黑森林实验室发布FLUX.2 :支持400万像素编辑+10图参考,开放权重模型刷新视觉AI上限在视觉AI领域,能够真正适配现实世界创意工作流的工具,往往比单纯的“演示级模型”更具价值。近日,黑森林实验室正式推出新一代视觉智能系统 FLUX.2,不仅在图像生成质量、细节还原度上实现突破,更以多参...图像模型# FLUX.2# 黑森林实验室2个月前0800
微软推出Fara - 7B模型:70亿参数本地运行,专为计算机使用代理 (CUA) 设计的小型语言模型微软正式推出首款专为计算机使用代理(CUA)设计的小型语言模型Fara - 7B。这款仅70亿参数的模型跳出了对大规模云端模型的依赖,凭借可本地运行的特性,在降低延迟的同时筑牢数据隐私防线,更以独特的...大语言模型# Fara - 7B# 微软# 计算机使用代理2个月前0150
Anthropic 发布 Claude Opus 4.5:宣称全球最佳编程模型,API 降价+多平台同步上线Anthropic 今日正式发布旗舰级 AI 模型 Claude Opus 4.5,聚焦编程、代理任务与计算机使用场景,凭借多项核心突破重塑行业标杆。该模型不仅在 SWE-bench Verified...大语言模型# Anthropic# Claude Opus 4.5# 编程模型2个月前0280
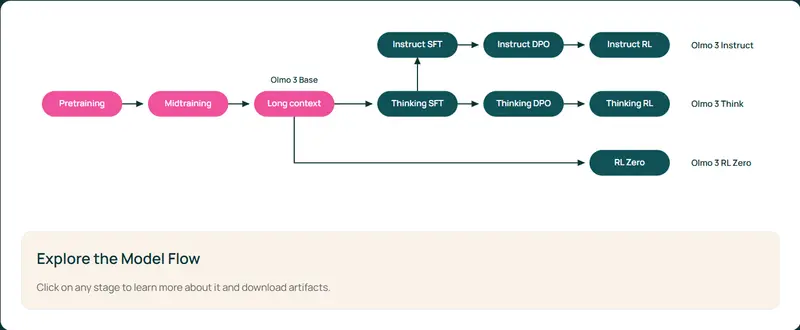
艾伦AI研究所发布Olmo 3系列模型:完全开放的推理模型,训练数据与中间步骤全透明在开源AI领域,“开放”往往局限于最终模型权重的分享,而模型训练的数据、流程、中间检查点等核心环节仍处于“黑箱”状态。Ai2(艾伦人工智能研究所)最新发布的 Olmo 3 系列模型,彻底打破了这一现状...大语言模型# Olmo 3# 艾伦AI研究所2个月前01920
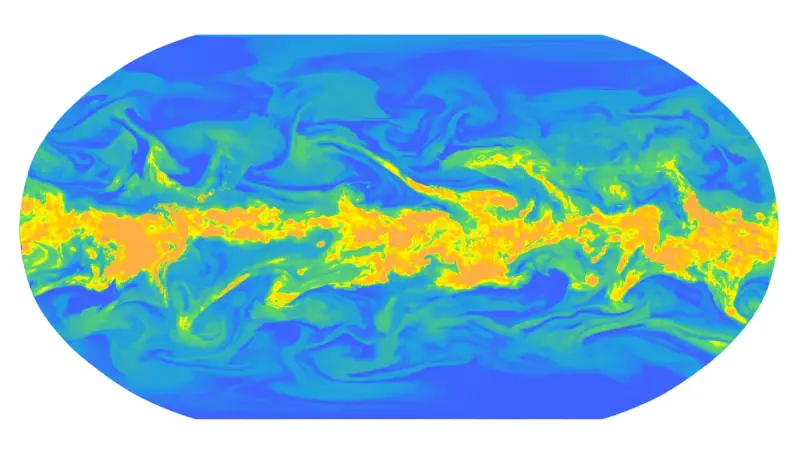
谷歌发布 WeatherNext 2:AI 天气预报模型速度提升 8 倍,精准到小时级谷歌DeepMind与Google Research联合发布全新AI天气预报模型WeatherNext 2,定位为“迄今最先进、最高效的全球天气预报解决方案”。该模型以“速度提升8倍、分辨率达小时级...多模态模型# WeatherNext 2# 天气预报# 谷歌2个月前0580
推理能力再飞跃!Gemini 3正式发布:多模态拉满+代理编码,6.5亿用户可直接使用谷歌今天正式发布新一代旗舰大模型 Gemini 3,这是其继 Gemini 2.5 发布七个月后推出的重磅升级版本,也是迄今最强大的大语言模型。此次发布距离 OpenAI GPT-5.1、Anthro...大语言模型早报# Gemini 3# 谷歌2个月前0670
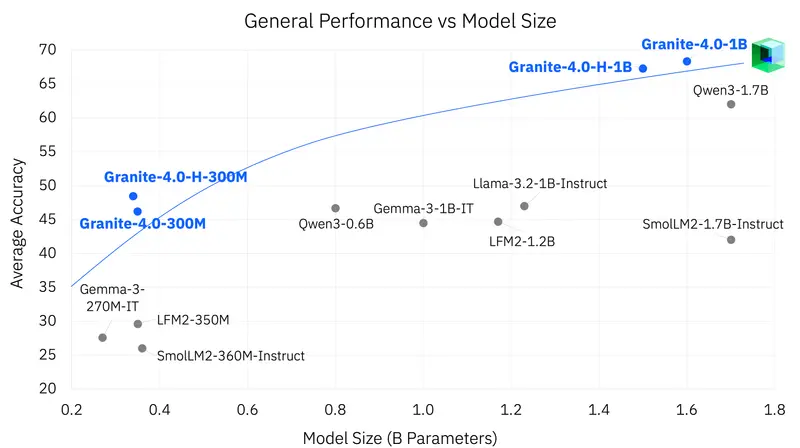
