近年来,人像动画生成模型在图像和视频领域取得了显著进展,但它们在身份一致性(ID一致性)方面仍然面临挑战。传统的扩散模型虽然能够生成高质量的视频,但在长时间序列中保持人物的身份特征(如面部表情、发型等)往往不够稳定,导致生成的视频中出现身份漂移或不一致的问题。为了解决这一问题,复旦大学、微软、虎牙和卡内基梅隆大学(CMU)的研究团队提出了 StableAnimator,这是首个专门针对身份一致性优化的端到端视频扩散框架。
- 项目主页: https://francis-rings.github.io/StableAnimator
- GitHub: https://github.com/Francis-Rings/StableAnimator
- 模型:https://huggingface.co/FrancisRing/StableAnimator
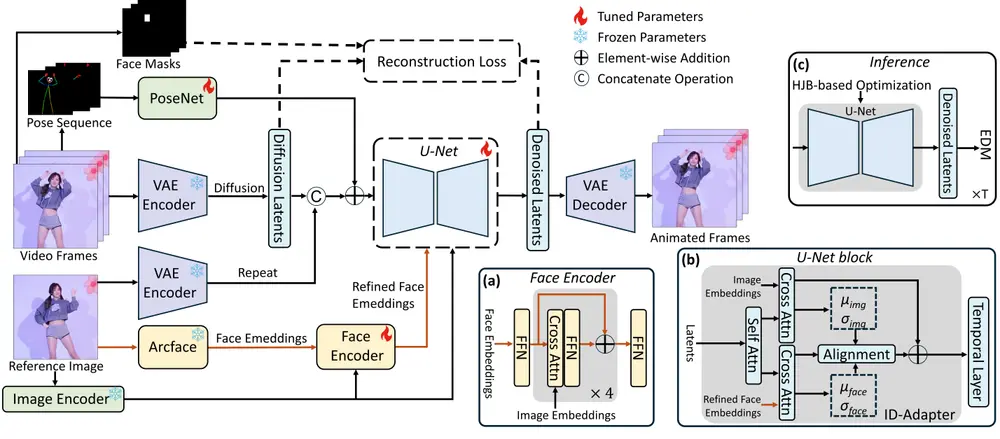
StableAnimator 的核心目标是根据参考图像和姿态序列生成高质量的视频,同时确保生成的每一帧都保持与参考图像的身份一致性,而无需任何后处理。该框架通过设计专门用于训练和推理的模块,结合了多种技术创新,显著提升了生成视频的身份一致性。

例如,我们有一张某个名人的静态照片,我们想要创建一个视频,其中这个名人在做一个演讲。使用StableAnimator,我们可以将这个静态图像作为参考,并提供一系列代表演讲者姿势的序列,StableAnimator将生成一个视频,其中名人的面部表情和身体动作与演讲内容同步,同时保持其独特的身份特征,如面貌和风格。
核心技术与创新点
1. 全局内容感知的面部编码器
为了确保生成视频中的人物面部与参考图像保持一致,StableAnimator 首先通过现成的提取器分别计算图像和面部嵌入。具体来说:
- 图像嵌入:使用预训练的图像编码器提取输入图像的整体视觉特征。
- 面部嵌入:使用预训练的面部识别模型提取参考图像中的人脸特征。
随后,StableAnimator 引入了一个 全局内容感知的面部编码器,该编码器将图像嵌入与面部嵌入进行交互,进一步优化面部嵌入。这种设计使得模型能够在生成过程中更好地捕捉和保留参考图像中的面部细节,从而提高身份一致性。
2. 分布感知身份适配器
为了在生成过程中保持身份一致性,StableAnimator 引入了一种新颖的 分布感知身份适配器。该适配器通过以下机制工作:
