Meta AI 推出高效图像生成新方法Token-Shuffle:在 Transformer 中减少图像 Token自回归(AR)模型在语言生成领域取得了巨大成功,但在高分辨率图像合成中的应用却面临严峻挑战。与文本不同,图像需要数千个 token 来表示,导致计算成本呈二次方增长。这使得大多数基于 AR 的多模态模...新技术# Meta AI# Token-Shuffle# 图像生成9个月前02760
微软研究院推出 MMInference:为长上下文视觉-语言模型注入加速动力随着AI技术的不断进步,视觉-语言模型(VLM)在机器人、自动驾驶、医疗保健等领域的应用日益广泛。然而,将长上下文能力与视觉理解相结合虽然显著提升了 VLM 的潜力,但也带来了新的挑战——尤其是在预填...新技术# MMInference# 微软9个月前03070
DistanceSampler:基于相对距离的实验性采样器开发者 Extraltodeus 近日打造了一个基于相对距离的自定义实验性采样器——DistanceSampler。该采样器的设计理念是在开始阶段获得更精确的结果,因为大部分工作都在这个阶段完成。随后...新技术# DistanceSampler# 采样器9个月前02400
字节跳动推出统一的视频生成框架Phantom :通过跨模态对齐实现主体一致性的视频生成字节跳动的研究人员推出一个统一的视频生成框架Phantom ,通过跨模态对齐实现主体一致性的视频生成(Subject-to-Video, S2V),用于单主体和多主体参考,构建在现有的文本到视频和图像...新技术# Phantom# 字节跳动# 视频生成9个月前02820
Chipmunk:无需训练的动态稀疏性加速DiT模型的推理过程扩散模型(Diffusion Models)近年来在图像生成和视频生成领域表现出色,但其计算复杂度也成为了性能瓶颈。特别是基于DiT架构的模型,如FLUX、HunyuanVideo 等,其注意力层和多...新技术# Chipmunk# DiT模型# FLUX9个月前03640
新型框架Uni3C:通过3D增强技术实现对视频生成中相机和人体运动的精确控制阿里达摩院、复旦大学和湖畔实验室的研究人员推出新型框架Uni3C,旨在通过3D增强技术实现对视频生成中相机和人体运动的精确控制。Uni3C通过将相机控制和人体运动控制统一到一个框架中,解决了现有方法中...新技术# Uni3C# 人体运动# 视频生成9个月前05370
