高效灵活的对象检测工具YOLO-World来自腾讯AI实验室、华中科技大学EIC学院的研究人员推出高效实时开放词汇对象检测框架YOLO-World,旨在通过视觉语言模型和大规模数据集的预训练,增强YOLO(You Only Look Once...新技术# YOLO-World# 对象检测工具# 腾讯AI实验室2年前01,0530
视觉语言模型CoLLaVO:提高视觉语言模型在零样本视觉语言任务中的性能韩国研究人员推出视觉语言模型CoLLaVO(Crayon Large Language and Vision mOdel),此模型旨在通过增强对象级别的图像理解能力,提高视觉语言模型(VLMs)在零样...新技术# CoLLaVO# 视觉语言模型2年前01,0260
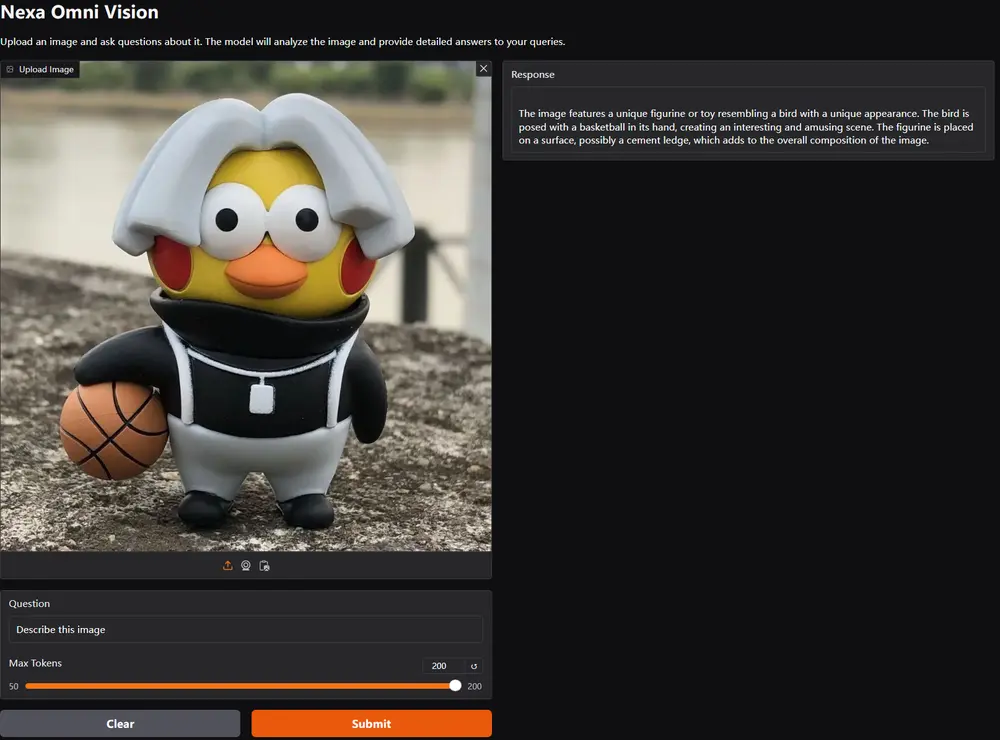
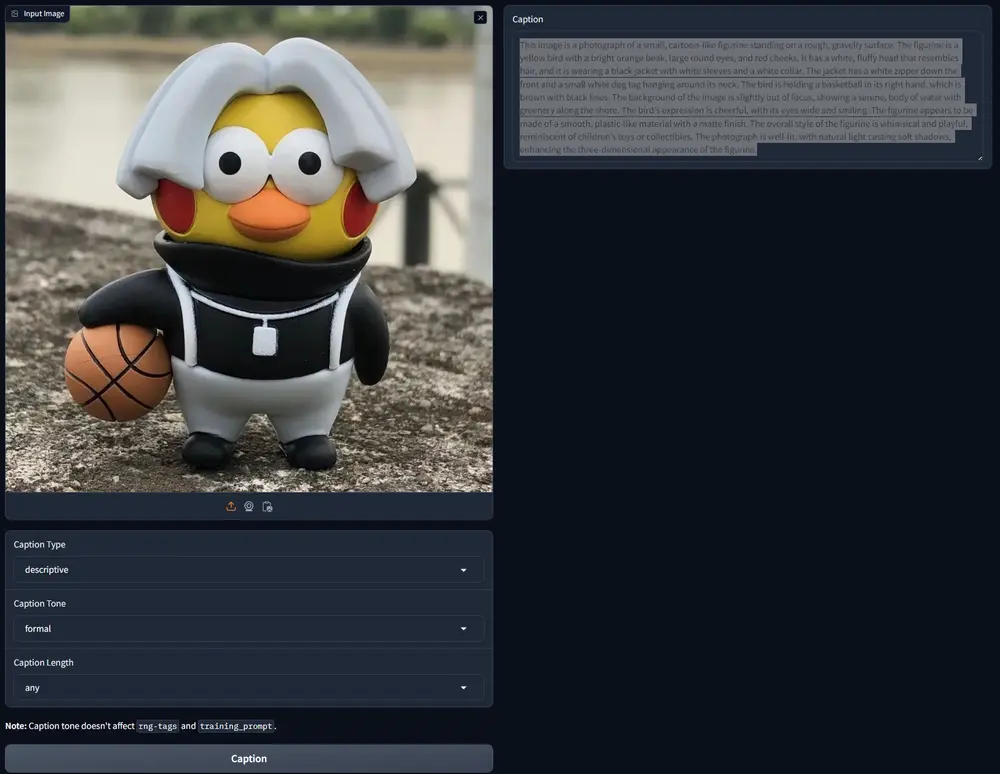
Nexa AI 推出迷你视觉语言模型 OmniVision-968MNexa AI 最新发布了 OmniVision-968M,这是一款专为边缘设备设计的视觉语言模型,它通过技术创新,将图像标记数量大幅减少,显著降低了延迟和计算负担,还提升了处理速度,为边缘计算领域带...多模态模型# Nexa AI# OmniVision-968M# 视觉语言模型1年前07520
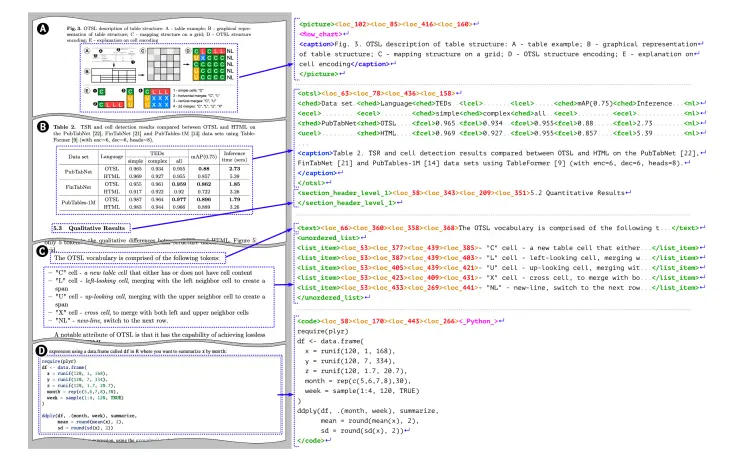
视觉语言模型SmolDocling:以高效的方式实现端到端的多模态文档转换在数字化时代,文档处理和理解是许多行业和研究领域的核心需求。从学术论文到商业报告,从技术手册到专利文件,文档的高效转换和理解对于信息提取、知识管理和自动化流程至关重要。然而,传统的文档处理方法往往依赖...多模态模型# SmolDocling# 文档转换# 视觉语言模型1年前05840
