昆仑万维推出SkyReels-V2:首个基于扩散强制框架的无限长度电影生成模型近年来,视频生成领域取得了显著进展,主要得益于扩散模型和自回归框架的推动。然而,这一领域仍面临诸多关键挑战,例如提示一致性、视觉质量、动态效果和视频时长之间的权衡。为了追求更高的视觉质量,许多模型不得...视频模型# SkyReels-V2# 昆仑万维# 视频生成模型9个月前03860
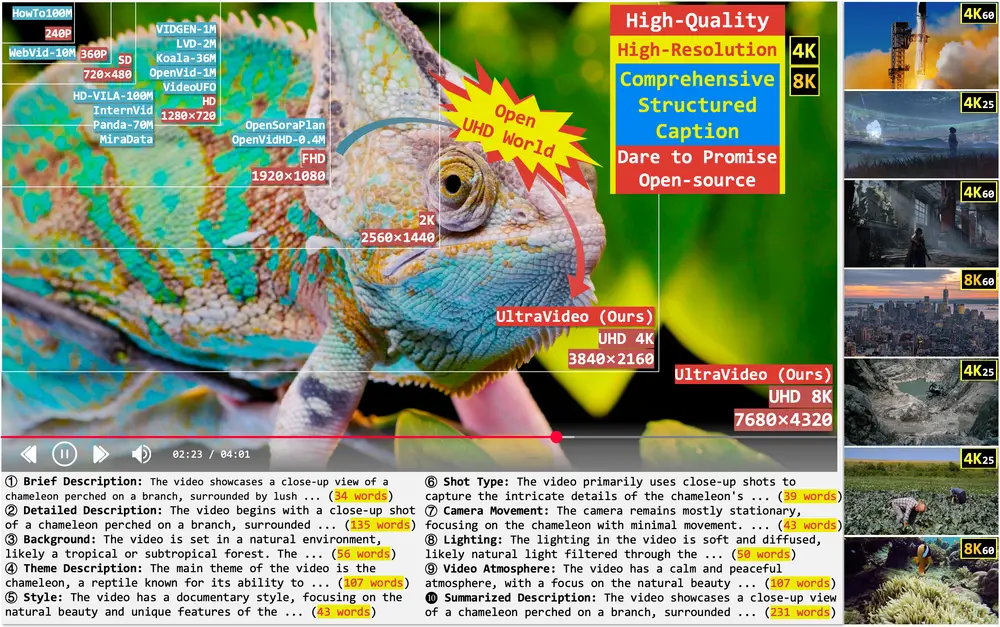
UltraVideo 与 UltraWAN:首个支持原生 UHD 视频生成的开源数据集与模型随着高质量视频内容需求的快速增长,如电影级超高清(UHD)制作、沉浸式媒体和短视频创作,对文本到视频(T2V)模型的能力提出了更高要求。 然而,现有公开数据集在分辨率、图像质量及字幕细节方面存在明显不...视频模型# UltraVideo# UltraWAN# UltraWanComfy7个月前03830
基于两阶段框架的唇部同步方法KeySync:能够生成高分辨率、时间连贯且与音频对齐的视频,同时有效减少表情泄漏并处理面部遮挡唇部同步(Lip Synchronization)是指将视频中的唇部动作与新的输入音频对齐,使其在视觉上看起来自然且与音频同步。尽管这一领域与音频驱动的面部动画(Audio-driven Facial...视频模型# KeySync# 唇形同步# 唇部同步9个月前03810
新型视频法线估计模型 NormalCrafter :能够从任意长度的开放世界视频中生成具有时间一致性和细粒度细节的法线序列香港理工大学、腾讯 PCG ARC 实验室、香港城市大学和华中科技大学的研究人员推出新型视频法线估计模型 NormalCrafter ,它能够从任意长度的开放世界视频中生成具有时间一致性和细粒度细节的...视频模型# NormalCrafter# 视频法线估计模型9个月前03800
