基于身份条件的人脸基础模型Arc2Face:能够根据一个人的面部特征生成高质量的、逼真的图像来自英国伦敦帝国理工学院的研究人员推出基于身份条件的人脸基础模型Arc2Face,能够根据一个人的面部特征生成高质量的、逼真的图像。 项目主页 GitHub Demo 模型 想象一下,如果你有一张朋友...新技术# Arc2Face2年前06910
Search_T2V:改善文本到视频合成的质量和真实感浙江大学、飞步科技、宁波港和腾讯数据平台的研究人员推出新技术Search_T2V,旨在改善文本到视频(Text-to-Video, T2V)合成的质量和真实感。该技术通过搜索现有的视频资源作为运动先验...新技术# Search_T2V# 文生视频模型2年前06900
字节跳动推出数据集COCONut,专门针对图像分割任务字节跳动推出数据集COCONut,它是对现有的COCO数据集的现代化升级,专门针对图像分割任务。图像分割是计算机视觉中的一个核心问题,它的目标是将图像中的每个像素正确地分类到不同的实例或类别中,此数据...新技术# COCONut# 图像分割# 字节跳动2年前06900
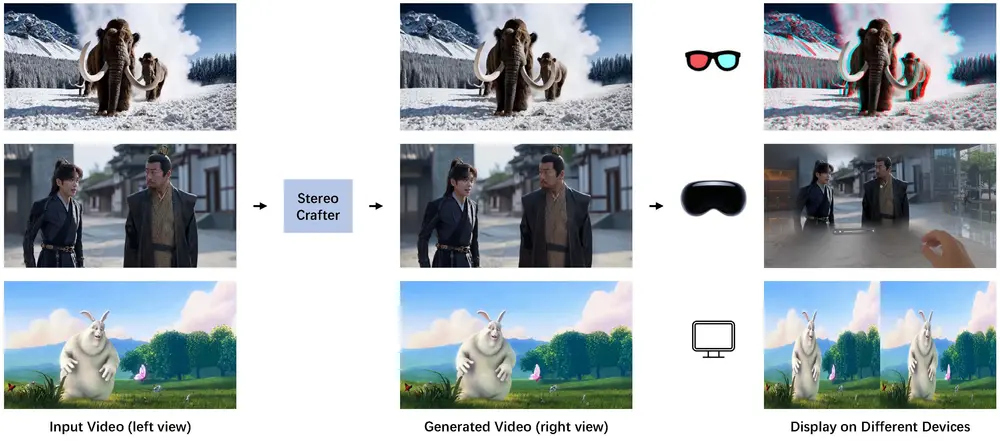
StereoCrafter框架:用于将单目(2D)视频转换为沉浸式立体 3D 视频,以满足人们对沉浸式数字体验的需求腾讯AI实验室和腾讯PCG ARC Lab的研究人员推出StereoCrafter框架,用于将单目视频转换为沉浸式立体 3D 视频,以满足人们对沉浸式数字体验的需求。该框架主要解决了传统 2D-to...新技术# StereoCrafter1年前06890
AI视频生成新模型CONSISTI2V:通过增强视觉一致性来改善视频生成的质量来自滑铁卢大学、Vector Institute、Harmony.AI、多模式艺术投影研究社区的研究人员提出了一种基于扩散的图像到视频生成新方法CONSISTI2V,它旨在通过增强视觉一致性来改善视频...新技术# AI视频生成# CONSISTI2V2年前06880
阿里云无影AgentBay发布,5分钟搭建高并发Agent环境4月9日,阿里云无影正式推出国内首个支持MCP协议的云电脑服务——AgentBay。这一创新服务让开发者能够通过云端一键生成专属的AI运行环境,动态调用云上算力、存储及工具链资源,彻底突破本地设备的性...早报# AgentBay# 无影# 阿里云1年前06860
文本到3D生成模型VP3D:通过利用2D视觉提示来增强3D模型的视觉真实感来自HiDream.ai和复旦大学的研究人员推出新型文本到3D生成模型VP3D,它通过利用2D视觉提示来增强3D模型的视觉真实感。在以往的研究中,虽然已经有了一些能够从文本生成3D模型的技术,但这些技...新技术# 3D生成模型# VP3D2年前06860
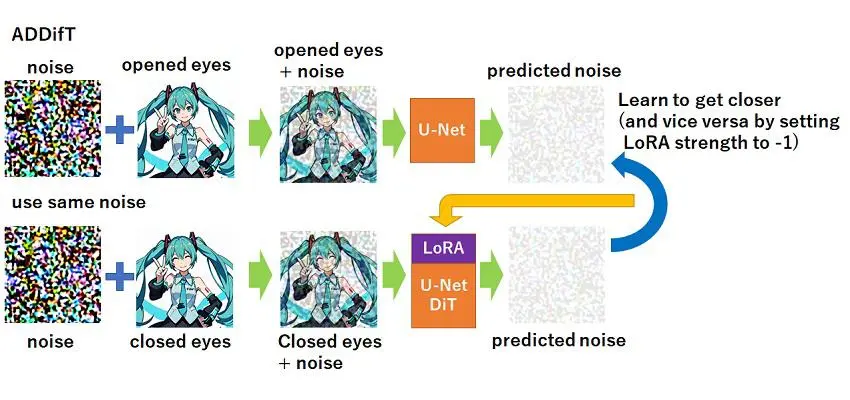
全新LoRA训练方法ADDifT(交替直接差分训练)背景与动机 LoRA(低秩适应)是一种参数高效的微调技术,广泛用于大语言模型和扩散模型(如Stable Diffusion)的定制化训练。然而,传统LoRA训练方法存在效率低和易学到无关特征(如背景或...新技术# ADDifT# Lora# LoRA模型1年前06840
AutoVFX:基于自然语言指令的自动视觉效果生成现代视觉效果(VFX)软件使熟练的艺术家能够创造出几乎任何图像,但创作过程仍然费力、复杂,并且对普通用户来说基本上是不可访问的。为了简化这一过程,伊利诺伊大学厄巴纳-香槟分校的研究人员提出了AutoV...新技术# AutoVFX1年前06840
快速视频生成方法AnimateLCM:只需四步推理就可以生成视频来自香港中文大学、Avolution AI、上海人工智能实验室、商汤科技研究院的研究人员推出快速视频生成方法AnimateLCM,该方法利用一致性学习策略,将图像生成先验和运动生成先验进行解耦,从而提...新技术# AI视频生成# AnimateLCM2年前06830
新型单视图3D重建方法FDGaussian:能够从2D输入中提取出3D几何特征,从而生成一致的多视图图像来自复旦大学的研究团队推出新型单视图3D重建方法FDGaussian,它采用正交平面分解机制,能够从2D输入中提取出3D几何特征,从而生成一致的多视图图像。 项目主页 论文地址 想象一下,你只有一张物...新技术# 3D重建# FDGaussian2年前06820
新型生成模型DisCo-Diff:用于增强连续扩散模型的性能英伟达和麻省理工学院的研究人员推出新型生成模型DisCo-Diff,它用于增强连续扩散模型(Diffusion Models, DMs)的性能。扩散模型是一种强大的数据生成方法,但它们通常需要将复杂的...新技术# DisCo-Diff# 生成模型2年前06810