
在 AI 智能体(Agent)技术快速发展的当下,开发者已经可以通过 LangChain、AutoGen、OpenAI Agent SDK 等框架,快速构建具备工具调用、多轮对话和任务编排能力的智能系统。然而,一个长期被忽视的问题是:如何让这些智能体在真实场景中越用越好?
大多数智能体框架停留在“静态部署”阶段——一旦完成开发,其行为逻辑和底层模型就基本固定,难以根据实际交互数据持续优化。而现有的训练框架(如强化学习系统)又往往与主流智能体生态脱节,导致“能开发”但“难进化”。
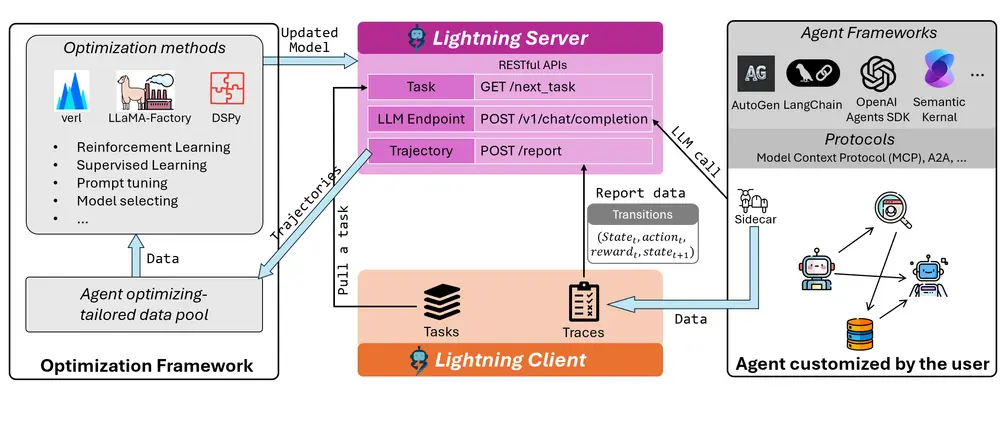
为解决这一断层,微软近期推出了 Agent Lightning —— 一个灵活、可扩展的智能体优化框架,旨在将智能体的“开发”与“训练”真正连接起来。
什么是 Agent Lightning?
Agent Lightning 并不是一个智能体开发框架,而是一个优化中间层。它不替代 LangChain 或 AutoGen,而是运行在其之上,支持对使用任何现有框架构建的智能体进行数据驱动的性能提升。
其核心目标是:
让开发者无需修改原有智能体代码,即可实现模型微调、提示优化、策略学习等高级训练能力。
目前,Agent Lightning 的重点是通过强化学习(RL) 来优化智能体行为,未来将扩展至监督微调、提示工程、模型选择等多种方式,形成统一的智能体演进体系。

为什么需要智能体优化?
AI 智能体的强大之处在于其模块化与交互性,适用于代码生成、客户服务、自动化运维等复杂任务。但现实部署中,它们常面临以下挑战:
- 多轮交互中的上下文漂移
- 工具调用失败或误判
- 多智能体协作效率低下
- 对私有业务逻辑理解不足
这些问题无法仅靠提示工程或更换模型解决。真正的改进需要基于真实交互数据,动态调整智能体的决策逻辑。
而当前的强化学习训练工具(如 Verl)虽然强大,却要求用户从头实现环境、奖励函数和策略接口,与 LangChain 等高层框架完全割裂。
Agent Lightning 正是为了弥合这一鸿沟而生。
核心特性
✅ 1. 无缝集成主流智能体框架
Agent Lightning 支持优化使用以下框架构建的智能体:
- OpenAI Agent SDK
- Microsoft AutoGen
- LangChain
无需修改一行智能体代码,即可接入训练流程。开发者继续使用熟悉的 API 开发智能体,Agent Lightning 负责在后台收集行为数据并驱动模型更新。
✅ 2. 解耦开发与训练:Lightning 客户端 + 服务器架构
框架采用轻量级的 客户端-服务器架构:
- Lightning 客户端:嵌入在智能体运行环境中,负责上报执行轨迹、错误信息和奖励信号。
- Lightnying 服务器:接收数据、组织训练样本,并与后端训练系统(如 Verl)对接。
这种设计实现了智能体逻辑与训练逻辑的彻底解耦,使得同一套训练基础设施可以服务于多种不同架构的智能体应用。
✅ 3. 支持真实世界复杂性
Agent Lightning 专为现实场景设计,能处理:
- 多轮对话与长期记忆管理
