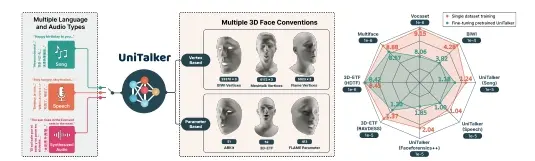
用于3D面部动画的统一模型UniTalker:能够根据输入的音频生成逼真的面部动作商汤科技推出UniTalker,它是一个用于3D面部动画的统一模型,能够根据输入的音频生成逼真的面部动作。这项技术在动画制作、虚拟现实、游戏开发等领域具有广泛的应用前景。UniTalker是一种统一的...新技术# UniTalker2年前07120
文本到图像合成框架PIXART-δ:0.5秒内生成1024×1024像素的图像来自华为诺亚方舟实验室、大连理工大学、香港大学、香港科技大学的研究人员推出了文本到图像合成框架PIXART-δ,这是去年发布的PIXART-α模型的一个升级版本。PIXART-α以其高效的训练过程和生...新技术# AI绘画# PIXART-α# PIXART-δ2年前07120
3D重建和生成模型GRM:从稀疏视角的图像中快速重建出3D模型来自斯坦福大学、香港科技大学、上海人工智能实验室、 浙江大学和蚂蚁集团的研究团队推出新型大规模3D重建和生成模型GRM(Gaussian Reconstruction Model),GRM是一种基于t...新技术# 3D模型# GRM2年前07110
T-Stitch:加速预训练扩散模型采样过程来自莫纳什大学、英伟达、威斯康星大学麦迪逊分校、加州理工学院的研究人员推出T-Stitch,它是一种用于加速预训练扩散模型采样过程的方法。 项目主页 GitHub 扩散模型是一类在图像生成领域表现出色...新技术# T-Stitch# 扩散模型# 采样2年前07100
条件感知神经网络CAN:用于在图像生成模型中添加控制来自麻省理工学院、清华大学和英伟达的研究人员推出一种条件感知神经网络(CAN),用于在图像生成模型中添加控制,它通过动态调整神经网络的权重来实现对生成图像的控制。 论文 GitHub 与之前的条件控制...新技术# CAN# 条件感知神经网络2年前07080
EdgeFusion:能够在资源受限的移动设备上快速生成与文本描述相匹配的高质量图像来自韩国Nota AI和三星电子的研究人员推出EdgeFusion,它能够在资源受限的移动设备上快速生成与文本描述相匹配的高质量图像。这项技术的核心是优化了文生图模型Stable Diffusion...新技术# EdgeFusion# LCM# 文生图模型2年前07070
新框架VSP-LLM:通过观察视频中人的嘴型来理解和翻译说话内容这篇论文介绍了一个名为VSP-LLM(Visual Speech Processing incorporated with LLMs)的新框架,它结合了视觉语音处理和大语言模型(LLMs),以提高视觉...新技术# VSP-LLM# 大语言模型# 视觉语音翻译2年前07060
AI视频生成模型Animated Stickers:让静态表情包动起来来自Meta的研究人员推出了AI视频生成模型Animated Stickers,它可以让普通表情包图片“动”起来。这项技术的核心是利用先进的文本到图像(Text-to-Image)模型,通过添加时间层...新技术# AI视频生成模型# Animated Stickers# 表情包2年前07060
视频编码器VideoPrism:能够处理多种视频理解任务,如分类、定位、检索、字幕生成和问答来自谷歌的研究人员推出视频编码器VideoPrism,它是一个通用的视频理解模型,能够处理多种视频理解任务,如分类、定位、检索、字幕生成和问答(QA)。VideoPrism通过在一个单一的冻结模型上进...新技术# VideoPrism# 视频编码器# 谷歌10个月前07050
谷歌推出新框架ImageInWords(IIW):创建准确且细节丰富的图像描述,以提高视觉-语言模型的训练效果Google Research、Google DeepMind和华盛顿大学的研究团队推出新框架ImageInWords(IIW),此框架旨在创建准确且细节丰富的图像描述,以提高视觉-语言模型(VLMs...新技术# IIW# ImageInWords# 数据集2年前07040
图像编辑技术Editable Image Elements:允许用户对输入的图像进行空间编辑,同时保持图像内容的逼真度来自加州大学圣地亚哥分校和Adobe 研究中心的研究人员推出新的图像编辑技术Editable Image Elements for Controllable Synthesis,它允许用户对输入的...新技术# Editable Image Elements# 图像编辑2年前07040
ViewDiff:从文本或图像生成多视图图像来自Meta和慕尼黑工业大学的研究人员推出ViewDiff,它能够根据文本描述或已有的图像输入,生成与3D对象一致的高质量图像。 项目主页 GitHub 想象一下,你只需要告诉计算机你想要的3D对象是...新技术# 3D模型# ViewDiff# 多视角2年前07030