
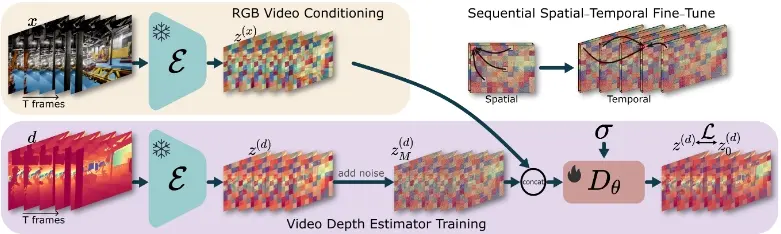
浙江大学、博洛尼亚大学、蚂蚁集团和Rock Universe的研究人员推出一种先进的视频深度估计方法ChronoDepth,它通过结合视频生成模型的先验知识,有效地提高了深度估计的准确性和时间一致性,对于需要处理视频内容的各种应用场景都非常有用。这项技术的核心挑战在于不仅要确保每一帧图像的深度估计准确,还要保证视频帧与帧之间的深度估计具有时间上的一致性,避免出现闪烁效应。
主要功能和特点:
- 时间一致性:ChronoDepth特别强调视频帧之间的深度估计要保持一致,这对于视频处理来说非常重要,可以避免视觉上的闪烁或抖动。
- 条件生成问题:与传统的从头开始开发深度估计器不同,ChronoDepth将深度预测任务转化为条件生成问题,利用现有视频生成模型中嵌入的先验知识。
- 训练策略:论文中提出了一种程序化的训练策略,先优化空间层,然后冻结空间层并优化时间层,以获得空间精度和时间一致性的最佳结果。
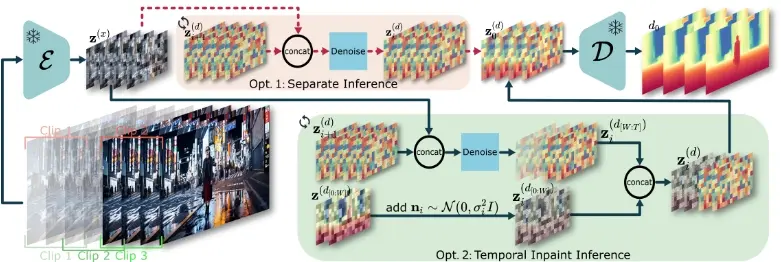
- 滑动窗口策略:在对任意长度的视频进行推理时,使用滑动窗口策略,利用之前预测的深度帧来引导后续帧的预测,以此提高时间一致性。
工作原理:
ChronoDepth的工作原理基于一个名为Stable Video Diffusion (SVD)的开源视频生成模型。它首先将视频深度估计问题重新定义为一个条件去噪扩散生成任务。在训练过程中,模型首先通过单帧深度数据训练空间层,然后使用多帧视频深度数据训练时间层,同时保持空间层不变。在推理时,模型使用滑动窗口策略,通过迭代去噪过程来恢复深度帧。
具体应用场景:
- 机器人和自动驾驶:在这些领域中,准确的深度估计对于导航和避障至关重要。
- 动画和虚拟现实:在动画制作和虚拟现实中,视频深度可以帮助创建更加逼真的三维场景。
- 深度引导的视频生成:ChronoDepth能够生成时间一致的深度图,可以作为视频生成模型的输入,帮助生成更加真实的视频内容。
- 新视角合成:使用ChronoDepth生成的深度图,可以从新的视角合成场景,用于增强现实或其他视觉特效。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











