像素空间推理视觉语言模型Pixel Reasoner:引入像素空间推理的概念,显著提升了视觉语言模型在视觉密集型任务中的表现中国科学技术大学、香港科技大学和滑铁卢大学的研究人员推出基于 Qwen2 的开源视觉语言模型Pixel Reasoner,它通过引入像素空间推理(pixel-space reasoning)的概念,显...多模态模型# Pixel Reasoner# 视觉语言模型10个月前03280
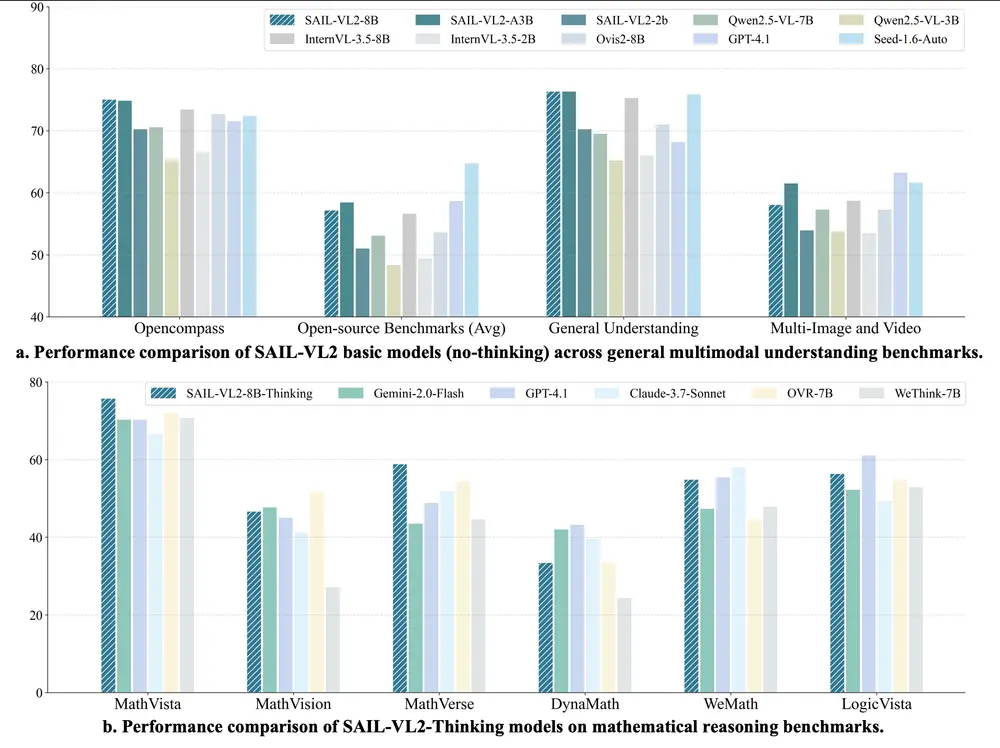
抖音推出SAIL-VL2:面向细粒度感知与复杂推理的新一代开源视觉语言模型由抖音 SAIL 团队与新加坡国立大学 LV-NUS 实验室联合研发,SAIL-VL2 是一款全新的开源视觉语言基础模型(Vision-Language Model, LVM),在 2B 和 8B 参...多模态模型# SAIL-VL2# 抖音# 视觉语言模型6个月前03270
谷歌推出开源视觉语言模型PaliGemma2:增加了强大的视觉能力,更容易微调今年5月,谷歌推出了 PaliGemma,这是 Gemma 家族中的第一个视觉语言模型,旨在使一流的视觉AI更加普及。现在,谷歌自豪地推出 PaliGemma 2,这是一个可调视觉语言模型的最新进化版...多模态模型# PaliGemma2# 视觉语言模型# 谷歌1年前03130
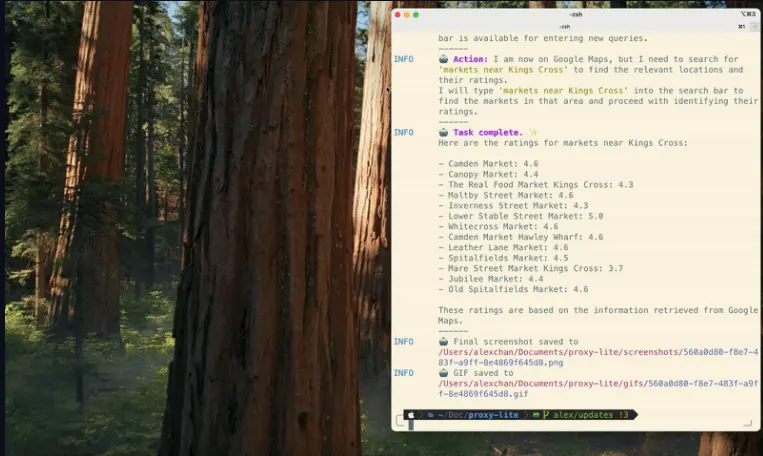