- 对齐机制:在每个时间步上,适配器通过对齐机制将当前帧的面部特征与参考图像的面部特征对齐,确保生成的每一帧都尽可能接近参考图像的身份特征。
- 避免时序层干扰:传统的时间卷积层可能会引入不必要的噪声,影响身份一致性。StableAnimator 通过分布感知身份适配器,确保时序信息不会干扰面部特征的对齐过程,从而保持生成视频的身份一致性。
3. 基于Hamilton-Jacobi-Bellman方程(HJB)的优化方法
在推理阶段,StableAnimator 提出了一种基于 Hamilton-Jacobi-Bellman方程(HJB) 的优化方法,用于进一步增强面部质量。具体来说:
- HJB方程求解:HJB方程是一种用于最优控制问题的偏微分方程。StableAnimator 将其应用于扩散去噪过程中,通过求解HJB方程来约束去噪路径,确保生成的每一帧都尽可能接近参考图像的身份特征。
- 与扩散去噪集成:求解HJB方程的过程可以与扩散去噪过程无缝集成,所得解约束了去噪路径,从而有助于身份一致性。这种方法不仅提高了生成视频的质量,还确保了生成过程中的人物面部特征保持稳定。
4. 端到端训练与推理
StableAnimator 是一个端到端的框架,能够在训练和推理阶段自动优化身份一致性。通过结合上述技术创新,StableAnimator 能够在生成高质量视频的同时,确保每一帧都与参考图像保持高度一致,而无需任何后处理步骤。
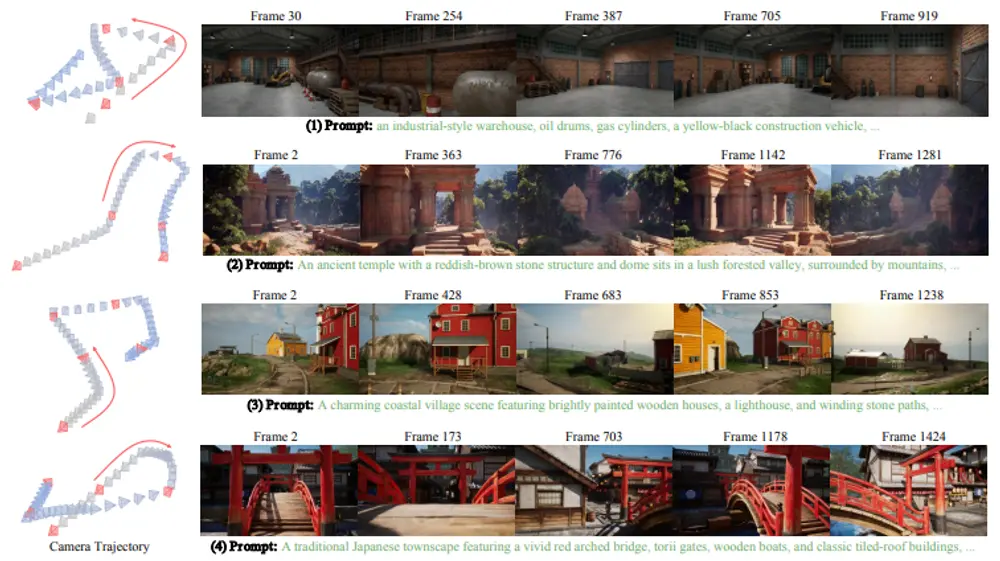
实验结果与性能评估
研究人员在多个基准测试上对 StableAnimator 进行了评估,实验结果表明,StableAnimator 在定性和定量上都表现出色,显著优于现有的方法。具体来说:
- 定性评估:生成的视频在视觉上具有高度的身份一致性,人物的面部特征(如表情、发型等)在整个视频中保持稳定,没有出现明显的身份漂移现象。
- 定量评估:通过计算生成视频与参考图像之间的相似度指标(如LPIPS、FID等),StableAnimator 在多个基准测试中均取得了最佳性能,展示了其在身份一致性方面的优越性。
此外,StableAnimator 还能够处理复杂的姿态变化和多视角场景,生成的视频不仅在身份一致性方面表现出色,还在动作流畅性和视觉质量上达到了较高水平。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











