基于两阶段高斯溅射的3D模型DreamPolisher:基于文本描述生成三维(3D)对象来自牛津大学的研究人员推出DreamPolisher,它是一种基于文本描述生成三维(3D)对象的方法。这是一种基于两阶段高斯溅射的方法,该方法强制各视图之间的几何一致性。首先,通过几何优化对粗略的3D...新技术# 3D模型# DreamPolisher2年前07230
专门解读胸部X光片的图像模型CheXagent:帮助医生提高临床决策的效率和质量来自斯坦福大学和Stability AI的研究人员推出了一个专门解读胸部X光片的图像模型CheXagent,这个模型的目的是帮助医生更准确地分析和理解X光片,从而提高临床决策的效率和质量。 项目主页 ...新技术# CheXagent# Stability AI# X光片2年前07210
图像超分辨率技术SeeSR:保持生成的高分辨率图像的语义准确性来自香港理工大学、OPPO、字节跳动的研究人员推出图像超分辨率技术SeeSR,它利用语义提示来增强预训练的文本到图像(T2I)扩散模型在处理现实世界图像超分辨率问题时的性能。这种方法特别关注于在图像质...新技术# SeeSR# 图像超分辨率2年前07210
Stability AI开发者平台上线全新API 服务重点摘要: Stability AI开发者平台现推出了一系列全面的 API 服务,树立了图像生成、放大和编辑的新标杆,未来还将推出更多服务。 这些服务专为开发者和创业者打造,融合了我们先进的图像处理技...科普# Stability AI2年前07190
创新框架EMO:只需要提供一张静态照片和一段语音,就能生成口型匹配的视频阿里巴巴推出创新框架EMO,它是一个能够根据音频生成表情丰富的肖像视频的系统。想象一下,你只需要提供一张静态的照片和一段语音,EMO就能创造出一个视频,视频中的人物头像会根据语音的内容和情感变化做出相...新技术# EMO# 口型匹配2年前07190
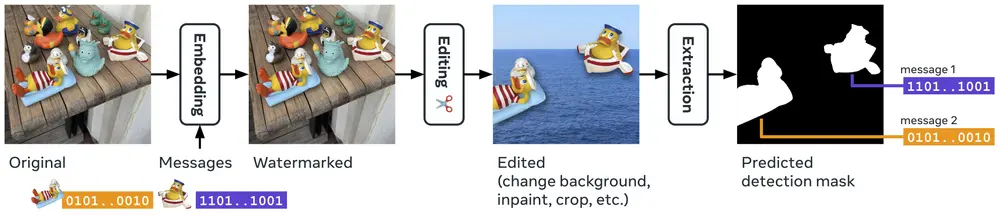
Meta推出局部图像水印的深度学习模型WAM图像水印技术在保护数字内容的版权和完整性方面发挥着重要作用。然而,传统的图像水印方法并未针对处理小面积水印区域进行优化,这限制了其在实际应用中的使用,例如图像的部分可能来自不同来源或已被编辑。Meta...新技术# WAM# 图像水印1年前07170
单样本文生图模型的微调方法:解决泛化性和真实性问题来自腾讯的研究人员提出了一种面向对象的单样本文生图模型的微调方法Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with P...新技术# Lora# 微调# 文生图2年前07170
苹果提出了新的文生图模型架构DiT-Air和DiT-Air-Lite:提高模型的参数效率和生成性能苹果提出了新的文生图模型架构DiT-Air和DiT-Air-Lite,旨在提高模型的参数效率和生成性能。其论文主要研究了扩散模型(Diffusion Models)在文本到图像生成任务中的架构设计、文...新技术# DiT-Air# DiT-Air-Lite# 文生图模型1年前07160
人像视频生成框架V-Express:平衡不同控制信号(如文本、音频、参考图像、姿态、深度图等)的强弱,以便在生成视频中实现更协调和有效的控制南京大学和腾讯人工智能实验室的研究人员推出人像视频生成框架V-Express,它用于生成高质量的人像视频。这项技术特别关注于如何平衡不同控制信号(如文本、音频、参考图像、姿态、深度图等)的强弱,以便在...新技术# V-Express# 人像视频2年前07150
运动引导扩散模型Pix2Gif:用于图像到GIF(视频)的生成微软印度研究院和微软雷蒙德研究院的研究人员推出运动引导扩散模型Pix2Gif,该模型可用于图像到GIF(视频)的生成。 项目主页 GitHub Demo 他们采取了与众不同的方法,将任务定位为受文本和...新技术# GIF# Pix2Gif2年前07130
英伟达GeForce RTX 4060 Ti 16GB英伟达在去年7月正式发售万众瞩目RTX 4060 Ti 16GB,这张显卡最大的优点就是16GB显存,这对于AI用户来说这张显卡可以说是入门首选,一起来看看这张显卡的规格吧! RTX 4060 Ti ...硬件# RTX 4060 Ti 16GB# 英伟达2年前07130
高效且精确的注意力机制量化方法SageAttention:加速大语言处理、图像生成和视频生成模型清华大学的研究人员推出一种高效且精确的注意力机制量化方法SageAttention,此方法的OPS(每秒操作数)性能分别比FlashAttention2和xformers提高了约2.1倍和2.7倍。S...新技术# SageAttention# 注意力机制2年前07120