腾讯推出全新MoE模型Hunyuan-A13B:小参数、高性能的AI新选择在大模型持续演进的过程中,如何在提升性能的同时控制资源消耗,成为行业面临的关键挑战。腾讯最新推出的 Hunyuan-A13B 模型,正是这一问题的创新性解决方案。该模型采用混合专家(MoE)架构,在仅...大语言模型# Hunyuan-A13B# 腾讯8个月前01540
阿里通义实验室推出的端到端网络代理训练框架WebDancer在信息检索和智能代理领域,如何让 AI 代理具备自主搜索、推理和决策能力是一个关键挑战。为此,阿里通义实验室提出了 WebDancer —— 一个全新的 端到端代理训练框架,旨在增强基于网络的代理在多...大语言模型# WebDancer# 阿里通义实验室8个月前02750
国内首个专攻K-12数学教育的大模型开源!网易有道发布“子曰3数学模型”,可在单卡消费级显卡运行网易有道宣布正式开源其“子曰3”系列大模型中的 数学推理专用模型——Confucius3-Math(中文名:子曰3数学模型),这是国内首个专注于 K-12 数学教育、且可在单块消费级 GPU(如 RT...大语言模型# Confucius3-Math# 子曰3数学模型# 网易有道8个月前02930
微软新推 Mu 模型:专为 Windows 设置代理而生的小而强语言模型微软近日推出了一款全新的小型语言模型——Mu,它专为边缘设备和特定任务设计,在本地运行时展现出卓越性能。目前,Mu 已经在 Copilot+ PC 的 Windows Insider 开发频道中,用于...大语言模型# Mu 模型# 微软8个月前02160
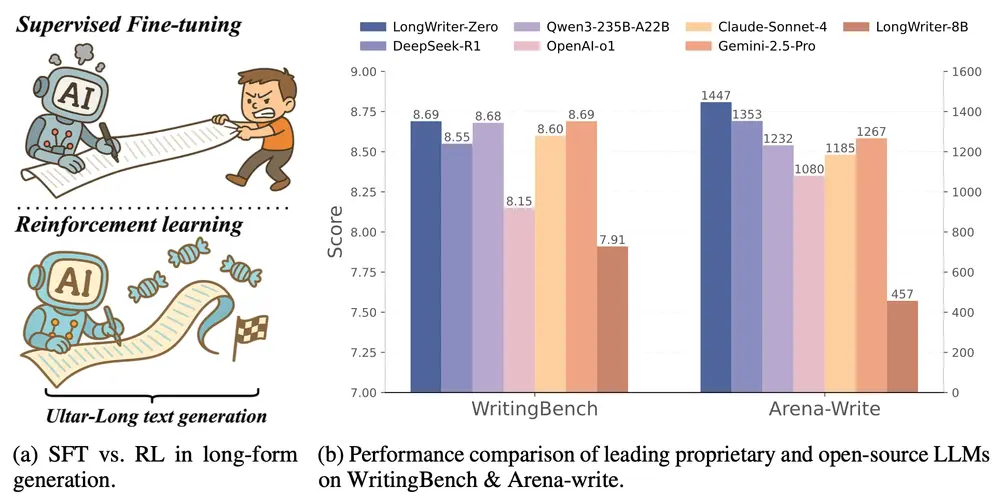
LongWriter-Zero:通过强化学习从零开始训练大语言模型,以实现超长文本生成新加坡科技设计大学和清华大学的研究人员推出新型模型LongWriter-Zero,基于 Qwen 2.5-32B-Base 构建,通过强化学习(RL)从零开始训练大语言模型(LLMs),以实现超长文本...大语言模型# LongWriter-Zero# 大语言模型8个月前02510
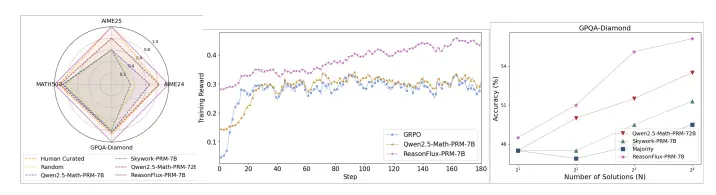
新型轨迹感知过程奖励模型(PRM) ReasonFlux-PRM:专门用于评估大型语言模型在长链推理中的轨迹-响应型推理痕迹伊利诺伊大学厄巴纳-香槟分校、普林斯顿大学、康奈尔大学和字节跳动的研究人员推出新型轨迹感知过程奖励模型(PRM) ReasonFlux-PRM,专门用于评估大型语言模型(LLMs)在长链推理(Long...大语言模型# ReasonFlux-PRM# 轨迹感知过程奖励模型8个月前02420
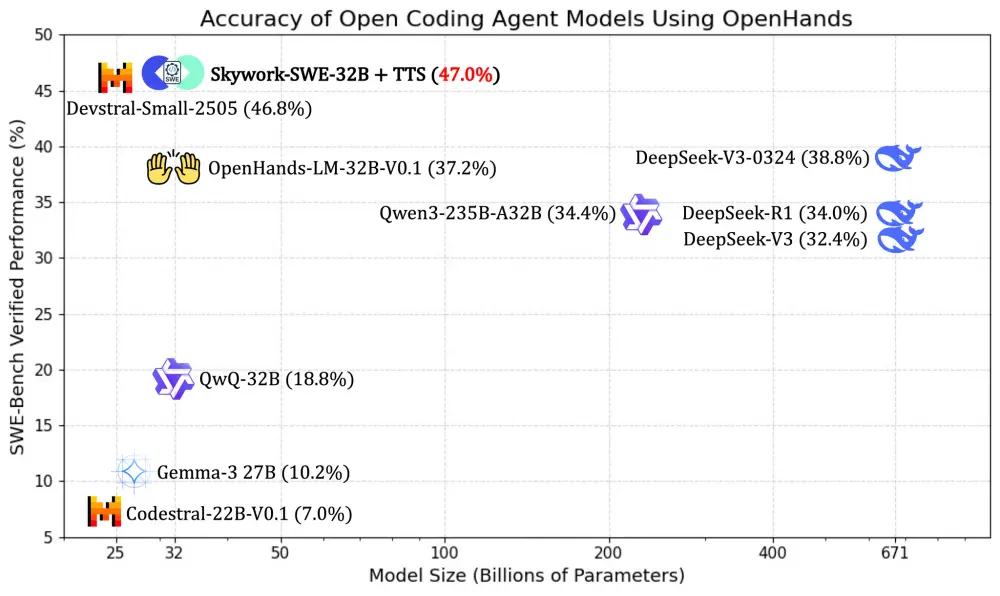
