适用于FLUX 和 SD3.5模型的新采样器Style-Friendly SNR:更好地捕捉独特的风格,并生成风格对齐度更高的图像近年来,大型扩散模型在生成高质量图像方面取得了显著进展。然而,这些模型在学习新的、个性化的艺术风格方面存在困难,这限制了独特风格模板的创建。传统的微调方法通常盲目地利用预训练中使用的目标和噪声水平分布...新技术# Style-Friendly SNR# 采样器1年前05560
图像生成框架OmniBooth:根据用户的多模态指令(如文本提示或图像参考)来生成具有空间控制和实例级定制化的图像香港科技大学和华为诺亚方舟实验室的研究人员推出图像生成框架OmniBooth,它可以根据用户的多模态指令(如文本提示或图像参考)来生成具有空间控制和实例级定制化的图像。简单来说,用户可以指定多个对象的...新技术# OmniBooth# 图像生成框架1年前05560
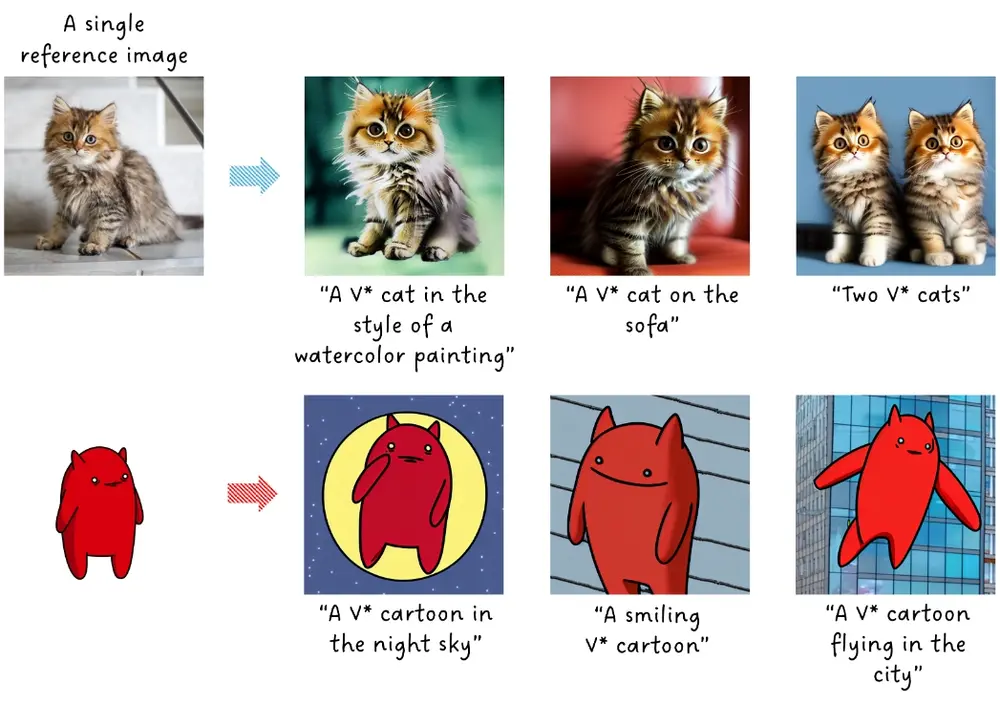
针对文生图模型的一次性个性化定制技术TextBoost:使用单个参考图像,通过微调文本编码器,来生成与文本提示相匹配的定制化图像韩国科学技术院推出一种针对文本到图像模型的一次性个性化定制技术TextBoost,这种方法使用单个参考图像,通过微调文本编码器,来生成与文本提示相匹配的定制化图像。例如,你想要通过一段描述来生成一张图...新技术# TextBoost# 个性化定制# 文生图模型2年前05560
FlashTex:使用LightControlNet实现快速可重新照明的网格纹理生成来自Roblox、卡内基梅隆大学、斯坦福大学的研究人员推出FlashTex技术,它能够快速地为3D模型生成可重新照明(relittable)的纹理。这项技术的核心在于,它可以根据用户提供的文字提示,自...新技术# 3D模型# FlashTex2年前05550
Liblib AI推出基于 ControlNet 框架RepText:实现中文文本的准确生成在当今的文本到图像生成领域,尽管模型在生成视觉上吸引人的图像方面取得了显著进步,但在处理精确且灵活的排版元素时,尤其是对于非拉丁字母,仍然存在明显的局限性。这种局限性主要源于文本编码器在处理多语言输入...新技术# controlnet# Liblib AI# RepText11个月前05540
基于多模态扩散模型的创新框架CreativeSynth:用于创意融合和合成视觉艺术来自字节跳动、中科院自动化研究所、中国科学院大学人工智能学院等机构的研究人员,提出了一个名为CreativeSynth的创新框架,它基于多模态扩散模型,能够协调多模态输入并在艺术图像生成领域实现多任务...新技术# CreativeSynth# 多模态扩散模型2年前05540