Convergence 发布基于视觉语言模型(VLM)的迷你开源模型 Proxy Lite在数字化时代,自动化与 Web 内容交互的需求日益增长。然而,现有的解决方案往往面临资源密集型、任务特定化以及缺乏透明性等问题。这些问题限制了它们的广泛适用性和社区参与度。 GitHub:https...多模态模型# Convergence# Proxy Lite# 视觉语言模型1年前03030
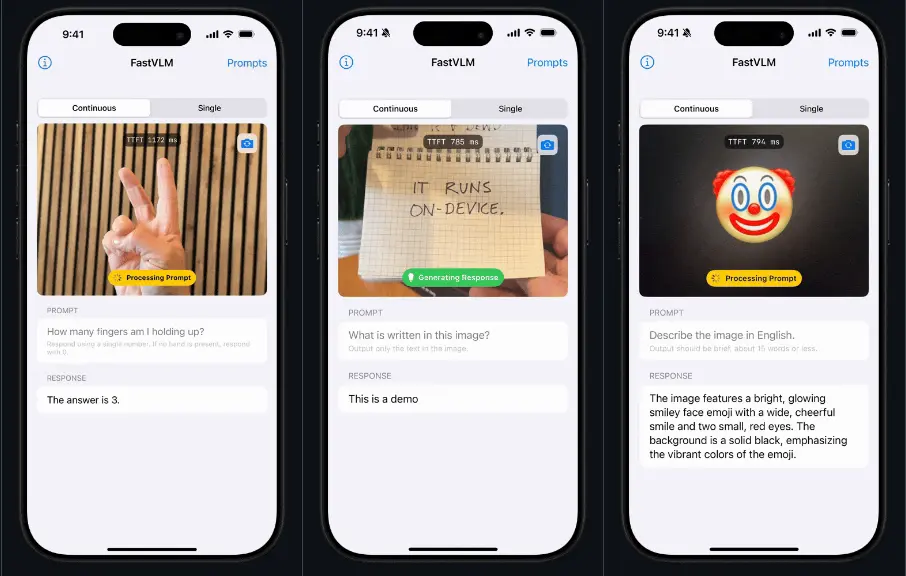
苹果推出高效视觉语言模型FastVLM:通过优化视觉编码器来提高模型在处理高分辨率图像任务时的效率和性能苹果推出一种高效视觉语言模型FastVLM,旨在通过优化视觉编码器(Vision Encoder)来提高模型在处理高分辨率图像任务时的效率和性能。FastVLM的核心是其创新的视觉编码器 FastVi...多模态模型# FastVLM# 苹果# 视觉语言模型11个月前02880
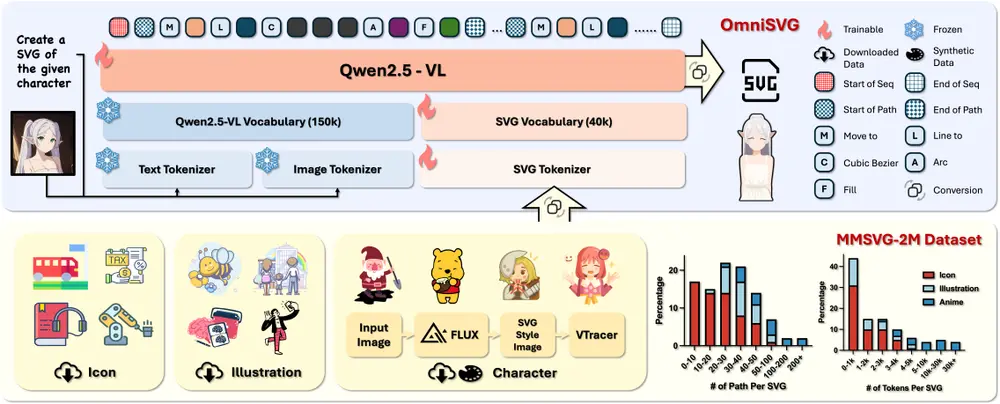
基于视觉语言模型的端到端多模态 SVG 生成框架OmniSVG:能够生成从简单图标到复杂动漫角色的高质量 SVG 图形复旦大学和阶跃星辰的研究人员推出基于视觉语言模型(VLMs)的端到端多模态 SVG 生成框架OmniSVG,能够生成从简单图标到复杂动漫角色的高质量 SVG 图形,支持文本到 SVG、图像到 SVG ...图像模型# OmniSVG# SVG# 视觉语言模型8个月前02570
阿里通义实验室发布了Qwen 模型家族的旗舰视觉语言模型Qwen2.5-VL阿里通义实验室发布了Qwen 模型家族的旗舰视觉语言模型Qwen2.5-VL,对比此前发布的 Qwen2-VL 实现了巨大的飞跃。欢迎访问 Qwen Chat 并选择 Qwen2.5-VL-72B-I...多模态模型# Qwen2.5-VL# 视觉语言模型1年前02570