DLoRAL:一种兼顾细节与时间一致性的视频超分辨率新方法在现实世界视频超分辨率(Real-VSR)任务中,如何从低质量(LQ)视频中恢复出既细节丰富又时间连贯的高质量(HQ)视频,是一个极具挑战性的问题。尤其是在使用预训练扩散模型(如 Stable Dif...视频模型# DLoRAL# 视频超分辨率7个月前03790
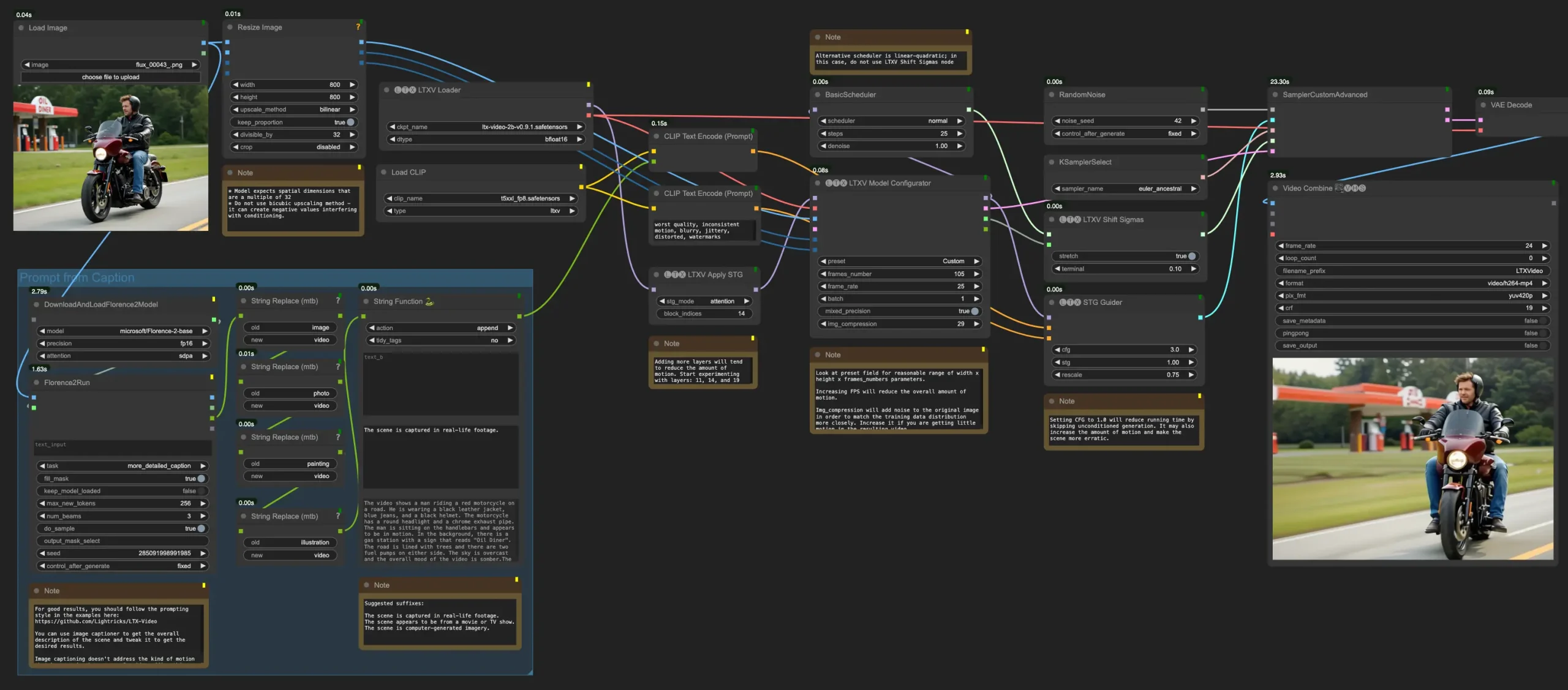
LTX-Video推出0.9.1版本,引入全新VAE解码器,原生支持STG/PAG之前介绍过的《Lightricks推出开源视频生成模型LTX Video》,今天LTX-Video迎来了它的首次重要更新——0.9.1版本。作为生成式AI视频模型的最新迭代,LTX-Video 0.9...视频模型# LTX-Video 0.9.112个月前03790
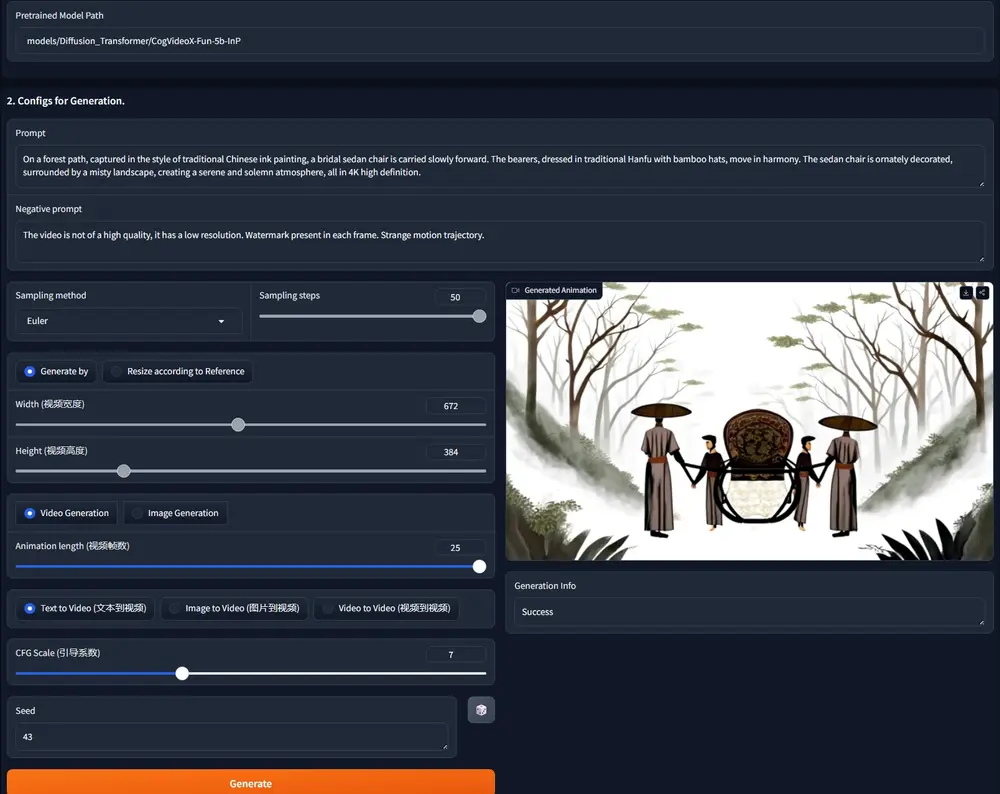
CogVideoX-Fun:基于CogVideoX结构修改后模型CogVideoX-Fun是一个基于CogVideoX结构修改后的的pipeline,是一个生成条件更自由的CogVideoX,可用于生成AI图片与视频、训练Diffusion Transformer...视频模型12个月前03790
腾讯混元团队开源多模态定制化视频生成工具Hunyuan Custom:融合文本、图像、音频、视频等多模态输入生视频的能力在内容创作领域,视频生成技术正不断进化,但如何让生成的视频既保持主体一致性,又能实现多样化的场景和动作变化,一直是创作者面临的难题。今天,腾讯混元团队正式推出并开源了一款全新的多模态定制化视频生成工具...视频模型# Hunyuan Custom# 多模态定制# 腾讯9个月前03770
