新型视频生成方法TRF:控制视频内容在给定的起始和结束帧之间进行生成来自马克斯·普朗克智能系统研究所、Adobe和加州大学圣地亚哥分校的研究团队推出新型视频生成方法Time Reversal Fusion(时间反转融合,简称TRF),它能够控制视频内容在给定的起始...新技术# TRF# 视频生成2年前05480
新型视频生成模型Loong:基于自回归大语言模型,能够生成长达一分钟的连贯、内容丰富的视频香港大学和字节跳动的研究人员推出新型视频生成模型Loong,它基于自回归大语言模型(LLMs),能够生成长达一分钟的连贯、内容丰富的视频。这在视频生成领域是一个挑战,因为视频通常包含大量的帧,每帧都需...新技术# Loong# 自回归大语言模型1年前05440
Adobe推出全新图像编辑方法TurboEdit:实现基于文本的即时图像编辑Adobe Research推出了一种全新的图像编辑方法TurboEdit,它能够实现基于文本的即时图像编辑,它利用了所谓的"少步骤扩散模型"(few-step diffusion models),在...新技术# TurboEdit# 图像编辑2年前05440
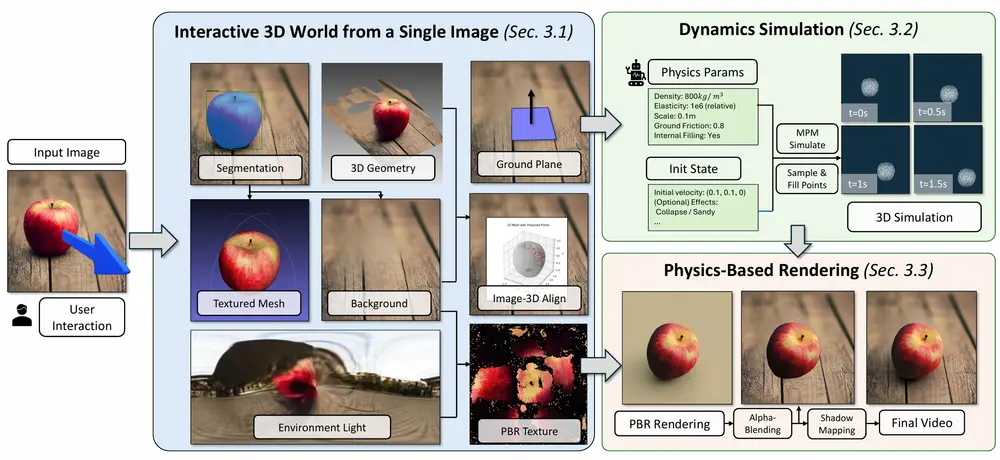
PhysGen3D:从一张图片创造真实物理世界的交互式3D场景清华大学、伊利诺伊大学厄巴纳香槟分校和哥伦比亚大学的研究人员携手推出了一项创新成果—PhysGen3D,将单一图像转化为非模态、以相机为中心的交互式 3D 场景。 项目主页:https://by-lu...新技术# 3D场景# PhysGen3D12个月前05410
创新框架FeatUp:提高深度学习模型中图像特征的空间分辨率,而不会损失原有的语义信息来自麻省理工、微软、Adobe和谷歌的研究团队推出创新框架FeatUp,它能够提高深度学习模型中图像特征的空间分辨率,而不会损失原有的语义信息。在计算机视觉领域,深度学习模型通常会从图像中提取特征,这...新技术# FeatUp# 深度模型2年前05410
新型图像生成框架ControlAR:根据空间控制信息生成可控制的高质量图像华中科技大学信息与通信学院、香港大学计算机科学系和vivo AI 实验室的研究人员推出新型图像生成框架ControlAR,它能够根据空间控制信息生成可控制的高质量图像。简单来说,ControlAR能够...新技术# ControlAR# 图像生成框架1年前05390
3D场景编辑框架TIP-Editor来自腾讯人工智能实验室、中山大学的研究人员推出3D场景编辑框架TIP-Editor,它允许用户不仅通过文本提示,还通过图像提示来精确地编辑现有的基于3D高斯散射(GS)的辐射场。TIP-Editor的...新技术# 3D场景编辑# TIP-Editor2年前05390
用于加速DiT模型的训练和推理过程的方法HarmoniCa商汤科技研究院、北京航空航天大学、莫纳什大学和香港科技大学推出一种用于加速DiT模型的训练和推理过程的方法HarmoniCa,通过基于Step-Wise去噪训练(SDT)和图像错误代理引导目标(IEP...新技术# DiT模型# HarmoniCa1年前05380
新型指令式图像编辑框架FireEdit:利用区域感知的视觉语言模型(VLM),实现了对用户指令的细粒度理解和精确图像编辑中山大学深圳校区、腾讯混元、清华大学和香港科技大学的研究人员推出新型指令式图像编辑框架FireEdit,它通过利用区域感知的视觉语言模型(VLM),实现了对用户指令的细粒度理解和精确图像编辑。Fire...新技术# FireEdit# 图像编辑# 视觉语言模型11个月前05370
BootPIG:零样本个性化图像生成来自Salesforce的研究人员提出了一种新架构BootPIG,旨在实现零样本个性化图像生成。该架构基于预训练的文本到图像模型Stable Diffusion,通过引入参考图像来指导生成的对象外观...新技术# BootPIG# Stable Diffusion2年前05370
DragAPart:一张图片和加一系列拖动操作作为输入,生成新图片牛津大学视觉几何小组推出DragAPart,它接收一张图片和一系列拖动操作作为输入,能够生成该物体在新状态下的新图片,且新图片与拖动操作所表达的动作相匹配。与先前主要关注物体重新定位的工作不同,Dra...新技术# DragAPart2年前05330
AI动画生成框架Keyframer:利用GPT4生成动画来自苹果的研究人员推出一款利用大语言模型(LLMs)生成动画的框架Keyframer,它利用大语言模型(LLMs)来帮助设计师通过自然语言描述来创建动画。 论文地址 Keyframer的主要功能包括从...新技术# AI动画# CSS动画# Keyframer2年前05330