GPT-IMAGE-EDIT-1.5M:用 GPT-4o 重构开源图像编辑数据集在图像生成领域,闭源模型如 GPT-4o、IDEF-2 和 DALL·E 3 已展现出令人惊叹的指令遵循能力,能够精准执行复杂的文本引导编辑任务。相比之下,开源社区虽有进展,却始终受限于高质量、大规模...图像模型# GPT-Image-Edit# GPT-IMAGE-EDIT-1.5M# 图像编辑模型8个月前01860
腾讯混元项目组联合北京大学提出新框架MixGRPO:用混合微分方程提升图像对齐效率在图像生成领域,如何让模型输出更符合人类审美与偏好,已成为对齐研究的核心目标。基于流匹配(Flow Matching)的生成模型近年来展现出强大潜力,而 Group Relative Policy O...图像模型# MixGRPO8个月前03660
黑森林实验室联合 KREA AI 发布 FLUX.1 Krea [dev]: 实现更真实、更自然的图像生成黑森林实验室(Black Forest Labs, BFL)与创意 AI 平台 KREA AI 正式宣布推出 FLUX.1 Krea [dev] —— 一个全新的开源文本到图像生成模型,也是 Krea...图像模型# FLUX.1 Krea [dev]# 图像生成# 黑森林实验室8个月前05900
腾讯混元提出 X-Omni:用强化学习突破离散自回归图像生成瓶颈在当前多模态生成模型的发展中,研究者始终在探索一个统一的建模范式:能否用类似语言模型“预测下一个词”的方式,来生成图像?这种被称为“下一令牌预测(next-token prediction)”的自回归...图像模型# X-Omni# 腾讯混元8个月前05060
