Stable Diffusion 1.5Stable Diffusion 1.5 是由 Runway ML 开发,基于 Stable Diffusion 1.2 版本,于2022年10月发布,并进行了以下改进: 使用了更大的模型:Stabl...图像模型# Runway ML# Stable Diffusion 1.5# 模型1年前01,0370
华为PixArt系列最新模型—PIXART-Σ:基于DiT,可直接生成4K分辨率的图像来自华为诺亚方舟实验室、大连理工大学、香港大学的研究人员推出了最新的PixArt模型—PIXART-Σ,PixArt-Σ基于Diffusion Transformer架构 (DiT,与Sora、Sta...图像模型# DiT# PIXART-Σ# 文生图模型1年前01,0310
Neta Lumina 发布:专为二次元创作打造的高品质图像生成模型由捏Ta实验室(Neta.art)训练的 Neta Lumina 是一款专注于二次元风格的高质量图像生成模型。此模型基于上海人工智能实验室 Alpha-VLLM 团队开源的 Lumina-Image...图像模型# Neta Lumina# 二次元8个月前09970
文生图模型新架构MoA:根据用户的个性化需求生成包含特定人物的图像,同时保持原有模型的风格和多样性Snap推出新架构注意力混合(Mixture-of-Attention,简称MoA),即在个性化图像生成中实现主体与上下文解耦的注意力混合模型(MoA),用于个性化文本到图像的扩散模型。简单来说,Mo...图像模型# MoA# 文生图模型1年前09920
图像修复模型BrushNet:使用分解的双分支扩散方法来进行图像内容的恢复和编辑来自腾讯PCG ARC实验室和香港中文大学的研究团队推出新型图像修复(inpainting)模型BrushNet,它使用了分解的双分支扩散(diffusion)方法来进行图像内容的恢复和编辑。图像修复...图像模型# BrushNet# 图像修复1年前09650
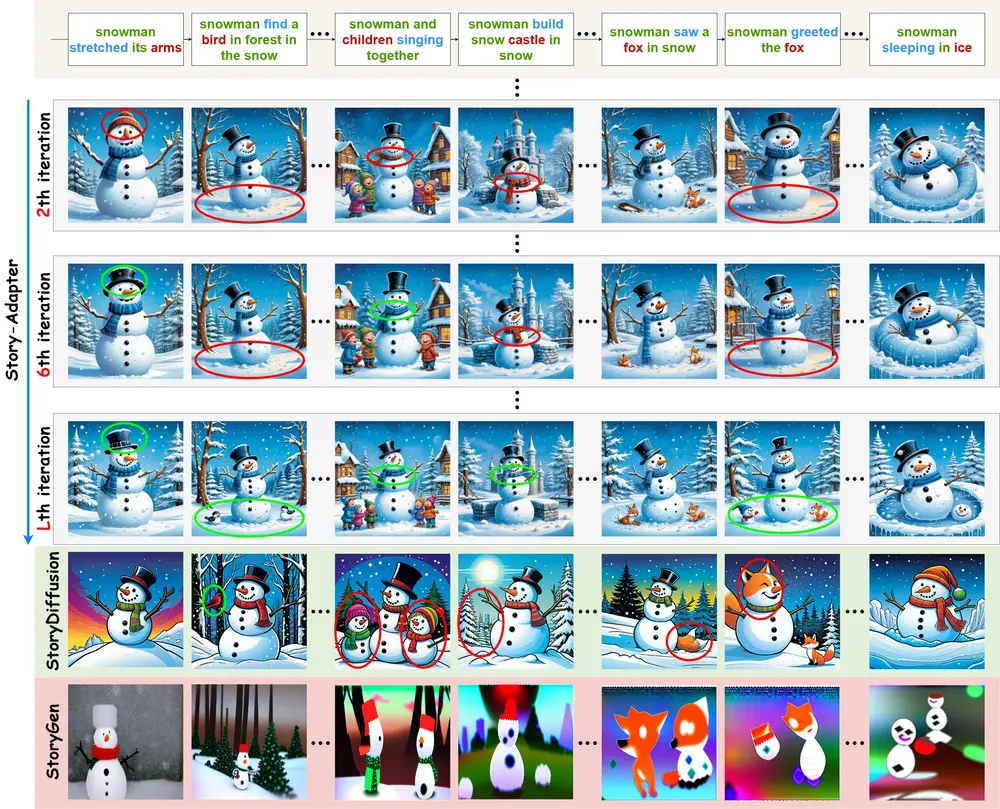
用于长篇故事视觉化的迭代框架Story-Adapter:根据长篇故事的文字描述生成一系列既连贯又具有丰富细节的图像加州大学圣克鲁斯分校、杭州电子科技大学和新加坡理工学院的研究人员推出一个用于长篇故事视觉化的迭代框架Story-Adapter,Story-Adapter能够根据长篇故事的文字描述生成一系列既连贯又具...图像模型# Story-Adapter# 长篇故事视觉化1年前09540
新型图像生成模型MoMA:具有灵活的零样本能力,专注于主体驱动的个性化图像生成来自字节跳动和罗格斯大学的研究人员推出新型图像生成模型MoMA(Multimodal LLM Adapter),这是一个开放词汇、无需训练的个性化图像模型,具有灵活的零样本能力,专注于主体驱动的个性化...图像模型# MoMA# 个性化图像生成# 文生图模型1年前09480
强大且高效的图像和视频生成控制方法ControlNeXt:同时支持图像和视频,并能整合多种形式的控制信息香港中文大学和思谋科技的研究人员推出强大且高效的图像和视频生成控制方法ControlNeXt,它同时支持图像和视频,并能整合多种形式的控制信息。在这个项目中,我们提出了一种新方法,与 ControlN...图像模型# ControlNeXt1年前09330
SD3-Turbo模型:在四步无指导采样的情况下,生成与最先进的文本到图像生成器相匹配的图像质量Stability AI还没发布Stable Diffusion 3,就已经发布了SD3-Turbo的技术论文,着重介绍了LADD技术,它是一种用于加速图像合成的新型蒸馏技术。 论文地址 SD3-Tu...图像模型# SD3-Turbo# Stability AI# Stable Diffusion 31年前09310
Jasper推出新型蒸馏方法Flash Diffusion:高效、快速、多用途且与LoRA兼容,旨在加速预训练扩散模型图像生成Jasper推出了一种高效、快速、多用途且与LoRA兼容,旨在加速预训练扩散模型生成的蒸馏方法Flash Diffusion,该方法在COCO 2014和COCO 2017数据集上,针对少量步骤的图像...图像模型# Flash Diffusion# Jasper# 蒸馏模型1年前08730
开源版GPT-4o!字节跳动开源新一代多模态模型 BAGEL:多模态理解、图像生成、图像编辑,还能“思考”字节跳动发布了一款名为 BAGEL 的开源多模态基础模型,该模型拥有 70 亿活跃参数(总规模为 140 亿),在大规模交错多模态数据上进行训练。BAGEL 不仅在标准多模态理解排行榜中超越了当前主流...图像模型# BAGEL# GPT-4o# 多模态模型9个月前08550
SDXL Turbo: 实时文本到图像生成模型Stability AI于北京时间2023年11月28日推出了新的开源文生图模型 SDXL Turbo,SDXL Turbo 是在 SDXL 1.0 的基础上采用新的蒸馏方案,让模型只需要一步就可以生...图像模型# LCM-XL# SDXL Turbo1年前08520