腾讯推出新型图生视频框架FlexiAct:实现灵活的视频动作克隆腾讯和清华大学的研究人员推出新型图生视频框架FlexiAct,实现灵活的动作控制,能够在异构场景(即具有不同空间结构、骨骼结构或视角的场景)中将参考视频中的动作迁移到任意目标图像上,同时保持动作动态和...视频模型# FlexiAct# 图生视频7个月前03050
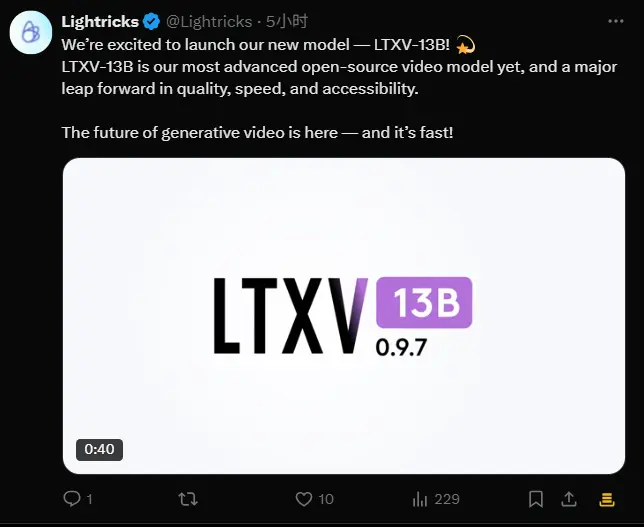
Lightricks 推出全新开源视频生成模型 LTXV-13BLightricks之前推出的都是小尺寸模型,而在今天它宣布推出其最新且最先进的开源视频生成模型——LTXV-13B,这一模型不仅在质量、速度和可访问性方面实现了显著提升,还为创作者提供了强大的工具...视频模型# Lightricks# LTXV-13B# 视频生成模型7个月前03750
基于两阶段框架的唇部同步方法KeySync:能够生成高分辨率、时间连贯且与音频对齐的视频,同时有效减少表情泄漏并处理面部遮挡唇部同步(Lip Synchronization)是指将视频中的唇部动作与新的输入音频对齐,使其在视觉上看起来自然且与音频同步。尽管这一领域与音频驱动的面部动画(Audio-driven Facial...视频模型# KeySync# 唇形同步# 唇部同步7个月前03170
新型事件增强型网络 Ev-DeblurVSR:从低分辨率(LR)和模糊的输入视频中恢复出高分辨率(HR)的清晰视频中国科学技术大学类脑智能感知与认知教育部重点实验室、合肥人工智能研究院和新加坡国立大学推出新型事件增强型网络 Ev-DeblurVSR ,旨在解决模糊视频超分辨率(BVSR)任务,即从低分辨率(LR...视频模型# Ev-DeblurVSR# 视频超分模型8个月前03070
Sand AI推出新型视频生成模型MAGI-1:通过自回归预测视频块序列来生成视频MAGI-1是由Sand AI研究团队开发的一种新型视频生成模型。该模型通过自回归预测视频块序列来生成视频,每个视频块由固定长度的连续帧组成。MAGI-1的核心目标是实现高保真、实时、因果一致的视频生...视频模型# MAGI-1# Sand AI# 自回归8个月前06540
昆仑万维推出SkyReels-V2:首个基于扩散强制框架的无限长度电影生成模型近年来,视频生成领域取得了显著进展,主要得益于扩散模型和自回归框架的推动。然而,这一领域仍面临诸多关键挑战,例如提示一致性、视觉质量、动态效果和视频时长之间的权衡。为了追求更高的视觉质量,许多模型不得...视频模型# SkyReels-V2# 昆仑万维# 视频生成模型8个月前03270
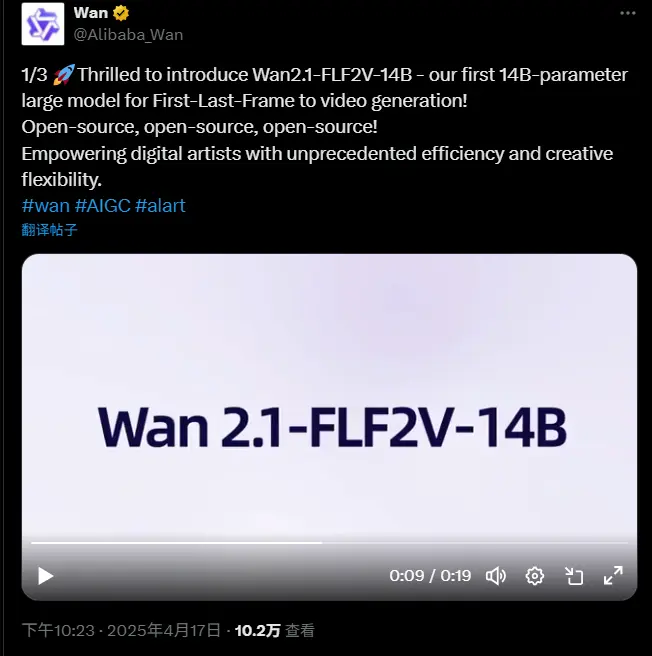
