腾讯开源SongGeneration 2:歌词准确率超越 Suno v5,首个真正达到“商业级”的开源音乐大模型腾讯 AI 实验室重磅发布 LeVo 2 (SongGeneration 2) —— 一个旨在打破开源 AI 音乐天花板的基础模型。经过大规模、严格的专家盲测评估,LeVo 2 在音乐性、歌词准确性和...语音模型# SongGeneration 2# 腾讯7天前0870
EffectMaker:腾讯混元新作,无需微调即可“克隆”电影级特效,让普通人也能做 VFX 大师“好莱坞大片里那些令人震撼的火焰、冰霜、能量波,曾经需要数百万美元和数年训练才能制作。现在,只需一段参考视频和一张照片,AI 就能为你‘克隆’出同样的奇迹。” 由 腾讯混元 (Tencent HunY...视频模型# AI特效# EffectMaker1周前0130
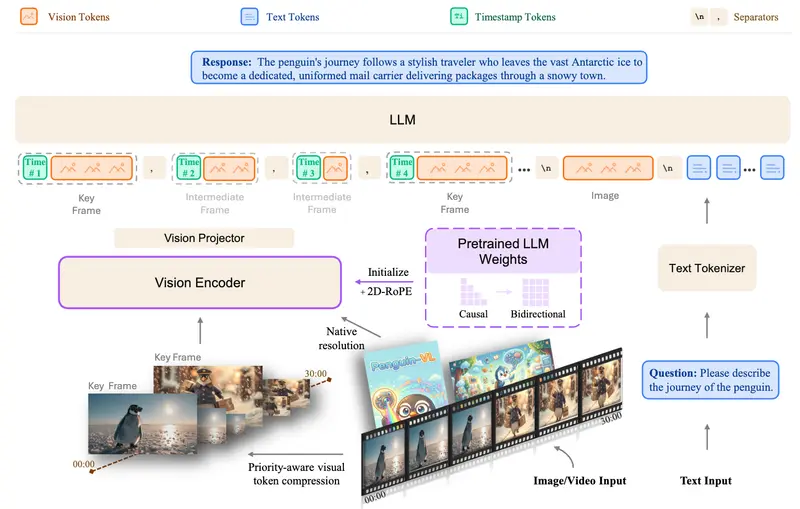
腾讯开源 Penguin-VL:抛弃 CLIP,用大语言模型初始化视觉编码器,重塑多模态效率极限“当所有人都在堆砌数据和参数时,腾讯选择了一条更本质的路:重新设计视觉编码器,让‘看’和‘想’在同一个空间里对话。” 在视觉语言模型(VLM)领域,主流范式长期依赖通过大规模对比学习(如 CLIP、S...多模态模型# Penguin-VL# Penguin-VL-2B# Penguin-VL-8B1周前0260
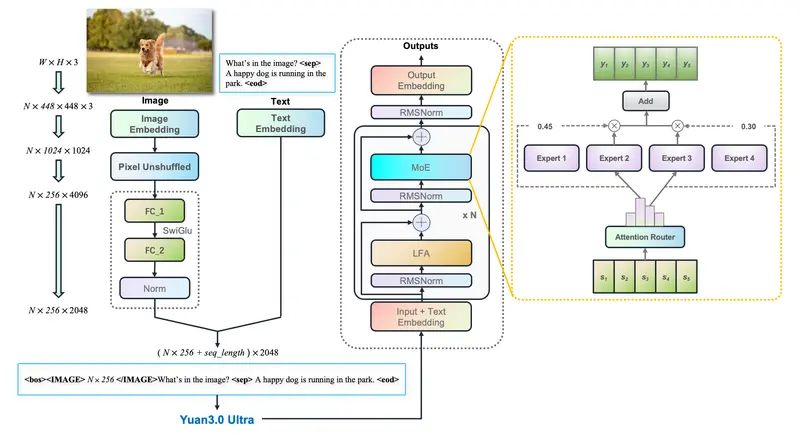
浪潮开源源 3.0 Ultra:1515B 参数巨无霸瘦身至 68B 激活,企业级 RAG 与表格理解全面超越 GPT-4o“大模型的未来不在于无限堆砌参数,而在于如何让每一分算力都产生价值。” 浪潮旗下 YuanLab.ai 团队正式开源 源 3.0 Ultra (Yuan3.0 Ultra)。这是一款从零开始预训练的超...多模态模型# Yuan3.0 Ultra# 浪潮# 源 3.0 Ultra1周前0720
微软发布 Phi-4-Reasoning-Vision-15B:150 亿参数的“小而美”多模态推理专家在视觉语言模型(VLM)竞相追逐千亿参数、万亿训练词元的今天,微软反其道而行之,发布了 Phi-4-reasoning-vision-15B。 官方介绍:https://www.microsoft.c...多模态模型# Phi-4-Reasoning-Vision-15B# 微软1周前0200
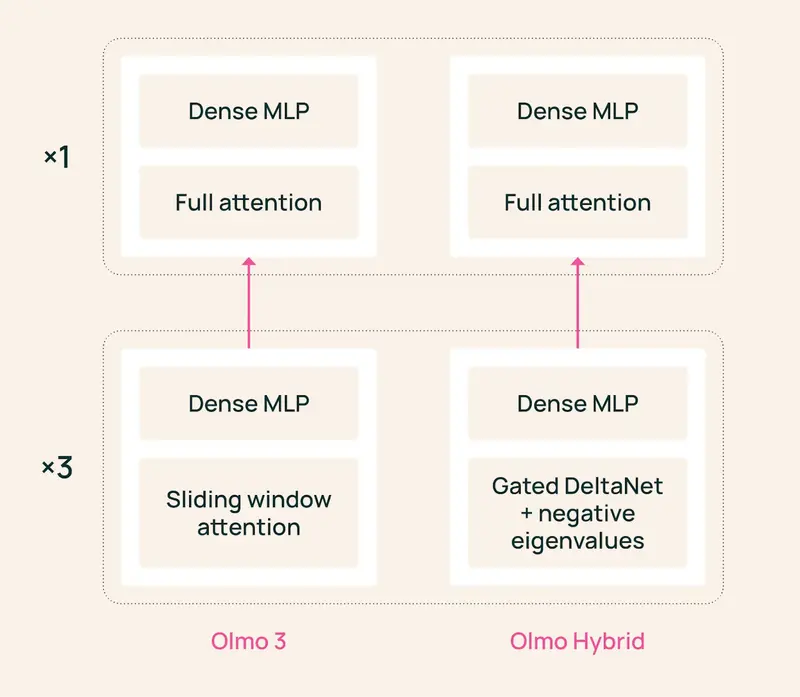
Ai2 发布 Olmo Hybrid:混合架构的“效率革命”,用一半数据训练出同等能力的 7B 模型“如果 Transformer 是记忆大师,线性 RNN 是状态追踪者,那么混合模型就是集两者之大成的‘全能选手’。” 艾伦AI研究所(Ai2)今日正式发布了 Olmo Hybrid,这是一个全新的 ...大语言模型# Olmo Hybrid# 艾伦AI研究所1周前0190