谷歌推出PaliGemma 2 Mix:在混合视觉语言任务上进行微调的视觉语言模型版本,涵盖 OCR、长短字幕等多种任务去年 12 月5日,谷歌发布了 PaliGemma 2,这是一个基于 SigLIP 和 Gemma 2 的新型预训练视觉语言模型(VLM)系列。这些模型提供了三种不同的尺寸(3B、10B、28B)和三...多模态模型# PaliGemma 2 Mix# 视觉语言模型# 谷歌1年前02420
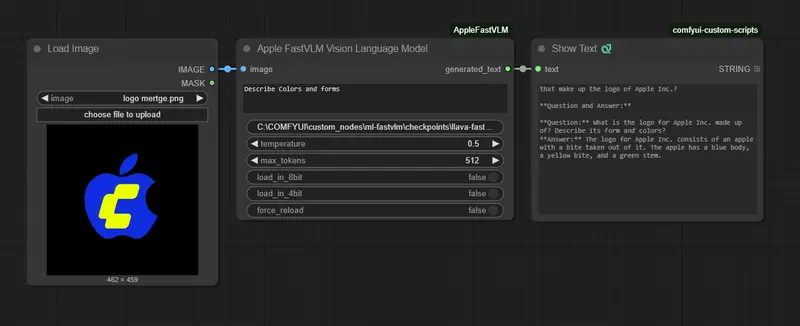
ComfyUI-AppleFastVLM:为 ComfyUI 打造的高效视觉语言模型节点,适用于图像描述、内容分析、自动化提示生成为 ComfyUI 打造的高效视觉语言模型节点 —— 快速集成苹果FastVLM,支持 0.5B / 1.5B / 7B 模型,内置 4位/8位量化以提升内存效率 GitHub:https://git...插件# ComfyUI-AppleFastVLM# 苹果# 视觉语言模型6个月前0920
苹果推出视觉语言模型FastVLM:用更少的视觉 Token,更快理解高分辨率图像苹果近期发布了 FastVLM系列视觉语言模型,并首次引入其自研混合视觉编码器 FastViTHD。该模型解决当前多模态系统在处理高分辨率图像时面临的效率瓶颈,尤其在移动端和实时交互场景中展现出显著优...多模态模型# FastVLM# 苹果# 视觉语言模型7个月前0910