- 多智能体协同决策
- 动态上下文切换
- 异常执行路径(如工具调用失败)
尤其值得一提的是,它原生支持错误监控与失败归因。服务器可记录智能体执行中的各类错误(如语法错误、工具超时、死循环),为训练过程提供关键反馈信号,帮助模型学会“优雅降级”而非盲目重试。
✅ 4. 开放式奖励机制
奖励信号是强化学习的核心。Agent Lightning 允许开发者自定义奖励函数,例如:
- 任务完成度评分
- 用户满意度反馈
- 工具调用成功率
- 响应延迟惩罚
这些信号通过客户端上报,在训练中用于指导策略更新,确保优化方向符合业务目标。
工作流程详解
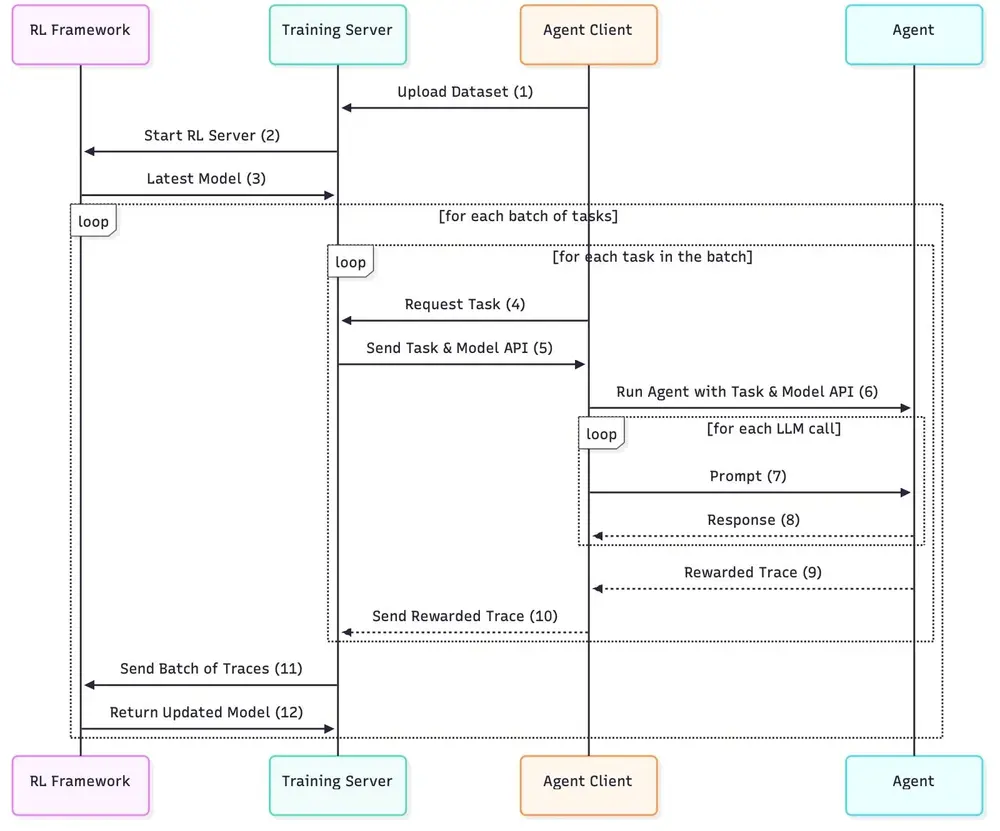
1. 任务下发与智能体执行
Lightning 服务器从任务池中拉取任务,发送给智能体客户端。智能体使用其原生框架(如 LangChain Chain 或 AutoGen GroupChat)执行任务,可能涉及:
- 多轮对话
- 工具调用(搜索、数据库查询等)
- 多智能体协商
2. 非侵入式数据采集(Sidecar 模式)
通过 sidecar 架构,Lightning 客户端监听智能体运行过程,自动捕获:
- 每一步的状态与动作
- 执行结果与奖励
- 错误类型与堆栈信息
所有数据通过标准 API 上报至服务器,不影响原有智能体性能。
3. 轨迹转换与训练
服务器将原始轨迹转换为标准 RL 格式:(状态_t, 动作_t, 奖励_t, 状态_t+1)
这些数据被送入训练后端(当前基于 Verl),使用 GRPO 等算法更新 LLM 策略。新模型随后用于下一轮 rollout,形成“执行 → 学习 → 改进”的闭环。
架构优势:为什么能做到“通用兼容”?
关键在于 OpenAI 兼容 API 层 的设计。
Agent Lightning 在训练端暴露了一个与 OpenAI API 兼容的接口,这意味着:
- 所有依赖
openai.ChatCompletion的智能体框架(包括 LangChain、AutoGen) - 只需将 API endpoint 指向 Lightning 服务器
- 即可自动进入可训练模式
无需重写逻辑,也不依赖特定训练库,真正实现“即插即用”。
未来规划
Agent Lightning 目前聚焦强化学习优化,但其设计理念是通用智能体优化平台。后续计划包括:
| 方向 | 具体功能 |
|---|---|
| 更多反馈机制 | 用户反馈集成、长周期信用分配、工具成功信号建模 |
| 更多训练方法 | 在线监督微调(SFT)、课程学习、离线策略优化 |
| 更多后端支持 | LLaMA-Factory、DSPy、HuggingFace TRL |
| 更多框架兼容 | Semantic Kernel、CrewAI、MetaGPT |
最终目标是构建一个统一接口,让开发者可以自由组合“开发框架 + 优化方法 + 训练后端”,按需选择最适合其场景的技术栈。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











