新型视频编辑技术ReVideo:在视频中对特定区域进行精确的内容和运动控制编辑北京大学深圳研究生院 、ARC实验室,腾讯 PCG和东京大学的研究人员推出新型视频编辑技术ReVideo,ReVideo的核心能力是在视频中对特定区域进行精确的内容和运动控制编辑。这意味着用户可以随心...新技术# ReVideo# 视频编辑2年前08690
虚拟服装试穿技术IDM-VTON:根据一个人的图片和一件衣服的图片,生成这个人穿上这件衣服的图像来自韩国科学技术院和OMNIOUS.AI的研究人员推出虚拟服装试穿技术IDM-VTON,该技术能够根据分别描绘人物和服装的图像对,渲染出人物穿着精选服装的视觉效果。虚拟试穿是一种计算机视觉技术,它可以...新技术# IDM-VTON# 虚拟服装试穿# 虚拟试穿2年前08680
韩国团队提出文生图大模型KOALA:可在低端GPU电脑上运行韩国研究人员提出了一种高效的潜在扩散模型KOALA,该模型可以用于文本到图像的生成,研究人员构建了T2I模型KOALA-1B和KOALA-700M,减小了模型大小,降低了模型对硬件的需求,提高了模型运...新技术# KOALA# 文生图大模型# 韩国2年前08670
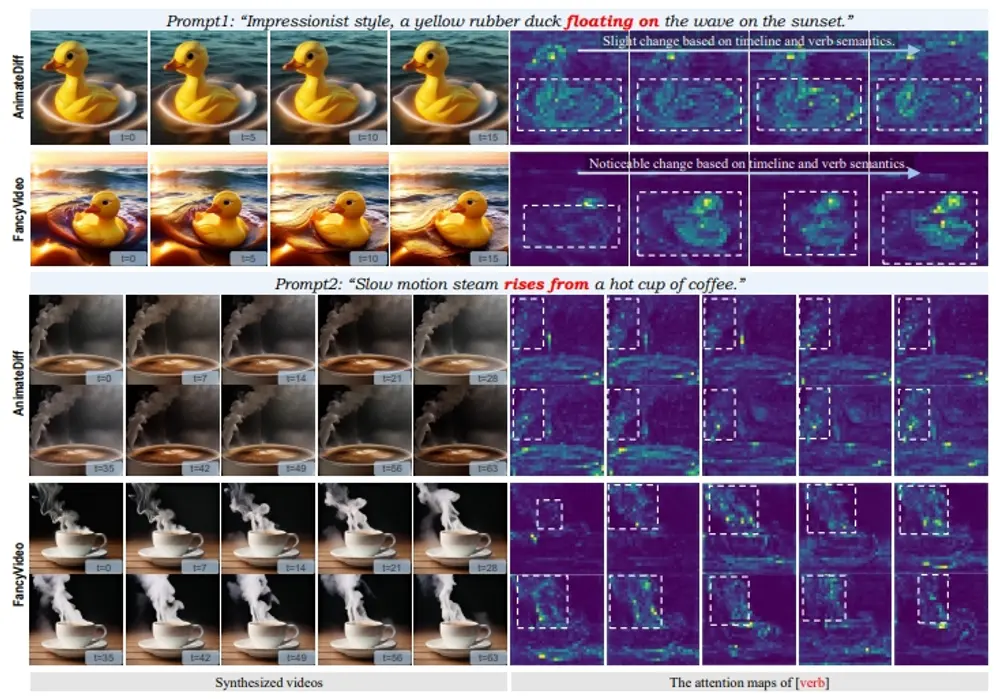
新型视频生成模型FancyVideo:根据文本提示生成动态丰富且时间上连贯的视频360 AI研究中心和中山大学的研究人员推出新型视频生成模型FancyVideo,它能够根据文本提示生成动态丰富且时间上连贯的视频。FancyVideo通过精心设计的跨帧文本引导模块(CTGM)改进了...新技术# FancyVideo2年前08660
先进的视频深度估计方法ChronoDepth:通过结合视频生成模型的先验知识,有效地提高了深度估计的准确性和时间一致性浙江大学、博洛尼亚大学、蚂蚁集团和Rock Universe的研究人员推出一种先进的视频深度估计方法ChronoDepth,它通过结合视频生成模型的先验知识,有效地提高了深度估计的准确性和时间一致性...新技术# ChronoDepth# 视频深度2年前08660
IDEA研究院推出先进开集目标检测模型系列Grounding DINO 1.5:推动开放集对象检测技术的边界IDEA研究院(粤港澳大湾区数字经济研究院)推出先进模型系列Grounding DINO 1.5,旨在推动开放集对象检测技术的边界。开放集对象检测是一种计算机视觉任务,它要求模型能够识别图像中的对象...新技术# Grounding DINO 1.5# 开集目标检测模型2年前08660
清华大学和新畅元科技推出Human4DiT:能够根据单幅图像及任意视点生成高质量、时空连贯的人类视频清华大学和新畅元科技推出新技术Human4DiT,它是一种用于生成高质量、时空一致的人类视频的4D扩散变换器(4D Diffusion Transformer)。这项技术可以从单张图片生成逼真的人类动...新技术# Human4DiT# 新畅元科技# 清华大学2年前08650
MaPa:根据文本描述为3D模型生成逼真的材质来自浙江大学、蚂蚁集团和深圳大学的研究人员推出MaPa,它能够根据文本描述为3D模型生成逼真的材质。与传统的纹理贴图不同,MaPa通过生成程序化的材质图(material graphs)来表示3D模型...新技术# 3D模型# MaPa2年前08640
LaVi-Bridge:将不同的语言模型和生成视觉模型结合起来,用于文生图来自香港大学、香港中文大学、香港科技大学的研究团队推出LaVi-Bridge,它能够将不同的语言模型和生成视觉模型结合起来,用于文本到图像的生成任务。通过利用LoRA和适配器技术,LaVi-Bridg...新技术# LaVi-Bridge# 文生图2年前08640
AI视频生成新框架Motion-I2V:让用户通过简单的轨迹绘制或区域选择来控制生成的视频内容来自NVIDIA AI、香港中文大学、商汤科技、清华大学、CPII、上海人工智能实验室、Avolution AI的研究人员推出图像到视频生成(I2V)新框架Motion-I2V,它是一个用于将静态图片...新技术# AI视频生成# Motion-I2V# 清华大学2年前08640
Follow-Your系列新框架Follow-Your-Emoji:基于扩散模型的肖像动画框架,生成富有表现力的表情动画来自香港科技大学、腾讯混元团队和清华大学的研究团队推出Follow-Your系列新框架Follow-Your-Emoji,这是一种基于扩散模型的肖像动画框架。简单来说,它可以根据一系列目标表情和动作标...新技术# Follow-Your-Emoji# 肖像动画框架2年前08610
文生图模型偏好优化方法MaPO(边界感知偏好优化):让计算机在学习生成图像时,能够更好地符合人类的偏好韩国科学技术研究院、Huggingface和高丽大学的研究人员推出一种新的文本到图像扩散模型的偏好优化方法,这种方法被称为“边界感知偏好优化”(Margin-aware Preference Opti...新技术# MaPO# 文生图模型# 边界感知偏好优化2年前08590