后训练压缩策略DiTFastAttn:压缩和加速DiT模型,缓解DiT的计算瓶颈问题来自清华大学、无问芯穹(Infinigence AI)、卡内基梅隆大学和上海交通大学的研究人员推出新技术DiTFastAttn,它专门用于压缩和加速一种称为Diffusion Transformers...新技术# DiTFastAttn# DiT模型2年前01,0250
新型多模态DiT模型AV-DiT:生成既有视觉画面又有声音的高质量视频来自多伦多大学、德克萨斯大学达拉斯分校和Adobe研究中心的研究人员推出新型多模态扩散变换器AV-DiT(Audio-Visual Diffusion Transformer),它专门设计用于联合生成...新技术# AV-DiT# DiT模型2年前06760
Fal.ai平台推出新DiT模型AuraFlow:支持文字,百分百开源Stability AI因为Stable Diffusion 3 Medium模型的许可证问题备受诟病,虽然后来更改了许可证,但此模型在人物尤其是躺倒后人物的糟糕表现还是不受开源社区待见。不少人开始转...图像模型# AuraFlow# DiT模型# Fal.ai1年前06450
用于加速DiT模型的训练和推理过程的方法HarmoniCa商汤科技研究院、北京航空航天大学、莫纳什大学和香港科技大学推出一种用于加速DiT模型的训练和推理过程的方法HarmoniCa,通过基于Step-Wise去噪训练(SDT)和图像错误代理引导目标(IEP...新技术# DiT模型# HarmoniCa2年前05430
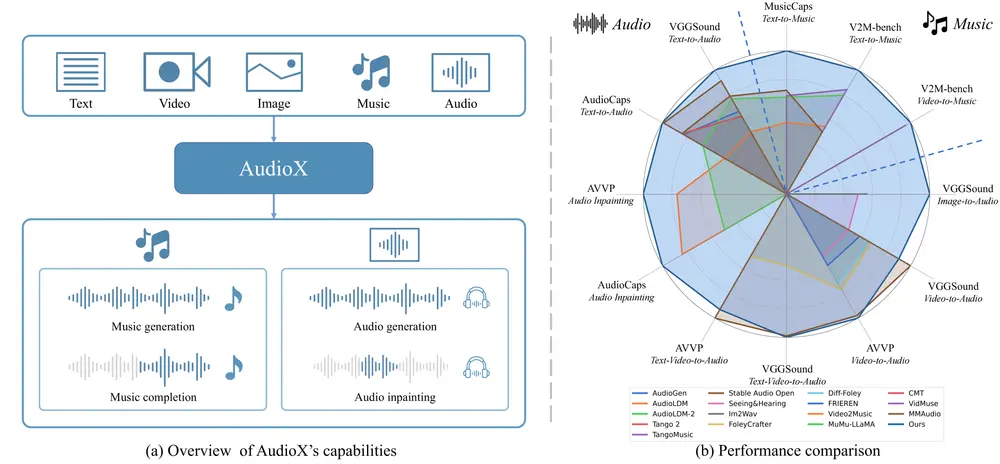
香港科技大学推出统一DiT架构模型AudioX:通过多模态输入(如文本、视频、图像、音乐和音频)生成高质量的音频和音乐香港科技大学的研究人员推出统一DiT架构模型AudioX,通过多模态输入(如文本、视频、图像、音乐和音频)生成高质量的音频和音乐。AudioX通过创新的多模态掩码训练策略,强制模型从掩码输入中学习,从...语音模型# AI音乐# AudioX# DiT模型1年前04970
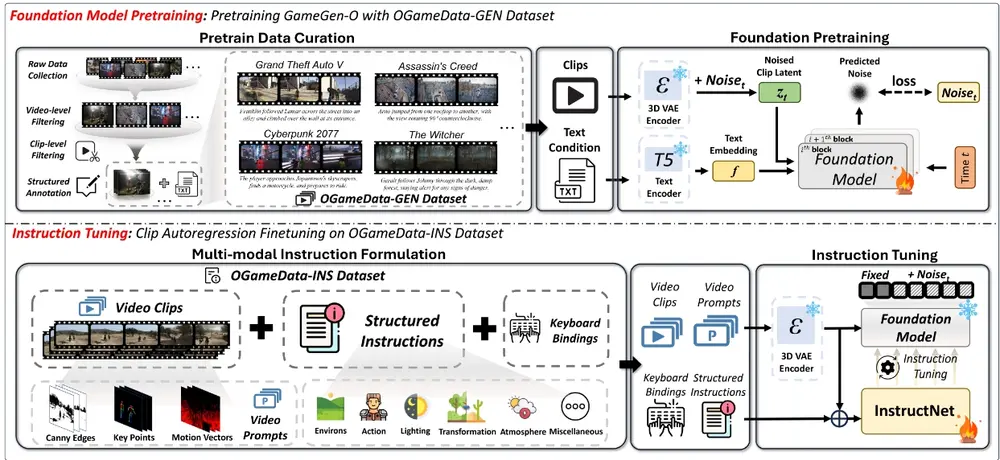
腾讯推出专为生成开放世界游戏量身定制的DiT模型GameGen-O:通过模拟各种游戏引擎特性,如创新角色、动态环境、复杂动作和多样事件,促进了高质量、开放领域的生成香港科技大学、中国科学技术大学和腾讯光子工作室的研究人员推出一个专为生成开放世界游戏量身定制的DiT模型GameGen-O,该模型通过模拟各种游戏引擎特性,如创新角色、动态环境、复杂动作和多样事件,促...视频模型# DiT模型# GameGen-O# 开放世界游戏1年前04630
Chipmunk:无需训练的动态稀疏性加速DiT模型的推理过程扩散模型(Diffusion Models)近年来在图像生成和视频生成领域表现出色,但其计算复杂度也成为了性能瓶颈。特别是基于DiT架构的模型,如FLUX、HunyuanVideo 等,其注意力层和多...新技术# Chipmunk# DiT模型# FLUX11个月前04490
专为DiT架构模型设计的运动转移方法DiTFlow牛津大学、Snap和MBZUAI的研究人员介绍了一种名为DiTFlow的方法,它是一种专为DiT架构模型设计的运动转移方法。DiTFlow通过分析参考视频,提取出一种名为注意力运动流(Attentio...新技术# DiTFlow# DiT模型1年前03890
基于DiT模型的多领域程序化序列生成框架MakeAnything:根据文本描述或图像生成分步骤的教程新加坡国立大学的研究团队推出 MakeAnything,这是一个基于DiT模型的多领域程序化序列生成框架,能够根据文本描述或图像生成分步骤的教程,也就是生成一致性图片序列。 GitHub:https...图像模型# DiT模型# MakeAnything1年前02940
针对DiT模型的深度修剪方法TinyFusion:通过端到端学习去除冗余层,以减少模型的参数量和提高推理效率新加坡国立大学的研究人员推出一个针对DiT模型的深度修剪方法TinyFusion,旨在通过端到端学习去除冗余层,以减少模型的参数量和提高推理效率。DiT架构在图像生成领域展现出了卓越的能力,但通常伴随...新技术# DiT模型# TinyFusion1年前02850
字节跳动推出基于DiT模型的人类图像动画框架DreamActor-M1:实现整体性、表现力和鲁棒性的人类图像动画生成字节跳动推出一个基于DiT模型的人类图像动画框架DreamActor-M1,实现整体性(holistic)、表现力(expressive)和鲁棒性(robust)的人类图像动画生成。该框架通过混合引导...新技术# DiT模型# DreamActor-M1# 字节跳动1年前02840