多模态模型Transfusion:能够同时处理离散数据(如文本)和连续数据(如图像)Meta、Waymo和南加州大学的研究人员推出多模态模型Transfusion,它能够同时处理离散数据(如文本)和连续数据(如图像)。Transfusion的核心思想是将语言模型的下一个词预测(nex...新技术# Transfusion# 多模态模型2年前07560
韩国科学技术院提出超分辨率框架Chain-of-Zoom(CoZ):突破单图像超分辨率模型的放大极限近年来,单图像超分辨率(SISR) 模型在固定缩放因子下已经能够生成接近真实照片质量的图像。然而,一旦尝试超出训练范围进行放大,就会出现模糊、伪影等问题,严重影响视觉效果。 此外,如果想获得更高倍数的...新技术# Chain-of-Zoom# CoZ# 超分辨率10个月前07540
新型框架PhysAvatar:将物理模拟和逆向渲染技术相结合,创建逼真的3D虚拟人物来自斯坦福大学、卡内基梅隆大学、谷歌和慕尼黑工业大学的研究人员推出新型框架PhysAvatar,它将物理模拟和逆向渲染技术相结合,能够自动从多视角视频数据中估计人体的形状和外观,以及衣物面料的物理参数...新技术# 3D虚拟人物# PhysAvatar2年前07530
单前向视频生成模型SF-V:通过一次前向传播快速生成高质量、运动连贯的视频Snap和罗格斯大学的研究人员推出新型单步视频生成模型SF-V,此模型的核心特点是能够通过一次前向传播(single forward pass)快速生成高质量、运动连贯的视频,这对于需要实时视频合成和...新技术# SF-V# 单前向视频生成模型2年前07520
专注于二次元角色的动画方法MikuDance:将二次元角色根据 Open Pose 姿势生成对应动画武汉大学、阶跃星辰和字节跳动的研究人员推出MikuDance,它是一个基于扩散的动画制作流程,用于为风格化的角色艺术作品添加混合运动动力学,使其动起来。MikuDance的核心在于它能够处理复杂的角色...新技术# MikuDance# 二次元1年前07490
建立在多模态大语言模型基础上的统一文本到图像生成和检索框架TIGeR来自新加坡国立大学 NExT++ 实验室、南洋理工大学、香港理工大学和哈尔滨工业大学(深圳)的研究人员推出一个统一的文本到图像生成和检索框架TIGeR,这个框架建立在多模态大语言模型(MLLMs)的基...新技术# TIGeR# 文生图2年前07470
英伟达推出视频生成模型CMD:解决现有视频生成技术在处理高维视频数据时所面临的高内存和计算需求问题英伟达推出新型的视频生成模型内容-运动潜在扩散模型(Content-Motion Latent Diffusion Model,简称CMD),这个模型是为了解决现有视频生成技术在处理高维视频数据时所面...新技术# CMD# 英伟达2年前07460
OpenAI公开AI视频生成模型Sora:可创建长达 60 秒的视频OpenAI公开了AI视频生成(文生视频)模型Sora,它可以创建长达 60 秒的视频,其中包含高度详细的场景、复杂的摄像机运动和具有生动情感的多个角色。 官方介绍 以下是官方介绍全文翻译: 我们正在...新技术# AI视频生成模型# OpenAI# Sora2年前07460
通用且即插即用的加速方案AsyncDiff:加速SD模型的运行速度新加坡国立大学推出通用且即插即用的加速方案AsyncDiff,它能够显著加速扩散模型(diffusion models)的运行速度。扩散模型是一种强大的生成模型,能够创造出各种数据,比如图片和视频,但...新技术# AsyncDiff# SD模型2年前07450
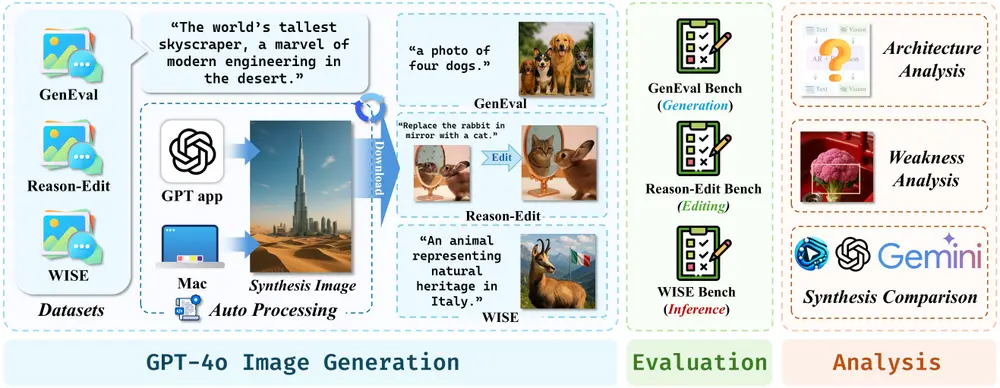
首个针对 GPT-4o 图像生成能力进行定量和定性评估的基准测试GPT-ImgEval北京大学深圳研究生院、中山大学、Rabbitpre AI、上海人工智能实验室、深圳大学和香港科技大学(广州)的研究人员发布首个针对 GPT-4o 图像生成能力进行定量和定性评估的基准测试GPT-Img...新技术# GPT-4o# GPT-ImgEval12个月前07400
一致性模型的强化学习RLCM:提升图像生成的速度和质量来自康奈尔大学的研究团队推出RLCM(Reinforcement Learning for Consistency Models, 一致性模型的强化学习),RLCM提供了一种有效的方法来提升图像生成的...新技术# RLCM# 一致性模型2年前07400
腾讯混元团队推出支持中英双语提示词的文生图模型Hunyuan-DiT:能够根据上下文与用户进行多轮多模态对话,生成并优化图像腾讯混元团队推出支持中英双语提示词的文生图模型Hunyuan-DiT,它特别擅长理解中文和英文的文本提示,并据此生成图像,Hunyuan-DiT能够根据上下文与用户进行多轮多模态对话,生成并优化图像...新技术# Hunyuan-DiT# 提示词# 文生图模型2年前07390