基于Kronecker积的新型适应模块DiffuseKronA:保持图像生成质量的同时,显著减少模型的参数数量来自印度信息技术研究所、Hugging Face、阳明交通大学、IBM 研究院的研究人员提出一种用于个性化扩散模型的参数高效微调方法DiffuseKronA,主要功能是在保持图像生成质量的同时,显著减...新技术# DiffuseKronA# 扩散模型2年前07320
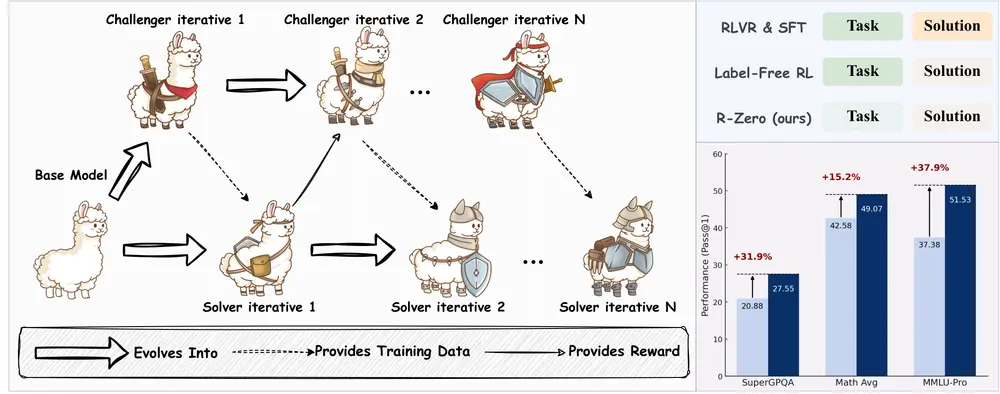
R-Zero:首个完全自进化的推理增强框架,无需数据即可提升大模型能力由腾讯 AI 西雅图实验室、圣路易斯华盛顿大学、马里兰大学帕克分校与德克萨斯大学达拉斯分校联合提出的新框架 R-Zero,正在挑战当前大语言模型训练范式的边界。 项目主页:https://chengs...新技术# R-Zero# 推理增强框架8个月前07300
新型图像匹配技术OmniGlue:首个以泛化为核心设计原则的可学习图像匹配器德克萨斯大学奥斯汀分校和谷歌的研究人员推出新型图像匹配技术OmniGlue,这是首个以泛化为核心设计原则的可学习图像匹配器。OmniGlue利用来自视觉基础模型的广泛知识来指导特征匹配过程,从而增强了...新技术# OmniGlue# 谷歌2年前07300
新型图像编辑方法Guide-and-Rescale:能够在不破坏原始图像的基础上,对真实的照片进行各种编辑俄罗斯高等经济大学、斯科尔科沃科学技术研究所 和新南威尔士大学悉尼分校的研究人员推出新的图像编辑方法Guide-and-Rescale,此方法的核心是能够在不破坏原始图像的基础上,对真实的照片进行各种...新技术# Guide-and-Rescale# 图像编辑2年前07290
轨迹条件文本到4D生成方法TC4D:根据文本描述和一条轨迹生成动态的三维场景来自多伦多大学、Vector Institute、Snap、香港中文大学、斯坦福大学、香港大学、密歇根大学和 Google DeepMind的研究团队推出轨迹条件文本到4D生成方法TC4D(Traje...新技术# 4D# TC4D# 三维场景2年前07290
阿里推出高保真图像到视频生成框架AtomoVideo阿里旗下阿里妈妈研究人员推出高保真图像到视频生成框架AtomoVideo,它能够将输入的图像转化为高保真的视频。相较于现有的技术,它提供了更出色的运动强度和一致性,而且完美兼容各种个性化文生图模型,无...新技术# AI视频# AtomoVideo2年前07290
Binary Opacity Grids:从多视角图像重建三角网格,生成高质量的视图合成来自的谷歌的研究人员推出名为“Binary Opacity Grids”的新方法,它用于从多视角图像重建三角网格,并能够捕捉到精细的几何细节,如叶子、树枝和草地等。这种方法在保持低计算成本的同时,能够...新技术# 3D# Binary Opacity Grids2年前07290
新型SD模型压缩方法VQDM:通过向量量化技术,能够将大型的文本到图像扩散模型压缩到较低比特位表示,同时保持图像生成的高质量Yandex 研究、HSE 大学、Skoltech、MIPT、Neural Magic和IST 奥地利的研究人员推出新型文本到图像扩散模型压缩方法VQDM,通过向量量化(Vector Quantiza...新技术# VQDM# 模型压缩2年前07280
新算法ViewFusion:解决在多视角图像生成一致性的问题来自亚马逊、悉尼大学、阿德莱德大学的研究人员推出新算法ViewFusion,它旨在解决在多视角图像合成中保持一致性的挑战。这个算法可以与现有的预训练扩散模型无缝集成,用于生成高质量、多样化的图像。 论...新技术# ViewFusion# 图像生成2年前07280
Figure重磅发布Figure 03电池,人形机器人能源系统的重大突破人形机器人初创公司 Figure 在今天正式发布其第三代电池系统——Figure 03(F.03)电池,标志着其人形机器人平台在能源系统设计上的重大突破。 这款电池不仅是 Figure 人形机器人技术...早报# Figure# 机器人9个月前07270
FreeNoise:通过噪声调度实现无需调参的长视频生成来自腾讯人工智能实验室、南洋理工大学、香港科技大学的研究人员提出了一种利用预训练的视频扩散模型生成高质量长视频的方法FreeNoise,它能够使模型在生成更长时间视频时保持内容的一致性,无需对模型进行...新技术# AI视频# FreeNoise# 噪声2年前07270
阿里推出新型大型多模态模型ConvLLaVA:专门设计用于处理高分辨率的视觉数据清华大学和阿里巴巴的研究人员推出新型大型多模态模型ConvLLaVA,它专门设计用于处理高分辨率的视觉数据。多模态模型能够理解和处理多种类型的数据,比如文本、图像和视频,这使得它们在各种应用场景中都非...新技术# ConvLLaVA# 多模态模型# 阿里巴巴2年前07230