B站推出IndexTTS2:自回归 TTS 模型的持续时间控制与情感表达新突破在大规模文本转语音(TTS)模型的发展中,自回归与非自回归系统各有优劣。自回归模型虽然在语音自然度方面表现优异,但其逐标记生成机制难以实现对语音持续时间的精确控制。这一缺陷在视频配音等需要严格音画同步...语音模型# B站# IndexTTS26个月前05340
NeuTTS Air:可在本地运行的高效语音合成模型长期以来,高质量的文本转语音(TTS)能力主要依赖云端 API——虽然效果好,但存在延迟高、隐私风险、网络依赖等问题。 现在,一种新的选择正在出现:在本地设备上实现自然听感的语音合成。 NeuTTS ...语音模型# NeuTTS Air# 语音合成模型5个月前05320
小米推出音频推理模型R1-AQA:强化学习助力机器“听懂”声音背后的逻辑在大模型时代,人们对机器的期望已经不再局限于简单的语音识别或声音分类,而是希望机器能够具备复杂的推理能力。例如,通过汽车座舱的录音判断车辆是否存在潜在故障,从交响乐中推测作曲家的情绪,或者在地铁站的嘈...语音模型# R1-AQA# 小米# 音频推理模型11个月前05210
符号音乐生成模型NotaGen:通过借鉴大语言模型(LLM)的训练范式来生成高质量的古典乐谱中央音乐学院、美国罗切斯特大学、北京飞天云动科技、北京航空航天大学和清华大学的研究人员推出符号音乐生成模型NotaGen,通过借鉴大语言模型(LLM)的训练范式来生成高质量的古典乐谱。其在超过 160...语音模型# NotaGen# 古典音乐生成模型11个月前04950
英伟达发布 Audio Flamingo 3:全球首个支持 10 分钟音频理解的开源模型在视觉和文本领域大模型持续突破之后,音频理解也开始迎来新的里程碑。英伟达近日发布了 Audio Flamingo 3(AF3),这是目前最先进的开源大型音频语言模型(Large Audio Langu...语音模型# Audio Flamingo 3# 英伟达# 音频理解模型7个月前04940
