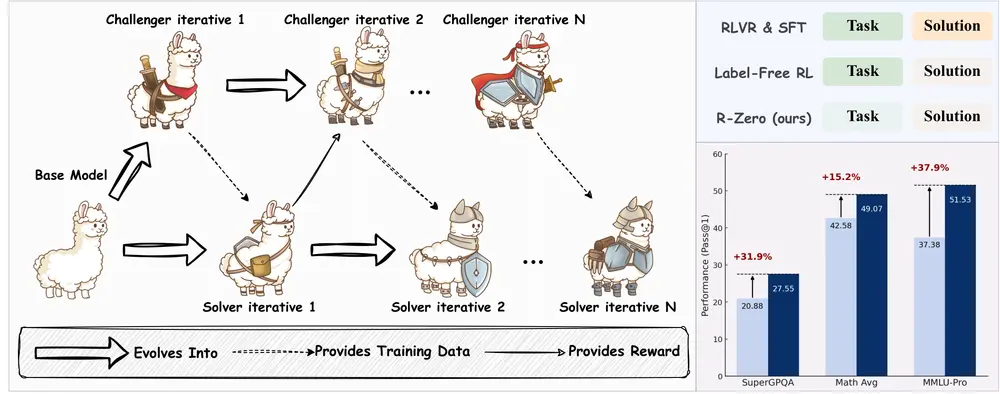
由腾讯 AI 西雅图实验室、圣路易斯华盛顿大学、马里兰大学帕克分校与德克萨斯大学达拉斯分校联合提出的新框架 R-Zero,正在挑战当前大语言模型训练范式的边界。
它让一个基础语言模型从零开始、无需任何人类标注数据,就能通过内部协同机制,自主生成训练任务、提升推理能力——实现真正的“自进化”。
这不仅是一种新的训练方法,更是一种关于“智能如何自我塑造”的探索。

什么是 R-Zero?
R-Zero 是一个完全自主的推理增强框架,目标是让大语言模型(LLM)在没有外部数据输入的情况下,持续提升自身的复杂推理能力。
传统方法依赖大量人工标注的高质量推理数据(如数学题解、逻辑推导),成本高、扩展难。而 R-Zero 完全绕开了这一瓶颈:
不依赖任何预存数据集,不依赖人类反馈,仅从一个基础模型出发,实现自我驱动的推理进化。
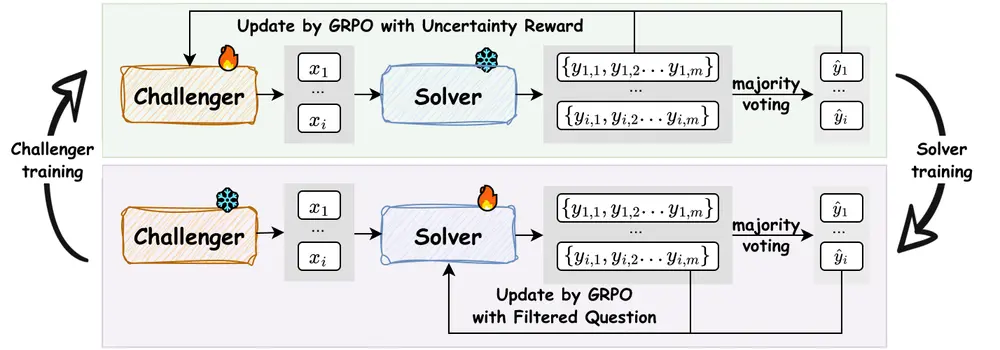
其核心机制是构建两个基于同一模型的实例之间的动态协同进化循环:
- 挑战者(Challenger)🎯:负责生成恰好处于解决者当前能力边缘的问题,不断“施压”。
- 解决者(Solver)🧠:尝试解答这些挑战性问题,并在成功中学习和进化。
二者相互促进:挑战者越强,课程越有效;解决者越强,挑战者也被迫提出更难的问题。整个系统像一场永不停止的“智力对弈”。
方法详解:如何实现“从零进化”?
R-Zero 的训练流程完全自包含,分为三个关键环节:挑战生成 → 数据构建 → 协同优化。
1. 挑战者:生成“刚刚好难”的问题
挑战者的任务不是随机出题,而是精准探测解决者的“能力边界”。为此,系统采用以下策略:
- 使用 Group Relative Policy Optimization (GRPO) 算法进行强化学习训练
- 奖励信号来自解决者的不确定性度量(如自一致性:多次采样回答是否一致)
- 回答越不一致 → 说明问题越具挑战性 → 挑战者得分越高
- 引入重复惩罚机制,防止生成相似或冗余问题
- 加入格式校验,确保问题结构清晰、可解
这样,挑战者逐渐学会提出“跳一跳够得着”的问题,形成自适应的课程学习路径。
2. 解决者:在挑战中成长
解决者通过回答挑战者提出的问题来提升自身能力。关键在于——如何为这些问题打标签?