印度SarvamAI 开源 30B/105B 推理模型,全栈自研挑战全球巨头印度初创公司 SarvamAI 开源了其旗舰推理模型系列:Sarvam 30B 和 Sarvam 105B。这两个模型不仅是目前印度本土构建的最大规模开源模型,更代表了全球范围内罕见的全栈自研(Ful...大语言模型# Sarvam 105B# Sarvam 30B# SarvamAI1周前0410
Luma 发布统一推理图像模型UNI-1:终结“理解”与“生成”的割裂,首个统一推理视觉模型登场“过去的 AI 是‘先看懂,再画出来’的两个步骤;现在的 UNI-1 是‘边想边画,画即是想’的一个过程。” Luma AI 今日正式推出 UNI-1,这是业界首个将视觉理解与图像生成深度融合的统一推...图像模型早报# Luma# UNI-11周前0390
OpenAI 发布 GPT-5.4:原生“计算机使用”能力觉醒,智能体正式接管复杂工作流“它不再只是陪你聊天的机器人,而是能真正操作你电脑、编写并调试代码、处理复杂报表的数字员工。” OpenAI 正式推出 GPT-5.4,这是 GPT-5 系列中迄今为止最强大的通用模型。它不仅继承了 ...大语言模型早报# GPT-5.4# OpenAI# 智能体1周前0160
Lightricks 双重重磅发布:LTX-2.3 模型进化与 LTX Desktop 开源编辑器,本地视频生成时代正式来临Lightricks 今日宣布同步推出两项里程碑式产品:LTX-2.3,一个经过实战打磨、架构全面升级的视频生成模型;以及 LTX Desktop,一款直接构建于该引擎之上的生产级本地视频编辑器。 这...早报视频模型# Lightricks# LTX Desktop# LTX-2.32周前01540
小红书开源FireRed-Image-Edit 1.1:引入智能体工作流,支持 10+ 元素融合与专业级人像精修小红书智能创作基础技术团队正式推出 FireRed-Image-Edit-1.1。作为前代通用图像编辑模型的升级版,1.1 版本在保留强大编辑能力的基础上,重点攻克了身份一致性、多图像复杂控制及领域专...图像模型# FireRed-Image-Edit 1.1# 小红书2周前0830
谷歌 Gemini 3.1 Flash-Lite 发布:首字速度快 2.5 倍,每百万输入仅$0.25,重新定义高性价比 AI在 AI 模型竞相追求更大参数、更强能力的今天,谷歌反其道而行之,推出了 Gemini 3.1 Flash-Lite。这款专为高容量、低延迟、低成本场景打造的新模型,旨在证明:在速度与效率的赛道上,轻...大语言模型早报# Gemini 3.1 Flash-Lite# 谷歌2周前0300