Anzhc 开源系列 YOLO 模型:专注细粒度图像分割与分类任务在图像检测与分割领域,高质量的专用模型往往能显著提升下游任务的表现。开发者 Anzhc 基于自建标注数据集,训练并开源了一系列面向特定视觉任务的 YOLO 模型,涵盖面部、眼部、头部、胸部等细粒度目标...图像模型# YOLO 模型# 图像分割9个月前06370
南洋理工大学 S-Lab 提出新型对象移除框架ObjectClear ,精准消除物体及其阴影、反射在图像编辑任务中,移除一个物体看似简单,实则极具挑战。 不仅要将目标对象从画面中“擦除”,还需同步清除其带来的视觉副产物——如阴影、倒影、高光、遮挡痕迹等。若处理不当,即便主体消失,残留的影子或反光仍...图像模型# ObjectClear# 南洋理工大学# 对象移除9个月前04700
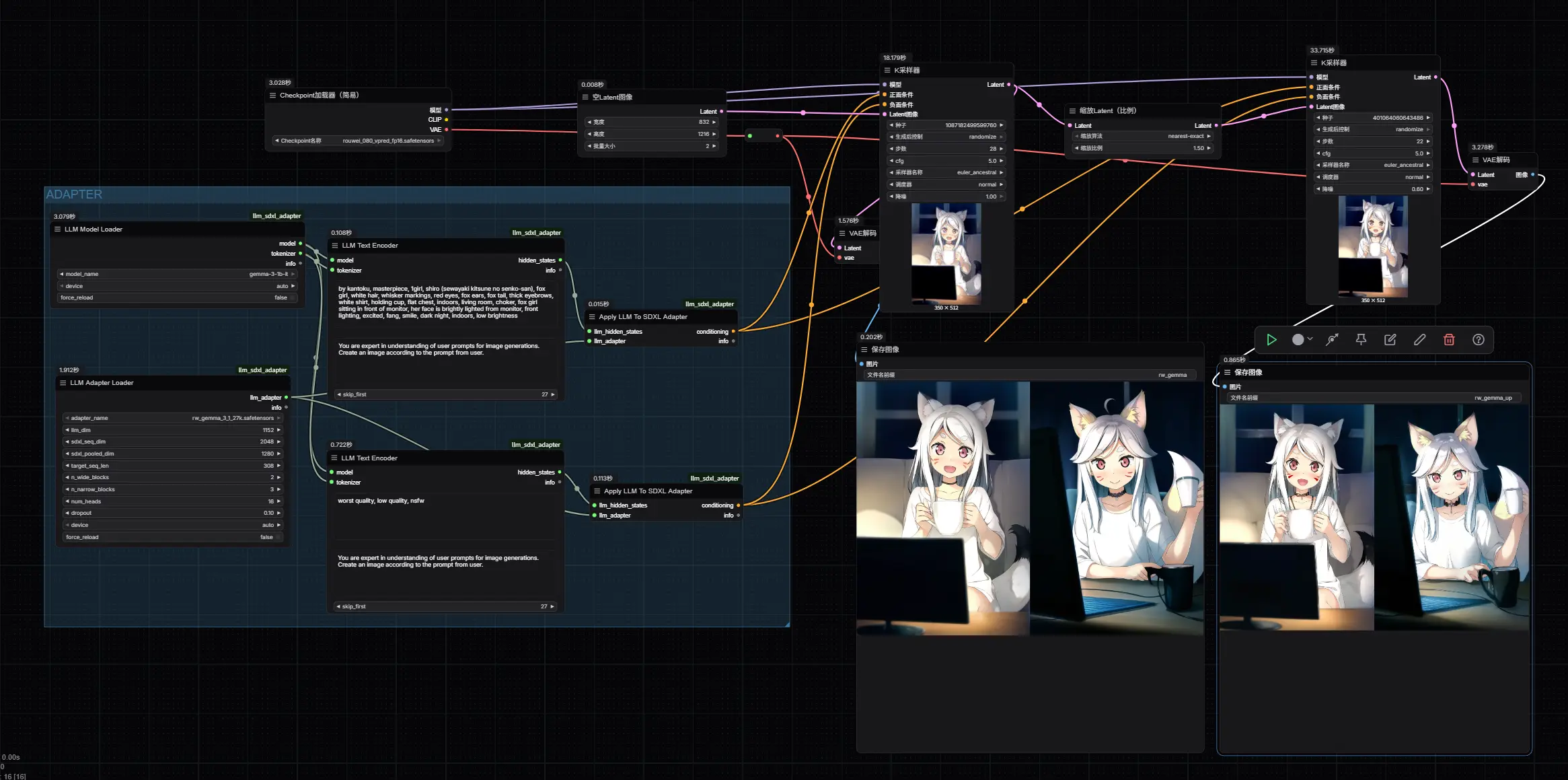
RouWei-Gemma:基于 Gemma-3-1b 的文本编码器适配器(用于 Rouwei 0.8)RouWei-Gemma是一个为 Rouwei 0.8 开发的文本编码器适配器,基于 Gemma-3-1b 构建,用于替换 SDXL 中的 CLIP 文本编码器。它利用大语言模型(LLM)的强大语义理...图像模型# Gemma-3-1b# Rouwei 0.8# RouWei-Gemma9个月前03280
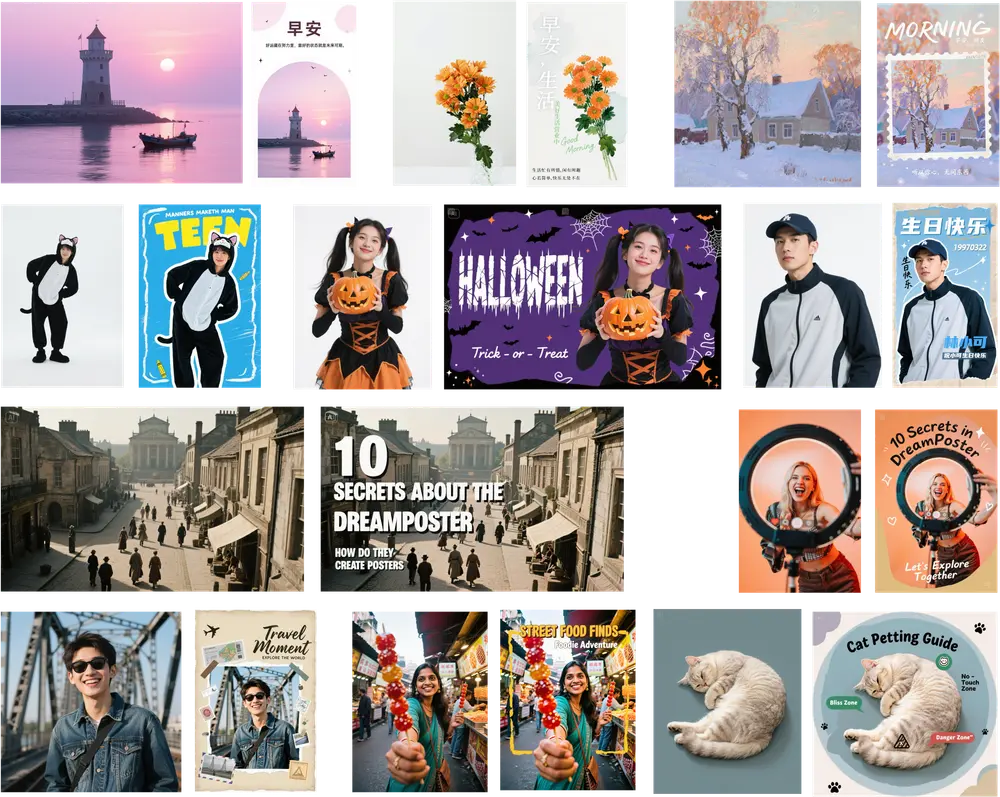
字节跳动 & 复旦大学联合提出智能海报生成新框架 DreamPoster在 AI 生成图像(AIGC)领域,海报设计一直是极具挑战性的任务之一。它不仅要求模型理解文本描述,还需要兼顾视觉美感、排版逻辑和品牌一致性。近日,字节跳动与复旦大学的研究团队联合提出了一种新的文本...图像模型# DreamPoster# 字节跳动# 海报设计9个月前04580