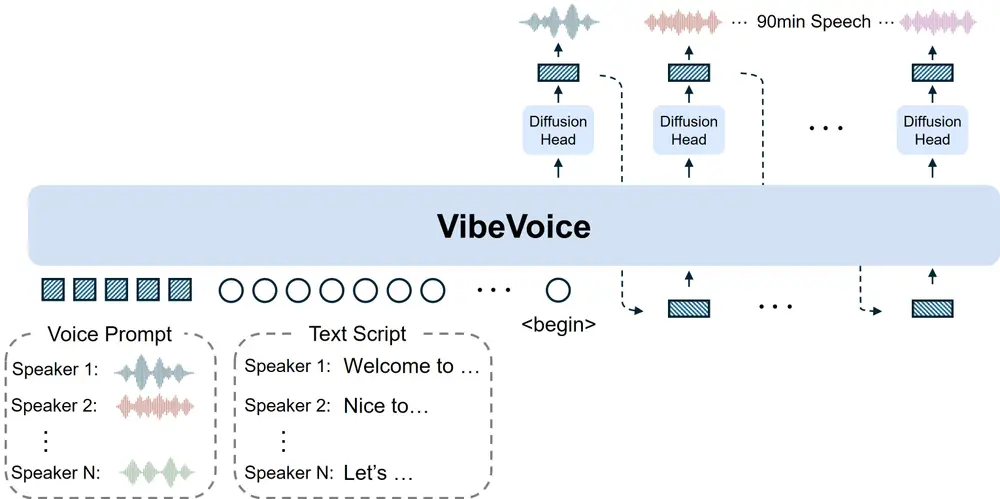
VibeVoice-1.5B:微软开源TTS框架,可生成4人60分钟长对话音频微软近期开源了一款全新文本到语音(TTS)框架——VibeVoice-1.5B,其核心突破在于打破传统TTS系统的局限:能同时生成包含4个不同说话者、最长60分钟的连贯对话音频,且在长序列处理效率、说...语音模型# TTS# VibeVoice-1.5B# 微软6个月前04830
TTS模型FishSpeech推出v1.5 版本:具备多语言支持、零样本即时语音克隆、低延迟等特性FishSpeech v1.5 是一款功能强大的文本到语音(TTS)模型,具备多语言支持、零样本即时语音克隆、低延迟等特性。该模型拥有仅5亿参数,却能够在多种语言之间无缝切换,并提供高质量的语音合成效...语音模型# FishSpeech v1.5# TTS模型1年前04830
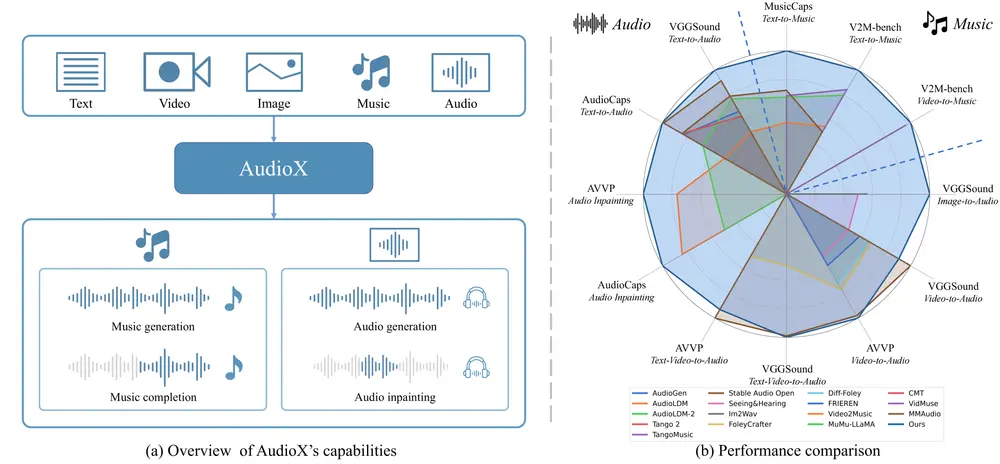
香港科技大学推出统一DiT架构模型AudioX:通过多模态输入(如文本、视频、图像、音乐和音频)生成高质量的音频和音乐香港科技大学的研究人员推出统一DiT架构模型AudioX,通过多模态输入(如文本、视频、图像、音乐和音频)生成高质量的音频和音乐。AudioX通过创新的多模态掩码训练策略,强制模型从掩码输入中学习,从...语音模型# AI音乐# AudioX# DiT模型11个月前04780
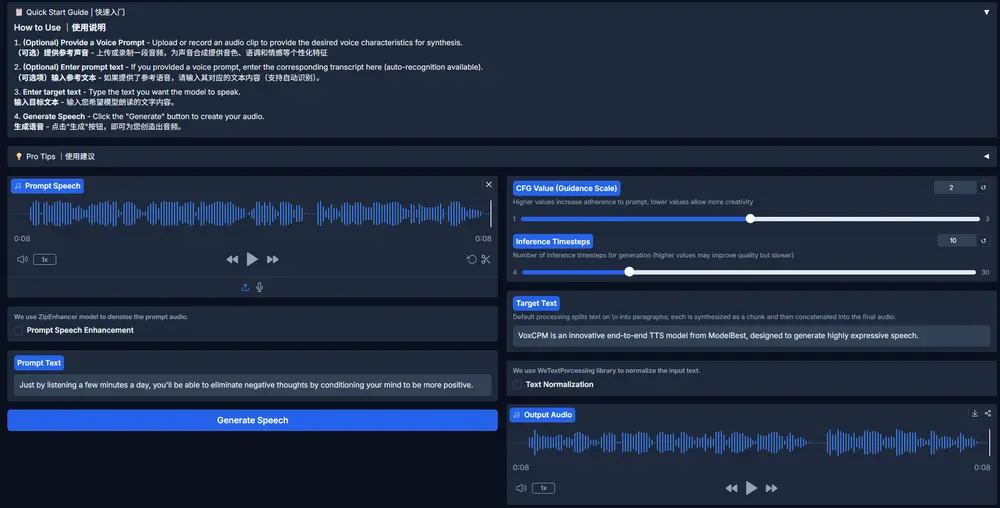
