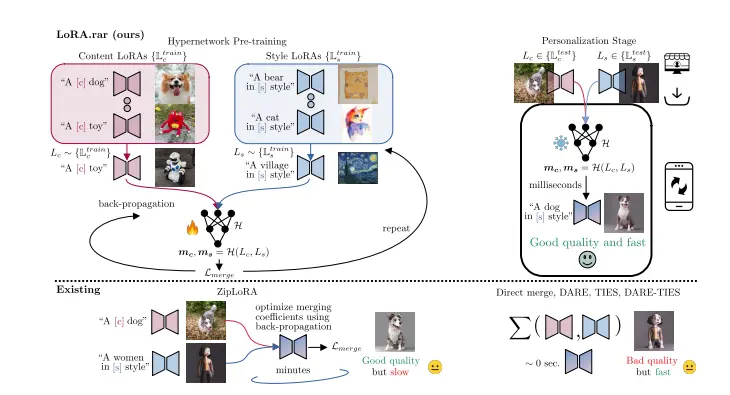
用于主题-风格条件图像生成新技术LoRA.rar:通过使用超网络(hypernetworks)来学习合并内容和风格的LoRAs,从而实现个性化图像的快速生成三星和帕多瓦大学的研究人员推出一种用于主题-风格条件图像生成技术LoRA.rar,通过使用超网络(hypernetworks)来学习合并内容(subject)和风格(style)的低秩适应参数(LoR...新技术# LoRA.rar1年前02500
专为DiT架构模型设计的运动转移方法DiTFlow牛津大学、Snap和MBZUAI的研究人员介绍了一种名为DiTFlow的方法,它是一种专为DiT架构模型设计的运动转移方法。DiTFlow通过分析参考视频,提取出一种名为注意力运动流(Attentio...新技术# DiTFlow# DiT模型1年前03400
高通AI研究院推出专为移动设备优化的视频编辑模型MoViE:能够在手机上实现每秒12帧的快速视频编辑高通AI研究院推出一个专为移动设备优化的视频编辑模型MoViE,能够在手机上实现每秒12帧的快速视频编辑。MoViE通过一系列优化,使得在移动设备上进行视频编辑变得可行,这些优化包括架构优化、轻量级自...新技术# MoViE# 视频编辑模型# 高通1年前03040
高通AI研究院推出一个为移动设备优化的视频生成模型MobileVD高通AI研究院推出了一个为移动设备优化的视频生成模型Mobile Video Diffusion(MobileVD),该模型的目标是在保持生成视频的质量和控制力的同时,显著降低计算需求,使得在移动设备...新技术# MobileVD# 视频生成模型1年前03860