R-Zero 的答案是:用模型自己生成伪标签。
具体流程如下:
- 解决者对同一问题多次采样回答
- 通过多数投票确定最可能的正确答案(即伪标签)
- 过滤低质量或歧义问题
- 构建高质量训练集,用于微调解决者
这一过程无需人类干预,却能生成可靠的学习信号。
3. 协同进化:双模型迭代升级
整个训练以迭代方式进行:
| 迭代轮次 | 挑战者行为 | 解决者行为 |
|---|
| 第1轮 | 探测基础模型弱点,提出初级挑战 | 学习并提升基础推理能力 |
| 第2轮 | 根据新能力调整问题难度 | 应对更高阶任务,深化理解 |
| 第n轮 | 动态演化出复杂推理题 | 掌握归纳、类比、多步推理等技能 |
每一轮都推动双方进入更高层次的认知博弈,形成正向反馈循环。
整个过程仅依赖单一基础模型初始化,无需额外数据、无需外部监督。
实验结果:显著且可泛化的性能提升
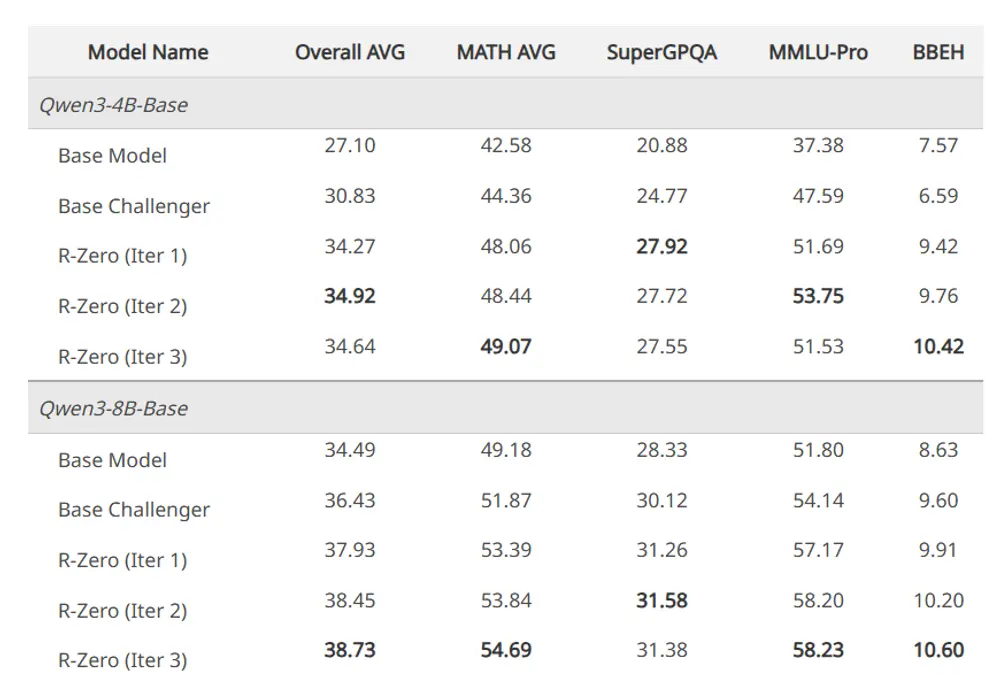
研究人员在多个主流基础模型上验证了 R-Zero 的有效性,包括 Qwen3-4B-Base、Qwen3-8B-Base 和 OctoThinker-3B。
✅ 数学推理能力大幅提升
| 模型 | 基线平均分 | R-Zero 三次迭代后 | 提升幅度 |
|---|
| Qwen3-4B-Base | 42.58 | 49.07 | +6.49 |
| Qwen3-8B-Base | 49.18 | 54.69 | +5.51 |
在更具挑战性的 AIME-2025 数学竞赛题上:
- Qwen3-4B-Base 从 10.94 提升至 12.71
- 显示出对高阶数学思维的有效掌握
所有提升均来自模型自生成数据,未引入任何外部标注样本。
✅ 推理能力成功泛化至通用领域
更重要的是,R-Zero 带来的不是“死记硬背”的领域知识,而是可迁移的底层推理能力。
在 MMLU-Pro、SuperGPQA 等通用推理基准上的表现:
| 模型 | 通用领域基线 | 三次迭代后 | 提升幅度 |
|---|
| Qwen3-8B-Base | 34.49 | 38.73 | +4.24 |
| OctoThinker-3B | — | — | +3.65 |
这表明:模型学到的是一种通用的问题解决策略,而非特定领域的技巧。
🔍 关键创新点总结
| 创新维度 | R-Zero 的突破 |
|---|
| 数据来源 | 完全自生成,无需人类标注 |
| 训练范式 | 双模型协同进化,动态课程设计 |
| 标签构建 | 多数投票 + 自一致性 → 高质量伪标签 |
| 优化机制 | GRPO 强化学习驱动挑战者进化 |
| 泛化能力 | 数学推理技能可迁移至通用任务 |
R-Zero 首次证明:大模型可以在没有外部数据的情况下,通过内部博弈实现推理能力的持续增长。
🧩 潜在影响与未来方向
可能的应用场景
- 低成本模型增强:为缺乏标注资源的团队提供推理能力提升路径
- 持续学习系统:部署后仍可自主进化,适应新任务
- AI 自我改进研究:为“递归自我改进”提供实验平台
当前局限
- 初始模型需具备一定基础推理能力(无法从“零智能”启动)
- 对计算资源要求较高(双模型并行训练)
- 在极端复杂任务(如形式化证明)上的表现尚待验证
未来工作
- 扩展至多模态推理
- 探索更多角色参与(如“评判者”模块)
- 提升长程规划与抽象归纳能力