肖像动画新技术EchoMimic:将静态的肖像照片转化为逼真的动态视频蚂蚁集团支付宝终端技术部推出肖像动画新技术EchoMimic,它可以将静态的肖像照片转化为逼真的动态视频。EchoMimic创新性地结合音频与面部标志点进行联合训练,并通过一项新颖的训练策略,使其不仅...新技术# EchoMimic# 肖像动画2年前05530
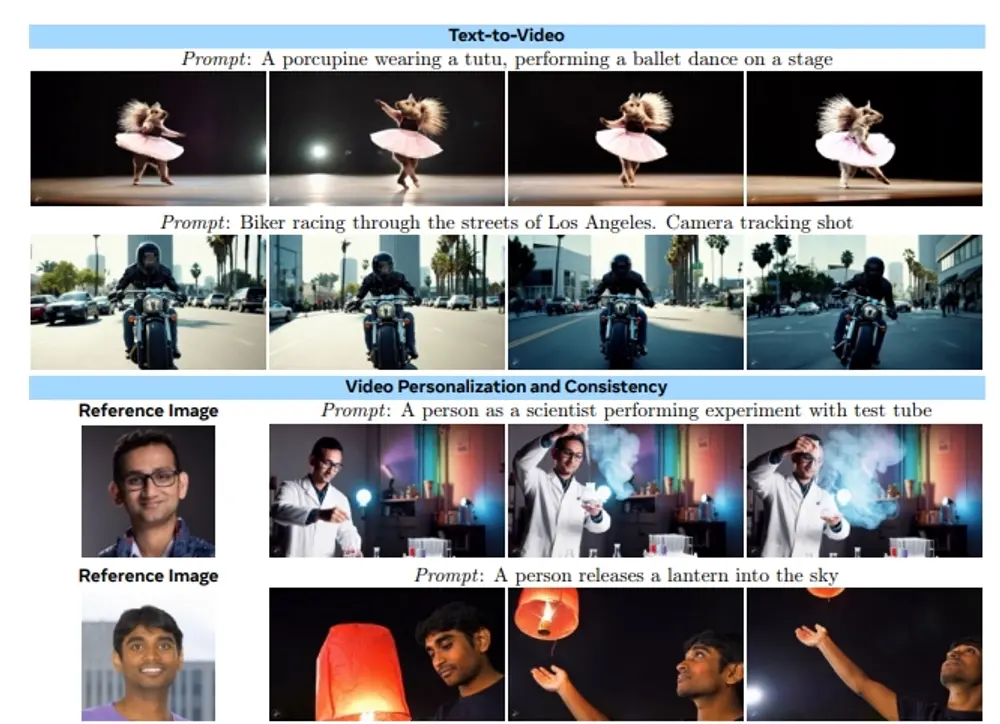
Meta推出新型视频生成模型Movie Gen:不仅能制作高清视频,还能为视频配上声音Meta宣布推出一款新AI视频生成器Movie Gen,这款工具不仅能制作高清视频,还能为视频配上声音。据Meta介绍,Movie Gen可通过简单的文字输入,自动生成全新的视频内容。此外,它还能编辑...新技术# Meta# Movie Gen# 视频生成模型1年前05520
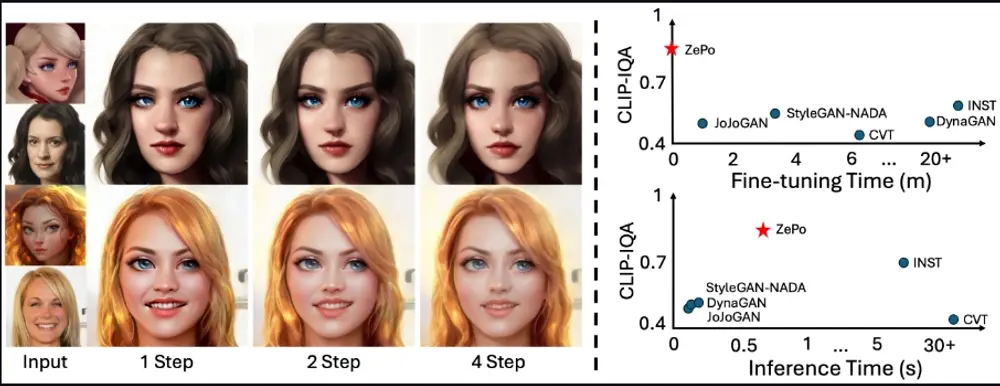
基于扩散模型的无需反转的人像风格化框架ZePo:在无需任何模型微调的情况下,快速生成具有特定艺术风格的肖像图像上海科技大学信息科学技术学院和中国科学院自动化研究所的研究人员推出了一种基于扩散模型的无需反转的人像风格化框架ZePo,它能够在无需任何模型微调的情况下,仅需四个采样步骤就能实现内容和风格特征的融合...新技术# ZePo# 人像风格化2年前05510
文本嵌入模型nomic-embed-text-v1:完全开源可复现Nomic AI发布文本嵌入模型nomic-embed-text-v1,这是一个开源的、可复现的、拥有8192个上下文长度的英文文本嵌入模型。这个模型在处理短文本和长文本任务上的表现超过了OpenAI...新技术# nomic-embed-text-v1# 文本嵌入模型2年前05510
文生视频新技术FIFO-Diffusion:无需训练即可从文本生成无限长度的视频首尔国立大学推出文生视频新技术FIFO-Diffusion,它基于预训练的扩散模型,用于文本条件视频生成。简单来说,FIFO-Diffusion能够根据文本描述生成无限长度的视频,而且不需要额外的训练...新技术# FIFO-Diffusion# 文生视频2年前05500
视频运动迁移模型MotionMaster:在不需要训练的情况下,实现视频中相机运动的转移来自上海交通大学、腾讯优图实验室和哈尔滨工业大学的研究人员推出一个无需训练的视频运动迁移模型MotionMaster,它能够在不需要训练的情况下,实现视频中相机运动的转移。这意味着你可以将一个视频中的...新技术# MotionMaster# 视频运动迁移模型2年前05500