新型指令式图像编辑框架FireEdit:利用区域感知的视觉语言模型(VLM),实现了对用户指令的细粒度理解和精确图像编辑中山大学深圳校区、腾讯混元、清华大学和香港科技大学的研究人员推出新型指令式图像编辑框架FireEdit,它通过利用区域感知的视觉语言模型(VLM),实现了对用户指令的细粒度理解和精确图像编辑。Fire...新技术# FireEdit# 图像编辑# 视觉语言模型10个月前04780
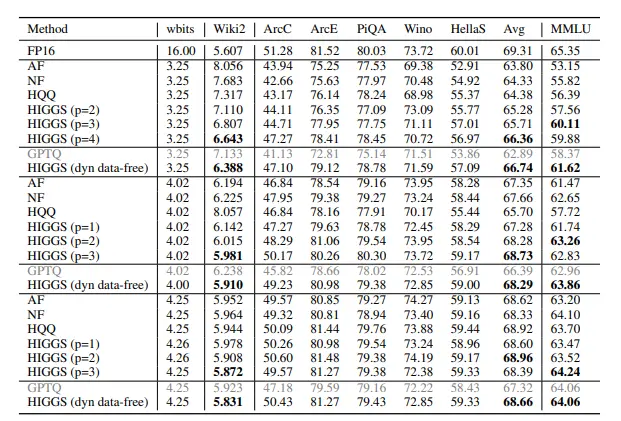
高效的无数据量化方法HIGGS:可快速压缩大语言模型而无需显著牺牲质量近年来,大语言模型(LLM)的快速发展为AI领域带来了巨大的潜力,但其对计算资源的高需求也限制了广泛应用。无论是研究机构还是个人开发者,都面临着高昂的成本和技术门槛。然而,这一局面可能即将被打破。 由...新技术# HIGGS# 大语言模型10个月前02700
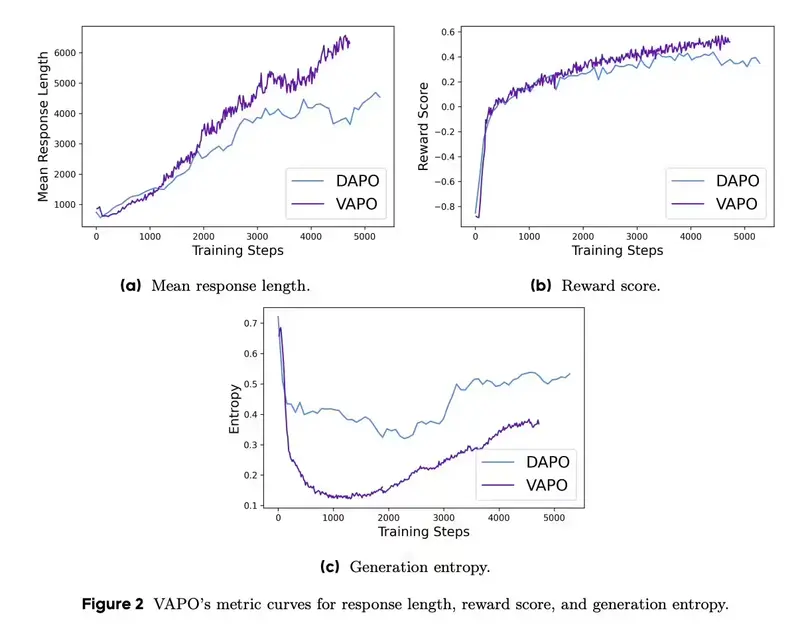
字节跳动推出VAPO框架:让大语言模型在复杂推理任务中更高效字节跳动Seed研究团队发布了一项名为 VAPO 的强化学习训练框架。这一框架专为提升大语言模型(LLM)在复杂、冗长任务中的推理能力而设计,特别是在数学推理和长链推理(Long Chain-of-T...新技术# VAPO# 大语言模型# 字节跳动10个月前04800
Allen人工智能研究所推出OLMoTrace:让大语言模型透明化,追溯AI决策的真实来源在企业AI应用中,大语言模型(LLM)的“黑盒”特性一直是阻碍其大规模采用的主要障碍之一。如何理解模型输出的来源、提升透明度并增强信任,成为行业亟需解决的问题。本周,Allen人工智能研究所(Ai2...新技术# Ai2# OLMoTrace# 大语言模型10个月前03410
TTT-Video:通过引入 Test-Time Training(TTT)层,成功让DiT 模型能够从文本故事板生成长达一分钟的视频英伟达联合斯坦福大学、加州大学圣地亚哥分校、加州大学伯克利分校和德克萨斯大学奥斯汀分校的研究人员,通过引入 Test-Time Training(TTT)层,成功让预训练的 DiT 模型能够从文本故事...新技术# CogVideoX-5B# DiT 模型# TTT-Video10个月前05370
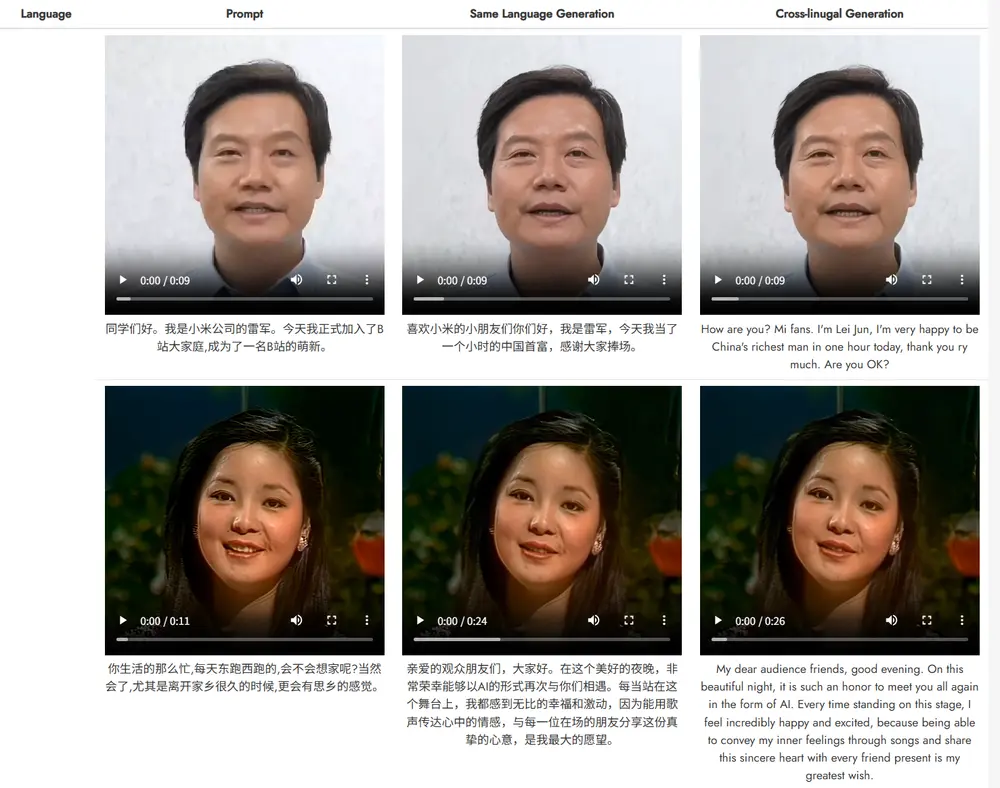
新型实时文本驱动的说话头像生成框架OmniTalker :在零样本场景下同时生成同步的语音和说话头像视频,同时保留语音风格和面部风格阿里通义实验室推出新型实时文本驱动的说话头像生成框架OmniTalker ,能够在零样本(zero-shot)场景下同时生成同步的语音和说话头像视频,同时保留语音风格和面部风格。OmniTalker ...新技术# OmniTalker# 通义实验室10个月前05390