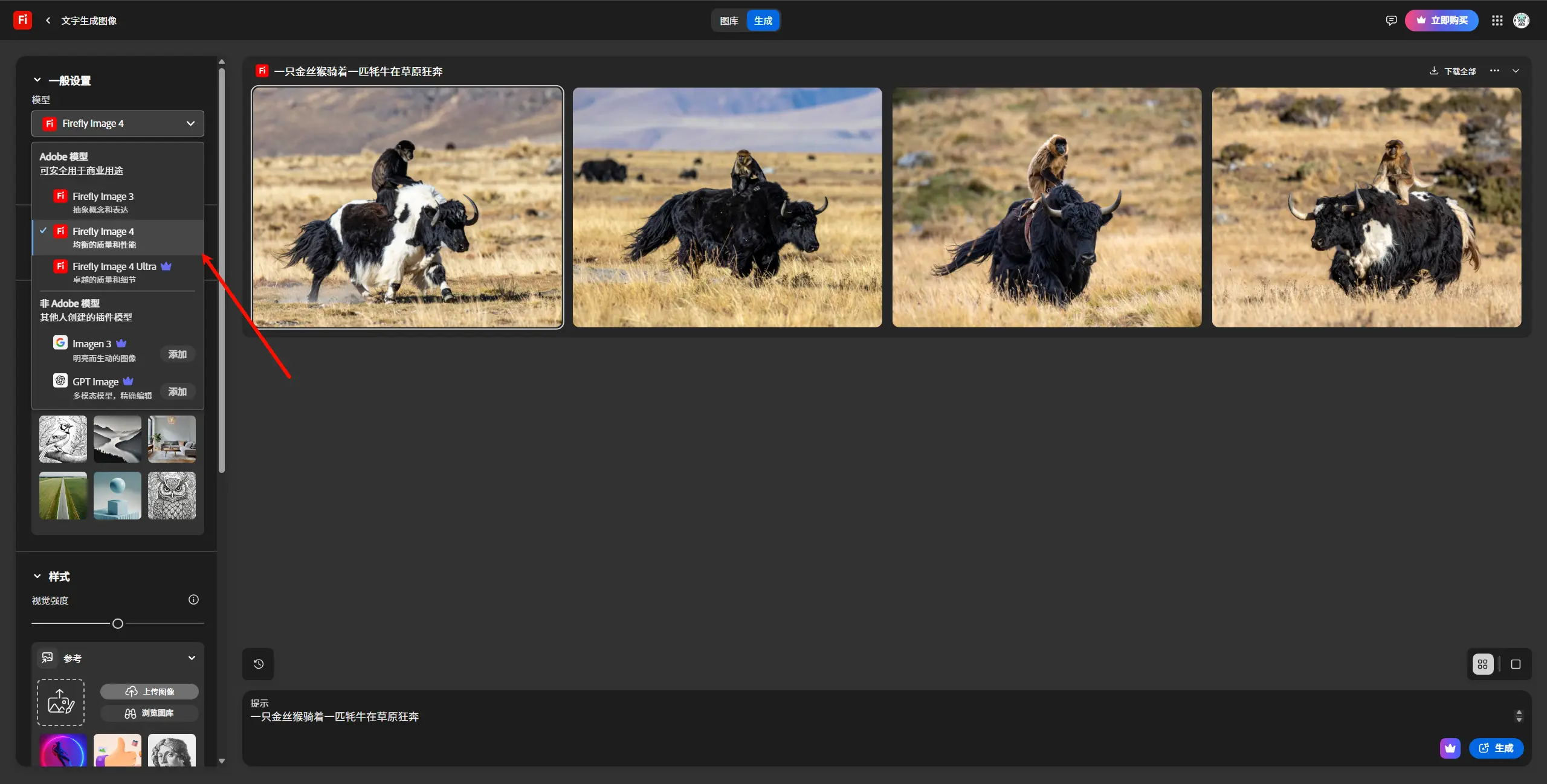
Adobe 推出 Firefly 系列新模型与重新设计的 Web 应用Adobe 在生成式 AI 领域再次迈出重要一步,推出了 Firefly 系列图像生成模型的最新迭代版本、一个全新的 矢量生成模型(Firefly Vector Model),以及一个经过重新设计的 ...图像模型# Adobe# Firefly Image 4# Image 4 Ultra9个月前03690
Krea AI 正式发布首款图像模型 Krea 1:专治“AI味”画面!今天,AI 创意工具平台 Krea AI 宣布推出其首款自研图像生成模型 —— Krea 1。这款模型专注于解决一个长期困扰创作者的问题: “AI 生成的画面,总感觉像 AI。” 而现在,Krea 1...图像模型# Krea 1# Krea AI# 图像模型8个月前03680
南洋理工大学 S-Lab 提出新型对象移除框架ObjectClear ,精准消除物体及其阴影、反射在图像编辑任务中,移除一个物体看似简单,实则极具挑战。 不仅要将目标对象从画面中“擦除”,还需同步清除其带来的视觉副产物——如阴影、倒影、高光、遮挡痕迹等。若处理不当,即便主体消失,残留的影子或反光仍...图像模型# ObjectClear# 南洋理工大学# 对象移除6个月前03660
原生分辨率图像生成新范式NiT:原生分辨率扩散Transformer,实现任意分辨率和宽高比图像生成大语言模型(LLMs)凭借其在原生数据格式上训练的能力,能够高效处理可变长度文本。这种灵活的适应性启发我们思考一个关键问题: 扩散模型能否也具备类似的灵活性,在任意分辨率和宽高比下直接学习生成图像? ...图像模型# NiT# 原生分辨率生成8个月前03660