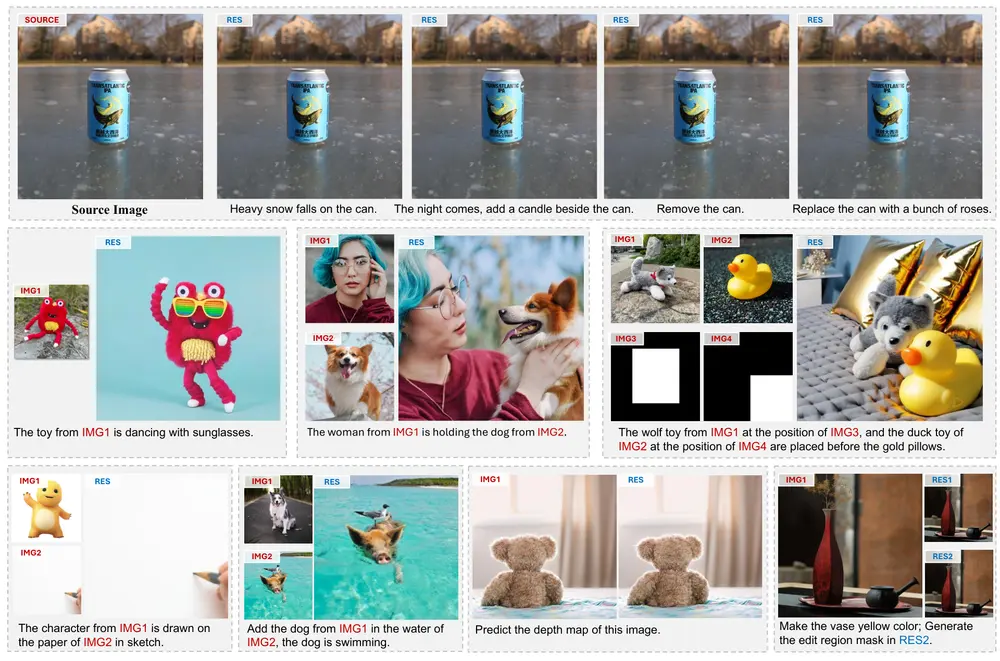
解决图像生成与编辑任务的统一框架UniReal图像生成和编辑任务在计算机视觉领域中具有广泛的应用,如图像合成、风格迁移、图像修复等。然而,现有的解决方案通常针对特定任务设计,缺乏一个统一的框架来处理多种图像级任务。香港大学和Adobe Resea...新技术# UniReal# 图像生成# 图像编辑1年前02920
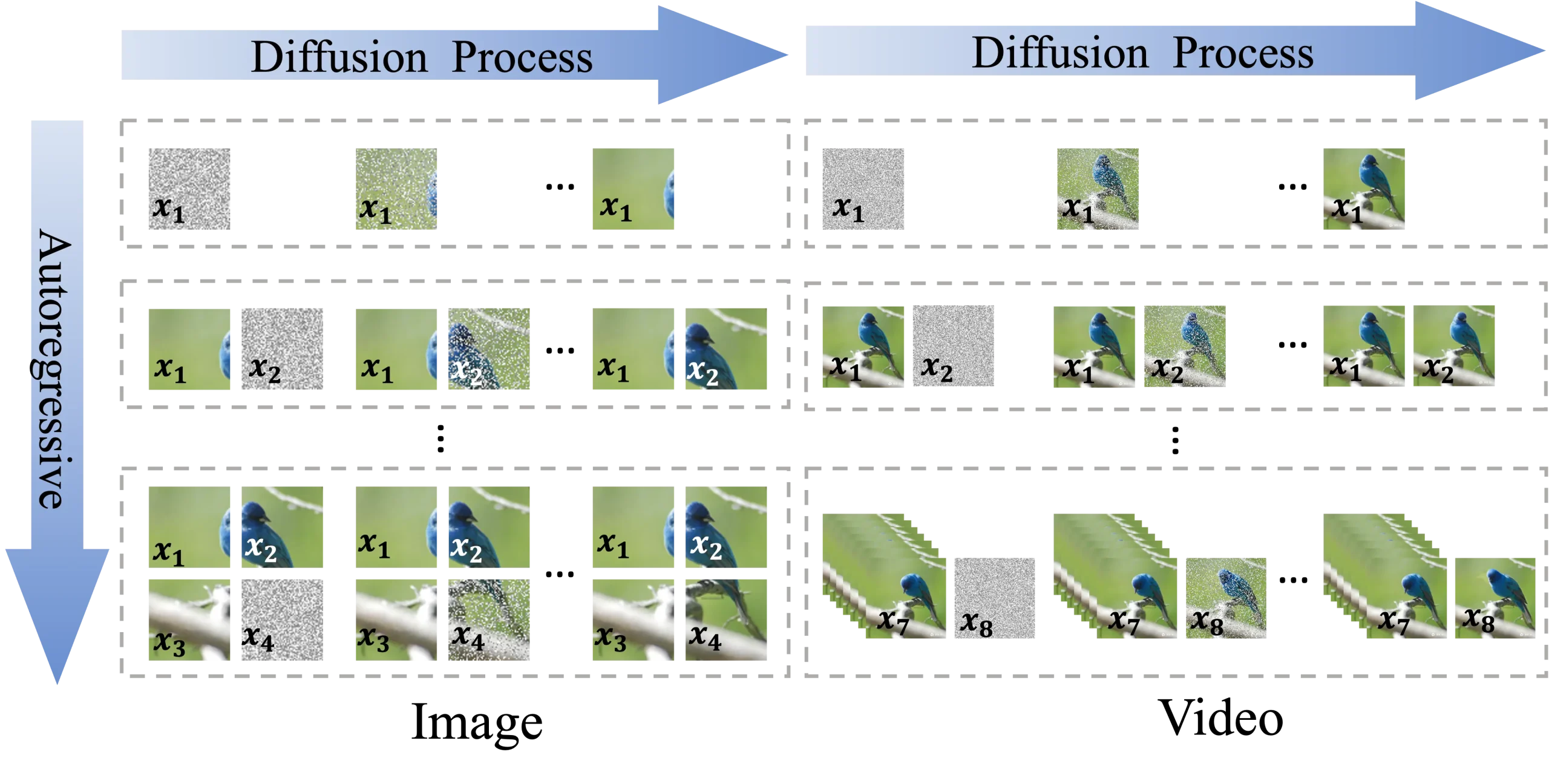
ACDIT:介于自回归模型和扩散模型之间的插值方法,用于处理视觉信息清华大学和字节跳动的研究人员推出ACDIT,它是一种介于自回归模型和扩散模型之间的插值方法,用于处理视觉信息。ACDIT的核心思想是将自回归建模扩展到块级别,而不是单个文本标记,使得每个块的生成可以基...新技术# ACDIT1年前02700
苹果推出用于文本和图像条件下的视频生成新方法STIV苹果公司介绍了一个名为STIV(Scalable Text and Image Conditioned Video Generation)的系统,它是一种用于文本和图像条件下的视频生成方法。STIV系...新技术# STIV# 苹果1年前02770
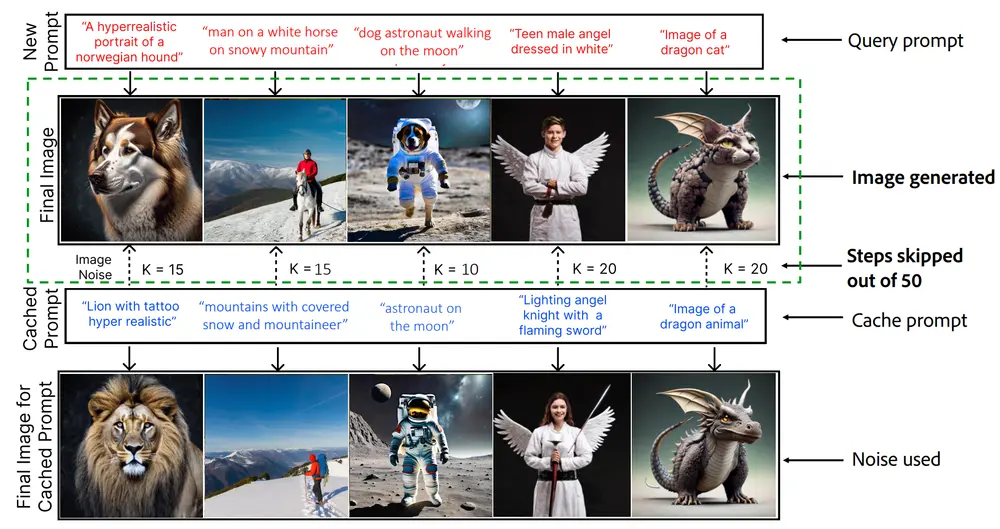
新型文本到图像生成系统NIRVANA:利用近似缓存技术,高效地服务基于扩散模型的文本到图像生成任务Adobe和伊利诺伊大学厄巴纳-香槟分校的研究人员介绍了一种名为NIRVANA的新型文本到图像生成系统,它利用了一种称为近似缓存(Approximate Caching)的技术,旨在高效地服务基于扩散...新技术# NIRVANA# 文生图1年前03220