昆仑万维开源图生视频模型SkyReels-A2,基于阿里Wan2.1微调而成昆仑万维在上个月推出面向 AI 短剧创作的视频生成模型 SkyReels-V1后,又在近期开源SkyReels-A2,可以将任意视觉元素(如人物、物体、背景等)根据文本提示组装成合成视频,同时严格保持...视频模型# SkyReels-A2# Wan2.1# 昆仑万维10个月前03720
腾讯混元推出HunyuanVideo-Avatar:音频驱动、情感可控、支持多角色的虚拟人视频生成模型近年来,音频驱动人物动画(Audio-driven Avatar Animation)取得了显著进展,但仍有几个关键挑战尚未完全解决: 如何在保持角色一致性的前提下生成高度动态的视频; 实现角色与音频...视频模型# HunyuanVideo-Avatar# 腾讯混元# 视频生成模型8个月前03680
腾讯推出新型图生视频框架FlexiAct:实现灵活的视频动作克隆腾讯和清华大学的研究人员推出新型图生视频框架FlexiAct,实现灵活的动作控制,能够在异构场景(即具有不同空间结构、骨骼结构或视角的场景)中将参考视频中的动作迁移到任意目标图像上,同时保持动作动态和...视频模型# FlexiAct# 图生视频9个月前03610
英伟达推出世界生成与自适应多模态控制Cosmos-Transfer1英伟达推出了一个名为 Cosmos World Foundation Model Platform 的平台,旨在为 Physical AI(物理人工智能)提供定制化的世界模型(World Founda...视频模型# Cosmos-Transfer1# 英伟达11个月前03560