近年来,单图像超分辨率(SISR) 模型在固定缩放因子下已经能够生成接近真实照片质量的图像。然而,一旦尝试超出训练范围进行放大,就会出现模糊、伪影等问题,严重影响视觉效果。
此外,如果想获得更高倍数的放大能力,往往需要重新训练模型,这不仅成本高昂,还效率低下。
面对这一挑战,来自韩国科学技术院(KAIST)的研究团队提出了一种全新的解决方案——Chain-of-Zoom(CoZ),它是一种不依赖特定模型的通用框架,可以在不额外训练的前提下,实现超高倍数的图像放大,甚至达到 256x 倍 的惊人效果。
- 项目主页:https://bryanswkim.github.io/chain-of-zoom
- GitHub:https://github.com/bryanswkim/Chain-of-Zoom
- Demo:https://huggingface.co/spaces/alexnasa/Chain-of-Zoom

为什么传统 SISR 在高倍放大时会失败?
目前主流的 SISR 模型大多是在特定放大倍率(如 4x)下进行训练的。当试图用这些模型进行更大倍数的放大时,会出现以下问题:
- ✅ 图像变得模糊,细节丢失;
- ✅ 出现伪影(如纹理错误、边缘失真);
- ❌ 无法通过简单重复使用模型来提升分辨率;
- 💸 若需更高倍数,必须重新训练,成本极高。
这就带来了一个关键问题:
如何利用现有的 SISR 模型,在无需再训练的情况下,实现远超其训练目标的高质量放大?
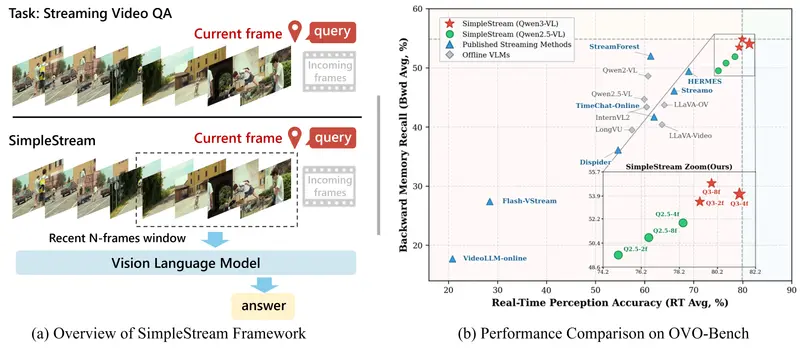
Chain-of-Zoom:一种“链式放大”的新思路
Chain-of-Zoom(CoZ)的核心思想是:
将一次大跨度放大,分解为多个小步骤的连续过程,并在每一步中引入语义提示,增强视觉线索。
它的基本流程如下:
- 从低分辨率图像出发;
- 使用预训练的视觉语言模型(VLM)生成描述性文本提示;
- 将图像 + 文本提示输入骨干 SISR 模型,生成下一阶段的高分辨率图像;
- 重复上述步骤,直到达到目标分辨率。
通过这种“自回归链式”方式,CoZ 可以让一个原本只能处理 4x 放大的模型,逐步完成 16x、32x,甚至 256x 超高分辨率输出,同时保持良好的图像质量和语义一致性。