昆仑万维开源代码模型 Skywork-SWE-32B:用消费级显卡部署 AI 工程师的新可能今天,昆仑万维正式宣布开源其最新推出的代码智能体 Skywork-SWE-32B,该模型专为软件工程(SWE)任务设计,在 SWE-bench Verified 基准测试中达到 38.0% 的 pas...大语言模型# Skywork-SWE-32B# 代码模型# 昆仑万维8个月前03170
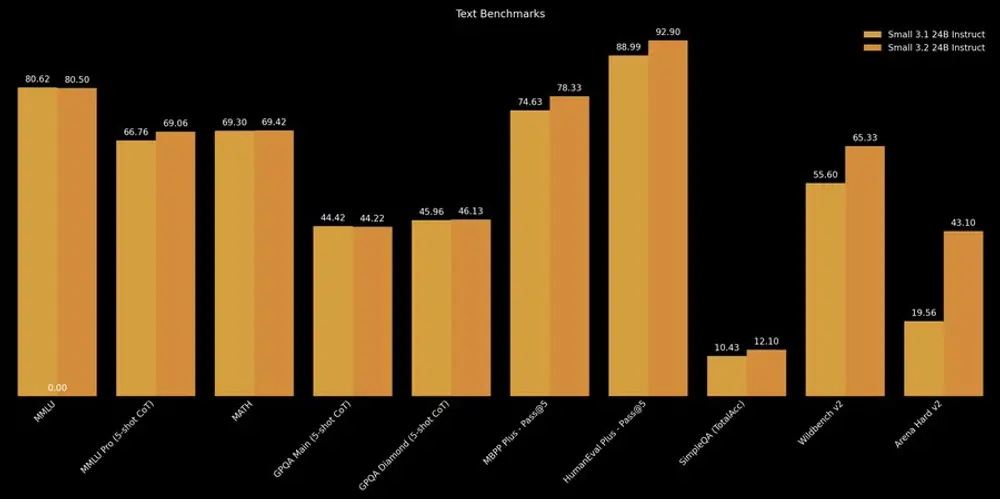
Mistral AI 发布 Mistral Small 3.2:小幅迭代,体验提升Mistral AI 推出了其中型模型系列的新版本——Mistral Small 3.2。这是对上一版 Mistral Small 3.1 的一次轻量级升级,在多个关键使用场景中带来了显著优化。 模型...大语言模型# Mistral AI# Mistral Small 3.28个月前01250
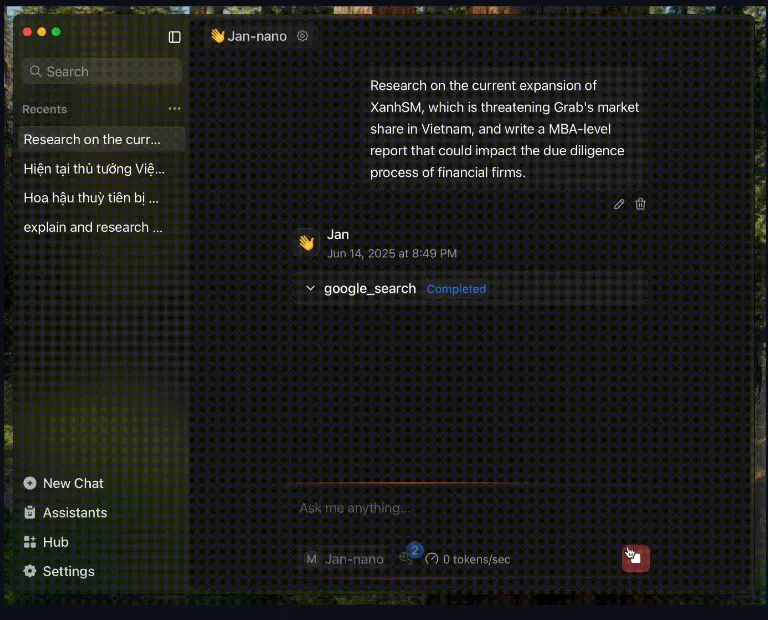
Jan-Nano:40亿参数的紧凑型研究专用语言模型正式上线Menlo发布一款专为深度研究任务设计的小型语言模型 Jan-Nano 。该模型拥有 40亿参数规模,在保证轻量级部署的同时展现出强大的推理能力。此模型基于 Qwen3-4B 构建,并经过 DAPO ...大语言模型# Jan-Nano# 小型语言模型8个月前03110
