连续3D词(Continuous 3D Words):通过文本提示来精细控制图像生成过程中的多个属性来自牛津大学、Adobe Research的研究人员提出了一种“连续3D词(Continuous 3D Words)”的新方法,使得用户能够通过文本提示来精细控制图像生成过程中的多个属性,比如照明方向...新技术# AI绘画# Continuous 3D Words# 连续3D词2年前07030
模型量化技术BitsFusion:减少SD模型参数大小,同时还能让这个模型生成的图片质量更好Snap和罗格斯大学的研究人员推出新型图像生成模型的权重量化技术BitsFusion。简单来说,就是研究者们开发了一种方法,可以把一个用来生成图片的复杂模型(叫做扩散模型)的参数量大大减少,同时还能让...新技术# BitsFusion# 模型参数# 模型量化2年前07020
基于Transformer架构的新型图像生成模型DART:根据文本描述生成高质量的图像苹果和香港中文大学的研究人员推出新型图像生成模型DART,这个模型的目标是让计算机能够根据文本描述生成高质量的图像。DART是一个基于Transformer架构的模型,它在非马尔可夫框架内统一了自回归...新技术# DART# Transformer架构# 图像生成模型2年前07010
腾讯优图推出RealTalk:用于生成逼真、实时的音频驱动人脸视频的框架腾讯优图实验室和南京大学的研究人员推出新技术RealTalk,它是一个用于生成逼真、实时的音频驱动人脸视频的框架。简单来说,RealTalk可以根据一个人的语音生成一个看起来非常真实的3D人脸动画,而...新技术# RealTalk# 南京大学# 腾讯优图2年前06990
Adobe推出新版Photoshop:引入全新 Firefly Image 3模型,“调整刷”与“字体浏览器”带来新体验在昨天的Adobe Max大会上,Adobe带来了重磅更新:Photoshop迎来全新升级,并集成了图像生成模型Firefly Image 3。这一组合不仅为设计师和创意工作者带来了前所未有的AI图像...早报# Adobe# Firefly Image 3# Photoshop2年前06990
LM Studio 0.3.17 版本正式引入MCP支持LM Studio 0.3.17 版本正式引入了 模型上下文协议(Model Context Protocol, MCP) 的支持,允许用户将本地或远程的 MCP 服务器连接到应用中,从而为大型语言模...早报# LM Studio# MCP9个月前06970
无需训练的组合式文本到图像生成方法CompAgent来自清华大学、华为诺亚方舟实验室、香港大学的研究人员提出了一种无需训练的组合式文本到图像生成方法CompAgent,该方法利用大语言模型(LLM)智能体进行复杂文本提示的分析与规划,将文本分解为单个对...新技术# CompAgent# 华为诺亚方舟# 文生图2年前06970
无需训练的图像编辑技术DiffUHaul:专门用于在图像中无缝移动物体英伟达研究中心、耶路撒冷希伯来大学、特拉维夫大学和赖希曼大学的研究人员推出一种无需训练的图像编辑技术DiffUHaul,专门用于在图像中无缝移动物体。例如,你有一张图片,里面有一只猫和一块岩石,你想要...新技术# DiffUHaul# 图像编辑2年前06960
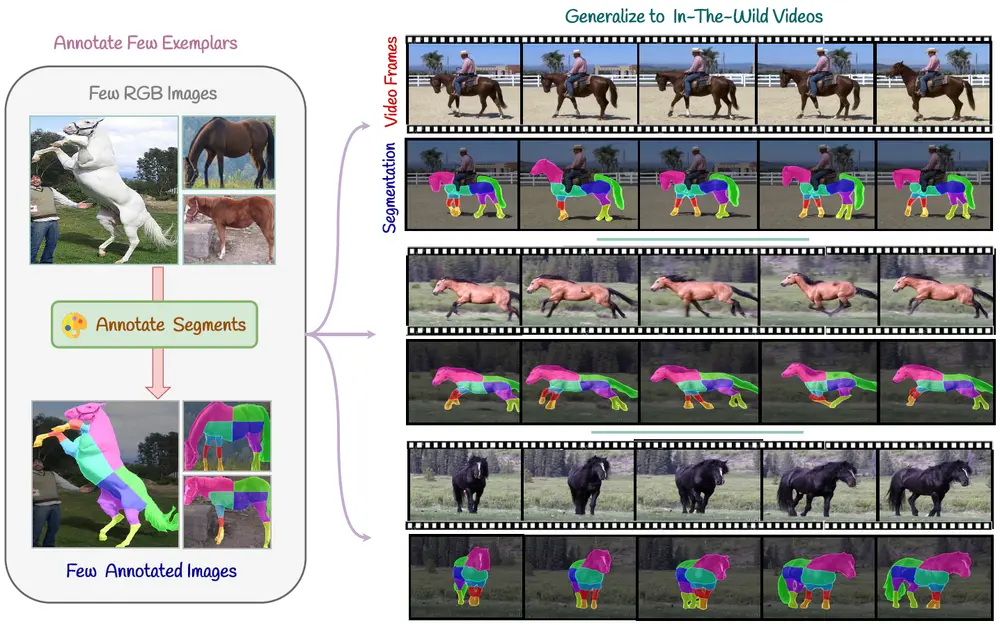
视频对象分割技术SMITE:解决视频内对象的分割问题,特别是在需要任意粒度(即对象可以被分割成不同数量的片段)的情况下视频对象分割是一项具有挑战性的任务,每个像素必须被准确标记,并且这些标签必须在帧之间保持一致。当分割具有任意粒度时,难度会进一步增加,这意味着段的数量可以任意变化,并且掩模仅基于一个或几个样本图像定义...新技术# SMITE# 视频对象分割1年前06940
谷歌推出新采样方法EM Distillation(EMD):用于提高扩散模型(diffusion models)的采样效率谷歌推出新采样方法EM Distillation(EMD),用于提高扩散模型(diffusion models)的采样效率。扩散模型是一种强大的生成模型,能够学习复杂的数据分布并生成高质量的图像、视频...新技术# EM Distillation# EMD# 采样方法2年前06940
OpenAI旗下模型选型指南:全面解析 GPT 系列与 o 系列,助你精准选择适合的 AI 模型OpenAI于近期接连发布了多个新的模型,但命名上的混乱让许多用户难以区分这些模型之间的区别。例如,GPT 4o、GPT-4o mini、o3、o4-mini、GPT-4.1、GPT 4.5,这些模型...科普# AI 模型# ChatGPT# OpenAI12个月前06910
图像分割技术OpenTrans:提高开放词汇表分割(OVS)的效率来自北京交通大学和西蒙菲莎大学的研究人员推出OpenTrans,它旨在提高开放词汇表分割(Open-Vocabulary Segmentation, OVS)的效率。OVS是一种图像分割技术,能够识别...新技术# OpenTrans# 图像分割技术2年前06910