IBM 发布 Granite 4.0 Nano:350M-1.5B 参数边缘模型,混合SSM架构+Apache 2.0开源,性能超越同尺寸竞品在边缘计算与设备端AI需求日益增长的今天,“小模型能否实现强能力”成为行业核心诉求。近日,IBM 正式推出 Granite 4.0 Nano 系列模型——作为 Granite 4.0 家族的全新成员...大语言模型# Granite 4.0 Nano# IBM2个月前0170
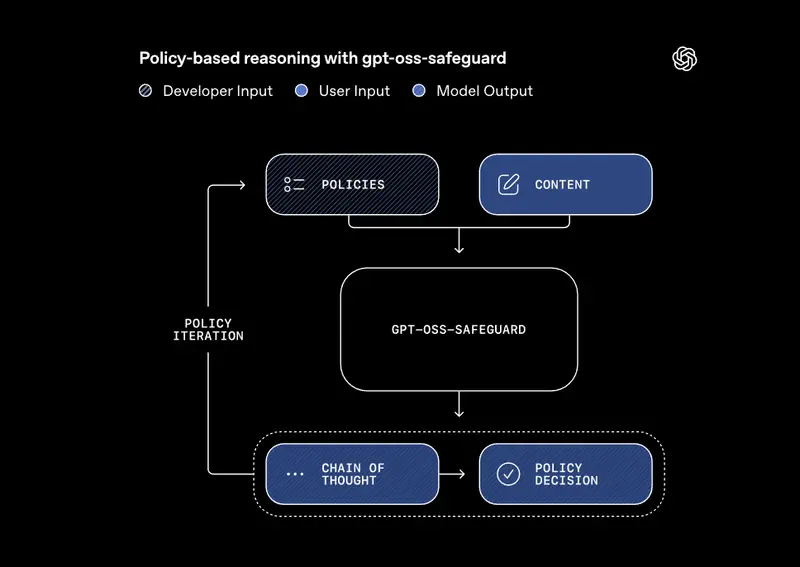
OpenAI 开源安全推理模型gpt-oss-safeguard:自定义策略+可解释推理,多策略准确率超越 GPT-5-thinking在AI内容安全领域,传统分类器“依赖标注样本、策略更新繁琐”的痛点长期困扰开发者。OpenAI 正式发布 gpt-oss-safeguard 研究预览版——一款开源权重的安全推理模型,以“自定义策略...大语言模型# gpt-oss-safeguard# OpenAI2个月前0120
谷歌 DeepMind 发布 SIMA 2:AI智能体首次在虚拟世界中“自我改进”谷歌DeepMind发布通用AI智能体下一代产品SIMA 2的研究预览,通过深度整合大语言模型Gemini的语言与推理能力,实现从“单纯遵循指令”到“理解环境并互动”的核心突破。这款由Gemini 2...多模态模型# SIMA 2# 谷歌 DeepMind3个月前0310
OpenAI 发布 GPT-5.1:8 种个性语调可选,Instant 更温暖、Thinking 更智能继8月GPT-5发布引发争议后,OpenAI今日正式推出旗舰模型更新版——GPT-5.1,通过双模型优化、8种个性语调预设、自适应推理等核心升级,旨在解决前代模型“体验平平”“缺乏个性化”的问题,让C...大语言模型# GPT-5.1# OpenAI3个月前01030
百度开源ERNIE-4.5-VL-28B-A3B-Thinking:3B活跃参数实现大型模型级多模态推理百度正式开源 ERNIE-4.5-VL-28B-A3B-Thinking,一款专注于文档、图表与视频理解的多模态推理模型。尽管模型总参数达 约 30B,但通过稀疏激活机制,每次推理仅激活 3B 参数...多模态模型# ERNIE-4.5-VL-28B-A3B-Thinking# 多模态推理# 百度3个月前0270
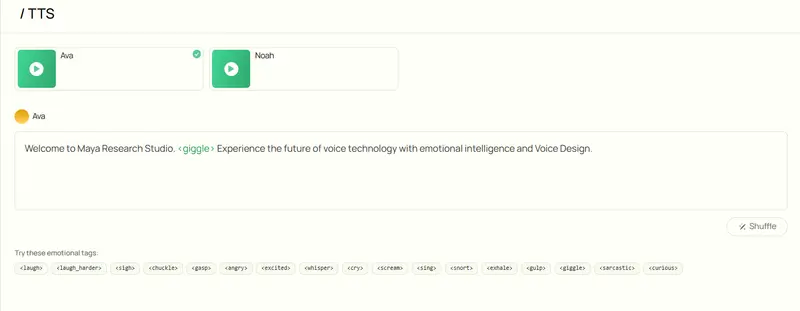
Maya1:开源 3B 语音模型,支持自然语言控制与情感标签的文本到语音生成Maya Research 近期发布了一款突破性的开源文本到语音(TTS)模型——Maya1。这款仅3B参数的模型,不仅能将文本与自然语言描述转化为富有情感的24kHz高质量语音,还支持单GPU实时运...语音模型# Maya1# 语音模型3个月前0580