面壁智能发布VoxCPM:无需分词器的TTS,用于上下文感知的语音生成和真实感声音克隆在语音合成领域,大多数主流 TTS(Text-to-Speech)模型依赖于将语音信号离散化为“音素”或“语音标记”——这一过程虽然便于建模,但也带来了固有局限: 声音细节丢失、韵律不自然、跨说话人迁...语音模型# TTS# VoxCPM# 面壁智能5个月前04760
字节跳动与浙大联合发布轻量高效TTS模型MegaTTS3字节跳动和浙江大学的研究人员推出的一款轻量级TTS模型:MegaTTS3,0.45B,高质量语音克隆,支持中英文以及中英文混合,支持口音强度控制,后面会支持更细粒度的发音和时长调整。 GitHub:h...语音模型# MegaTTS3# TTS模型# 字节跳动11个月前04730
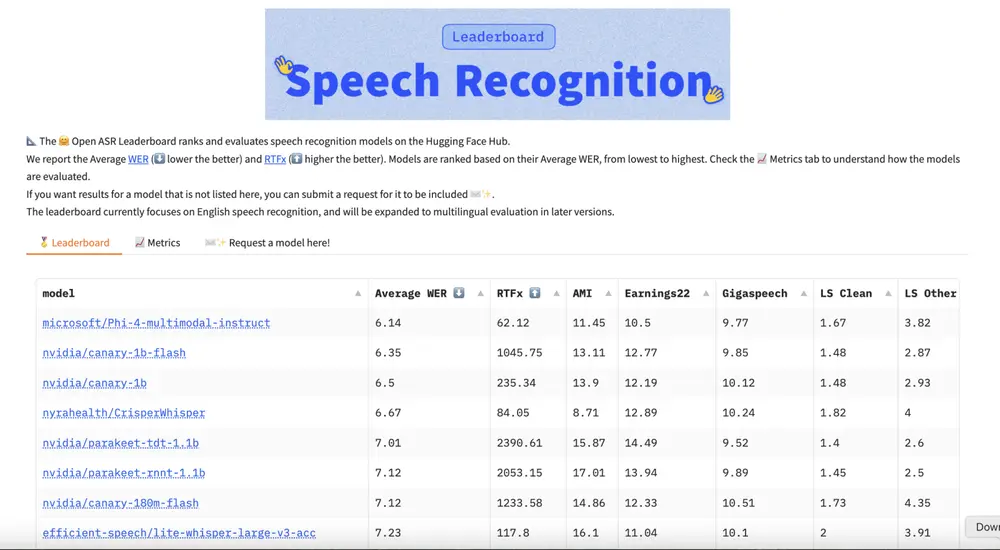
英伟达开源多语言语音识别和翻译模型:Canary 1B Flash 和 Canary 180M Flash在促进全球交流的进程中,多语言语音识别和翻译技术扮演着至关重要的角色。然而,开发能够实时准确地转录和翻译多种语言的模型面临着诸如处理语言细微差别、确保高准确性与低延迟以及实现跨设备高效部署等挑战。为应...语音模型# Canary 180M Flash# Canary 1B Flash# 多语言语音识别11个月前04650
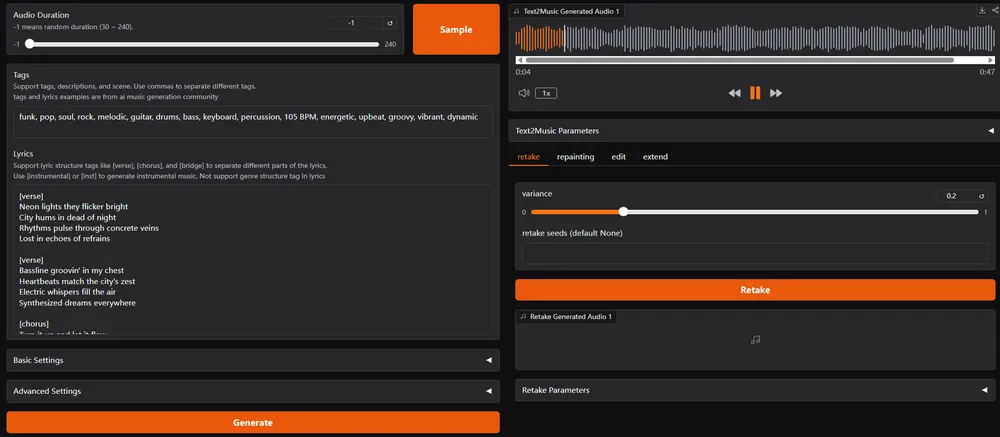
音乐生成基础模型ACE-Step:通过创新的整体架构设计,快速生成高质量音乐ACE Studio和阶跃星辰(StepFun)联合推出了一款全新的开源音乐生成基础模型ACE-Step,该模型通过创新的整体架构设计,突破了现有方法的局限性,实现了卓越的性能表现。 GitHub:h...语音模型# ACE-Step# 音乐模型10个月前04520