新型指令式图像编辑框架FireEdit:利用区域感知的视觉语言模型(VLM),实现了对用户指令的细粒度理解和精确图像编辑中山大学深圳校区、腾讯混元、清华大学和香港科技大学的研究人员推出新型指令式图像编辑框架FireEdit,它通过利用区域感知的视觉语言模型(VLM),实现了对用户指令的细粒度理解和精确图像编辑。Fire...新技术# FireEdit# 图像编辑# 视觉语言模型12个月前05570
JoyCaption:从零开始构建的免费、开放且未经审查的视觉语言模型JoyCaption,一个从零开始构建的免费、开放且未经审查的视觉语言模型(VLM),旨在助力社区训练SD或Flux模型。它不仅免费开放,还提供训练脚本和丰富的构建细节,就像bigASP一样。 Dem...多模态模型# JoyCaption# 视觉语言模型1年前05460
视觉语言模型ClipTagger-12B:开源视频理解新标杆,性能对标 GPT-4.1,成本低至 1/15程序化视频理解正在成为构建智能视觉系统的基础设施。从内容审核到自动化标注,从辅助功能到视频搜索引擎,开发者需要一种高效、可靠的方式,将原始视频帧转化为结构化、可搜索、可操作的数据。 为此,Infere...多模态模型# ClipTagger-12B# 视觉语言模型8个月前05130
MiniMax推出视觉三重统一强化学习(RL)系统 V-Triune :使视觉语言模型能够在单一训练流程中联合学习视觉推理和感知任务MiniMax推出视觉三重统一强化学习(RL)系统 V-Triune ,使视觉语言模型能够在单一训练流程中联合学习视觉推理和感知任务。该系统通过整合三个互补组件——样本级数据格式化(Sample-Le...多模态模型# MiniMax# V-Triune# 视觉语言模型10个月前05050