字节跳动提出的新一代多主体可控图像生成模型XVerse在文本到图像生成领域,如何实现对多个主体身份和语义属性(如姿势、风格、照明)的细粒度控制,同时保持高质量和一致性,一直是一个极具挑战性的问题。 传统方法往往存在以下问题: 在多主体场景中容易引入视觉伪...图像模型# XVerse# 图像生成模型7个月前03650
多模态框架Tar:通过统一的离散语义表示将视觉理解和生成任务整合到一个共享空间中香港中文大学和字节跳动的研究人员推出多模态框架Tar,通过统一的离散语义表示将视觉理解和生成任务整合到一个共享空间中。该框架的核心是 Text-Aligned Tokenizer (TA-Tok),它...图像模型# Tar# 多模态框架7个月前03570
智谱开源首个支持汉字生成的开源文生图模型 CogView4作为中国AI厂商中的开源先锋,智谱AI一直致力于推动技术开放与共享。这家清华系初创企业近年来通过与清华大学合作,开源了多个备受关注的AI模型系列,包括大语言模型GLM系列、文生图模型CogView系列...图像模型# CogView4# 文生图模型# 智谱11个月前03550
虚拟脱衣TryOffDiff:使用SD模型进行高保真服装重建的虚拟试穿比勒费尔德大学 CITEC 机器学习小组提出了一项新颖的任务——虚拟脱衣(Virtual Try-Off, VTOFF),旨在从穿着衣服的单张照片中生成标准化的服装图像。与传统的虚拟试穿(Virtua...图像模型# TryOffDiff# 虚拟脱衣# 虚拟试穿12个月前03540
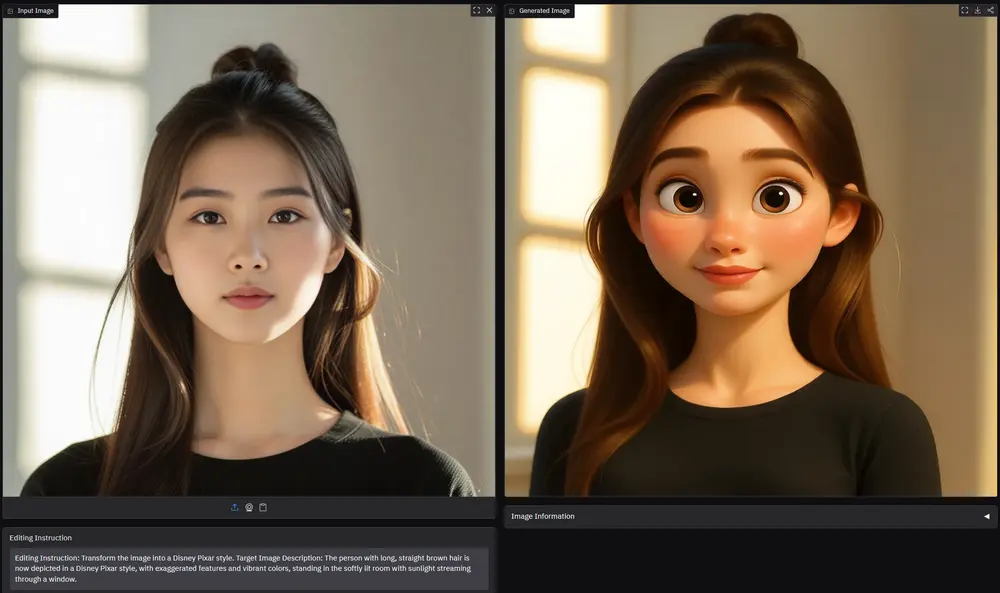
智象未来推出基于 HiDream-I1 的强大图像编辑模型HiDream-E1北京智象未来科技在开源了图像生成基础模型HiDream-I1后,又在今天推出专注于图像编辑的专用模型HiDream-E1,这是一款专为图像编辑任务设计的先进模型,建立在 HiDream-I1 的核心功...图像模型# HiDream-E1# HiDream-I1# 图像编辑模型9个月前03520