阿里巴巴通义实验室推出Wan2.1-FLF2V-14B:140亿参数的首尾帧到视频生成大模型阿里巴巴通义实验室近日开源了Wan2.1系列的首款大模型——Wan2.1-FLF2V-14B。这是一款专为首尾帧到视频生成设计的140亿参数大模型,旨在为数字艺术家提供前所未有的效率和创作灵活性。 模...视频模型# Wan2.1-FLF2V-14B# 视频生成大模型# 阿里巴巴8个月前03760
Lightricks 推出 LTX Video 0.9.6:更快、更稳定,助力创意视频生成Lightricks 在 5 个月前推出了视频生成模型 LTX Video。今天,官方宣布 LTXV 0.9.6 版本正式发布,为视频生成领域带来了新的突破。此次更新推出了 2B 参数开源视频模型的两...视频模型# LTX Video# LTXV 0.9.6# 视频生成模型8个月前04000
FramePack:用神经网络破解视频生成难题,能够将输入上下文压缩至固定长度,使生成工作量不受视频长度影响视频生成技术一直是AI领域的热门研究方向之一。然而,现有的视频生成模型在处理长视频时常常面临两大挑战:一是“遗忘”问题,模型难以记住早期的视频内容,导致生成的视频缺乏连贯性;二是“漂移”问题,随着视频...视频模型# controlnet# FramePack# Lvmin Zhang7个月前04140
新型视频法线估计模型 NormalCrafter :能够从任意长度的开放世界视频中生成具有时间一致性和细粒度细节的法线序列香港理工大学、腾讯 PCG ARC 实验室、香港城市大学和华中科技大学的研究人员推出新型视频法线估计模型 NormalCrafter ,它能够从任意长度的开放世界视频中生成具有时间一致性和细粒度细节的...视频模型# NormalCrafter# 视频法线估计模型7个月前03330
字节跳动推出视频生成模型Seaweed-7B:以较低的计算成本实现高效的训练和生成近年来,随着视频生成技术的快速发展,如何在资源有限的情况下实现高性能的模型训练成为研究热点。字节跳动提出了一种创新的训练策略,推出了一个中等规模的视频生成模型——Seaweed-7B。这个模型拥有约7...视频模型# Seaweed-7B# 字节跳动# 视频生成模型8个月前02580
基于 Mochi 微调的开源视频模型Pusa:低成本、高性能的开源视频生成模型Pusa 是基于 Mochi 微调的开源视频模型,不仅开源了整个微调过程,还以极低的训练成本(仅 100 美元)实现了多种视频生成任务的无缝支持。 GitHub:https://github.com...视频模型# Pusa# 视频生成模型8个月前01920