华为诺亚方舟实验室推出多模态大语言模型ILLUME华为诺亚方舟实验室发布多模态大语言模型ILLUME,旨在无缝集成图像和文本的理解与生成。ILLUME凭借其创新的架构和训练策略,在显著减少预训练所需数据量的同时,达到了最先进的性能。ILLUME基于统...新技术# ILLUME# 华为诺亚方舟实验室# 多模态大语言模型1年前02760
3DTrajMaster:专注于在视频生成中控制多实体的三维(3D)运动轨迹香港中文大学、快手科技和浙江大学的研究人员介绍了3DTrajMaster,一个用于多实体3D运动可控视频生成的强大控制器。与传统的2D控制信号相比,3DTrajMaster利用6自由度(6DoF)姿态...新技术# 3DTrajMaster# 3D运动轨迹1年前02700
端到端的高质量ID一致性人类跳舞视频生成新框架StableAnimator近年来,人像动画生成模型在图像和视频领域取得了显著进展,但它们在身份一致性(ID一致性)方面仍然面临挑战。传统的扩散模型虽然能够生成高质量的视频,但在长时间序列中保持人物的身份特征(如面部表情、发型等...新技术# StableAnimator# 视频生成框架1年前02900
MotionShop:用于视频扩散模型中的零样本(Zero-Shot)运动转移方法,通过混合分数引导(MSG)实现近年来,扩散模型在图像和视频生成领域取得了显著进展,但在运动迁移任务中,如何将一个视频中的运动模式迁移到另一个视频中,同时保持内容的完整性,仍然是一个具有挑战性的问题。传统的运动迁移方法通常依赖于复杂...新技术# MotionShop# MSG1年前02740