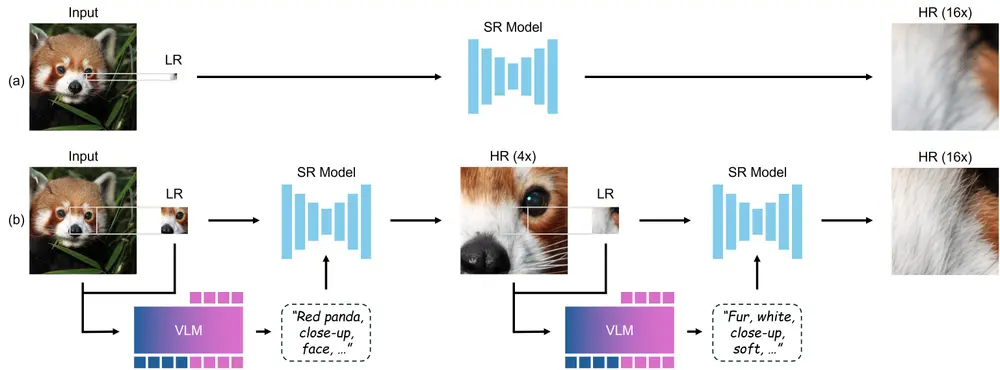
关键创新点
🔍 多尺度感知文本提示
由于在高倍放大过程中原始图像提供的视觉信息越来越少,CoZ 引入了 VLM(视觉语言模型)来生成多尺度语义提示,帮助模型理解当前图像的上下文。
这些提示包括:
- “画面中是一只狗”
- “背景是水边环境”
- “前景有树枝”
这些语义信息作为辅助条件,显著提升了重建的准确性和自然度。
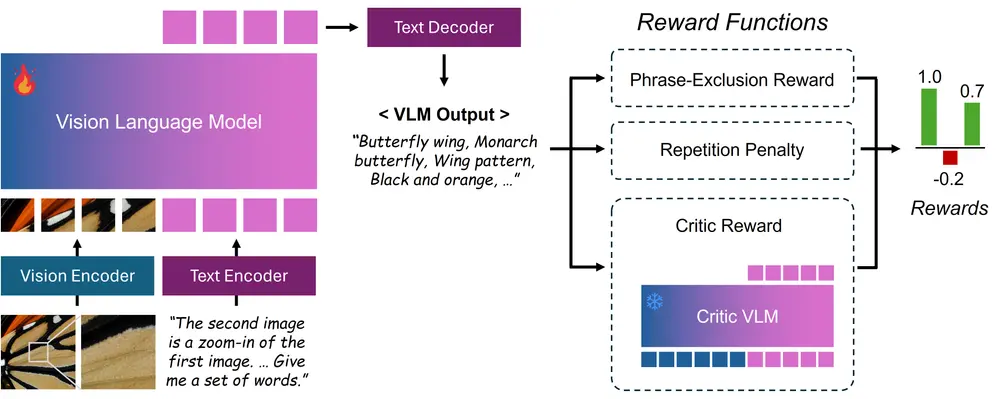
🧠 强化学习微调:GRPO + 批评 VLM
为了使生成的提示更符合人类审美偏好,研究人员进一步对提示提取器进行了强化学习优化:
- 使用 GRPO(广义奖励策略优化)对 VLM 进行微调;
- 利用另一个批评 VLM 对提示质量打分;
- 引入短语排除与重复惩罚机制,提高提示的简洁性和相关性。
这套流程确保了 CoZ 在每次放大步骤中都能获得最有效的语义引导。
实验结果:CoZ 突破放大瓶颈
研究人员对比了几种不同方法在高倍放大下的表现:
| 方法 | 放大能力 | 图像质量 |
|---|---|---|
| 最近邻插值 | 差 | 严重模糊 |
| 单步直接放大 | 一般 | 高倍时出现伪影 |
| CoZ(无提示) | 较好 | 细节恢复较弱 |
| CoZ(结合 VLM 提示) | 极佳 | 清晰、自然、语义连贯 |
实验表明,只有 CoZ 结合经过 GRPO 微调的 VLM 提示,才能在超高倍数下维持高质量输出。

技术优势总结
- ✅ 无需重新训练模型,即可实现高达 256x 的图像放大;
- ✅ 支持多种 SISR 主干模型,具有良好的通用性;
- ✅ 多尺度语义提示机制,有效补充缺失的视觉信息;
- ✅ 基于 RLHF 的提示优化流程,提升图像生成的人类感知质量;
- ✅ 轻量高效设计,可在标准 GPU 上运行。
应用前景广泛
CoZ 不仅适用于图像修复、老照片增强等图像处理任务,还可用于:
- 📷 高清图像生成;
- 🎥 视频超分与动画制作;
- 🧠 AI 视觉辅助创作工具;
- 📱 移动端高清显示优化;
对于希望将现有 SISR 模型发挥到极致的技术人员来说,CoZ 提供了一条新的路径。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...