阿里通义实验室发布 Qwen3-VL:迄今最强视觉语言模型,全面开源阿里通义实验室 Qwen 项目组正式推出全新升级的 Qwen3-VL 系列——这是截至目前 Qwen 多模态体系中能力最全面、性能最先进的视觉语言模型(Vision-Language Model, V...多模态模型# Qwen3-VL# 视觉语言模型6个月前04370
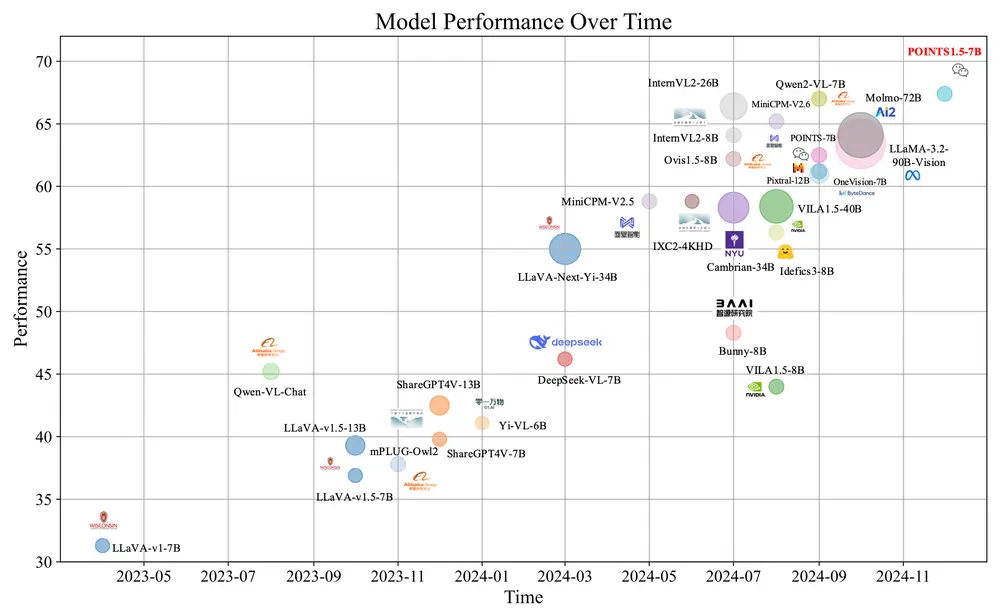
微信 AI 模式识别中心推出视觉语言模型POINTS1.5系列:提升对真实世界应用的处理能力微信 AI 模式识别中心推出视觉语言模型POINTS1.5系列,旨在提升对真实世界应用的处理能力。POINTS1.5是POINTS1.0的增强版本,它通过引入几项关键创新,改进了模型在处理高分辨率图像...多模态模型# POINTS1.5# 视觉语言模型1年前03640
开源视觉语言模型Moondream:将强大的图像理解能力与极小的资源占用完美结合Moondream 是一款高效的开源视觉语言模型(VLM),它将强大的图像理解能力与极小的资源占用完美结合。这款模型设计初衷是为各种设备和平台提供多功能且易于访问的人工智能解决方案。 官网:https...多模态模型# Moondream# 视觉语言模型1年前03370
跨模态图像生成模型Qwen2vl-Flux:将Qwen2VL的视觉语言理解能力与FLUX框架相结合,实现了更精确和上下文感知的图像生成Qwen2vl-Flux 是一种先进的跨模态图像生成模型,它将Qwen2VL的视觉语言理解能力与FLUX框架相结合,实现了更精确和上下文感知的图像生成。该模型在文本提示和视觉参考的基础上生成高质量图像...图像模型# Qwen2vl-Flux# 视觉语言模型1年前03370