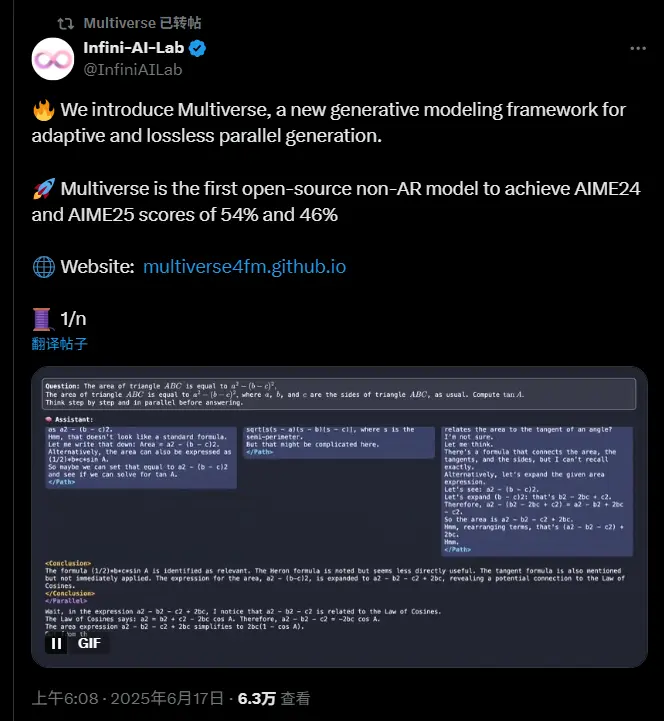
Multiverse:全球首个开源的非自回归并行推理框架,推理速度提升2倍卡内基梅隆大学与英伟达联合推出了一项具有突破性的生成模型框架——Multiverse。这是全球首个开源的非自回归(Non-Autoregressive)并行推理框架,在保持与主流自回归模型(AR-LL...大语言模型# Multiverse# 推理框架8个月前01920
MiniMax发布全球首款开源大规模混合注意力推理模型MiniMax-M1近日,MiniMax 宣布推出全新大语言模型 MiniMax-M1,这是全球首款开源的大规模混合注意力推理模型,专为复杂任务和长上下文场景设计。 GitHub:https://github.com/M...大语言模型# MiniMax# MiniMax-M18个月前02550
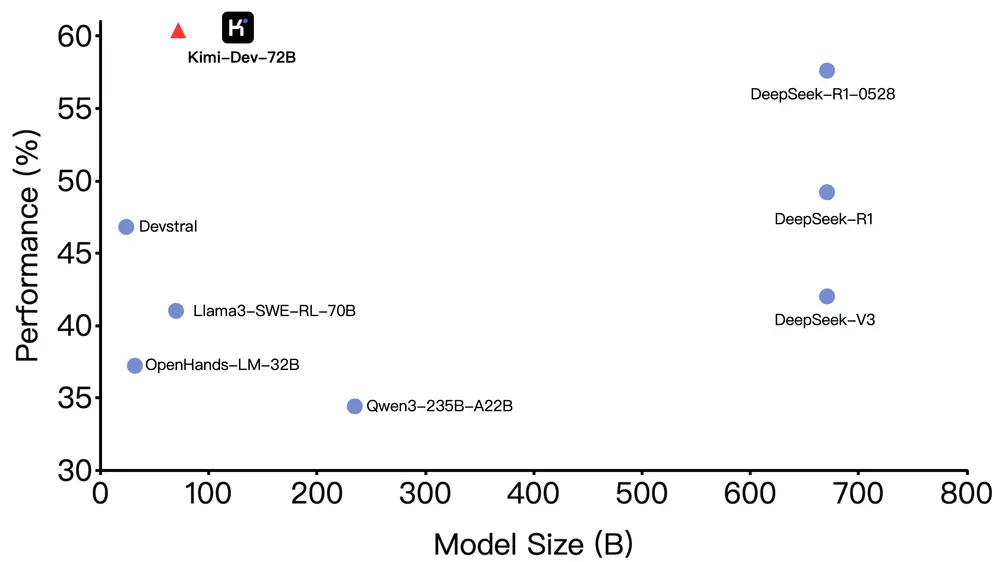
月之暗面推出Kimi-Dev-72B:为软件工程任务打造的新一代开源编码大模型月之暗面推出一款全新的开源编码大语言模型 Kimi-Dev-72B,专为软件工程任务设计。该模型基于 Qwen2.5-72B 微调而来,在 SWE-bench Verified 测试中取得了 60.4...大语言模型# Kimi-Dev-72B# 月之暗面8个月前03230