
清华大学和新畅元科技推出新技术Human4DiT,它是一种用于生成高质量、时空一致的人类视频的4D扩散变换器(4D Diffusion Transformer)。这项技术可以从单张图片生成逼真的人类动作视频,并且能够在任意视角下进行观看。例如,你是一名动画师,需要为一个角色设计一系列复杂的舞蹈动作。使用Human4DiT,你只需提供一张角色的静态图片,系统就能生成该角色执行舞蹈动作的连贯视频,从任意视角观看都保持逼真和自然。这大大简化了传统动画制作中的手动关键帧设定和动作捕捉过程。这项技术通过其创新的4D变换器架构和多维训练策略,在人类视频生成领域提供了一种高效且逼真的解决方案,为多媒体应用开辟了新的可能性。
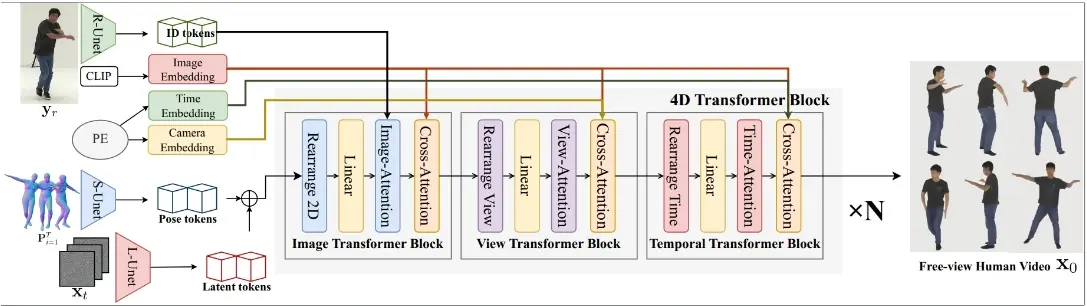
Human4DiT能够根据单幅图像及任意视点生成高质量、时空连贯的人类视频。Human4DiT框架结合了U-Net在条件注入方面的精确性与扩散变换器在跨视点和时间捕捉全局相关性的能力。核心是一个级联的4D变换器架构,它在视点、时间和空间维度上分解注意力,实现了对4D空间的有效建模。通过将人物身份、相机参数和时间信号注入相应的变换器中,我们实现了精确的条件设定。

主要功能:
- 视频生成: 从一张静态的参考图片生成动态的人类视频。
- 多视角生成: 能够生成单目视频、多视角视频、3D静态视频和自由视角视频。
- 时空一致性: 确保视频中的人物动作在时间和空间上保持连贯性。
主要特点:
- 4D变换器架构: 通过级联的4D变换器架构来分解在视角、时间和空间维度上的注意力,有效模拟4D空间。
- 精确的条件注入: 通过将人类身份、相机参数和时间信号注入到相应的变换器中,实现精确控制。
- 多维数据集和训练策略: 通过收集和利用多维数据集(包括图像、视频、多视角数据和3D/4D扫描),结合多维训练策略,提高模型的训练效果。
工作原理:
- U-Net和扩散变换器的结合: 使用U-Net提取像素对齐的特征,然后通过4D扩散变换器处理这些特征,利用自注意力机制学习复杂人类动作的全局相关性。
- 级联4D变换器: 通过将2D图像变换器块、时间变换器块和视角变换器块相互连接,形成一个4D变换器块,再将多个这样的4D变换器块级联起来,构建最终的4D变换器。
- 控制信号的注入: 通过不同的网络模块,将SMPL特征、人类身份、时间和相机参数等控制信号精确注入网络,实现对生成视频的精确控制。
具体应用场景:
- 虚拟现实(VR): 为虚拟现实应用生成逼真的人类动作视频,提升沉浸式体验。
- 动画制作: 在动画电影或电视制作中,快速生成或预览人物动作序列。
- 游戏开发: 为电子游戏角色生成自然流畅的动作,提高游戏的真实感和互动性。
- 电影制作: 在电影后期制作中,用于生成或增强人物动作场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