T-LoRA:基于时间步敏感机制的扩散模型个性化定制方法在图像生成任务中,扩散模型凭借强大的表达能力成为主流方案。然而,在仅有一张图像作为训练样本的情况下,模型容易出现过拟合现象,导致生成结果过度依赖原始图像背景或姿态,而无法很好地响应文本提示。 为此,研...图像模型# T-LoRA9个月前01180
NovelAI 正式公开了其基于SD1.5的第二代图像生成模型 NovelAI Diffusion V2NovelAI 正式公开了其第二代图像生成模型 NovelAI Diffusion V2 的权重文件,供研究、个人使用及历史保存。这一举动意味着即使该模型在 NovelAI 官网停止服务后,用户仍可通...图像模型# NovelAI Diffusion V2# SD1.59个月前03840
阿里Ovis团队发布统一多模态模型Ovis-U1:理解、生成与编辑三位一体近日,阿里巴巴通义实验室Ovis团队正式发布了新一代统一多模态大模型——Ovis-U1。该模型以30亿参数为基础,实现了对多模态任务的全面覆盖,涵盖图像理解、文本到图像生成以及图像编辑三大核心能力。 ...图像模型# Ovis-U1# 统一多模态模型9个月前02830
BRIA AI 推出 Bria 3.2:专为商业设计的下一代文本到图像模型BRIA AI 正式发布其最新文本到图像模型 Bria 3.2。作为一款专为企业和商业应用打造的生成模型,Bria 3.2 凭借仅 40 亿参数 的轻量架构,在美学效果与文本渲染能力方面表现优异,经评...图像模型# Bria 3.2# BRIA AI9个月前01820


![黑森林实验室联合 KREA AI 发布 FLUX.1 Krea [dev]: 实现更真实、更自然的图像生成](https://pic.sd114.wiki/wp-content/uploads/2025/08/1753986665-1753986665-FLUX-Krea-2.webp~tplv-o4t1hxlaqv-image.image)