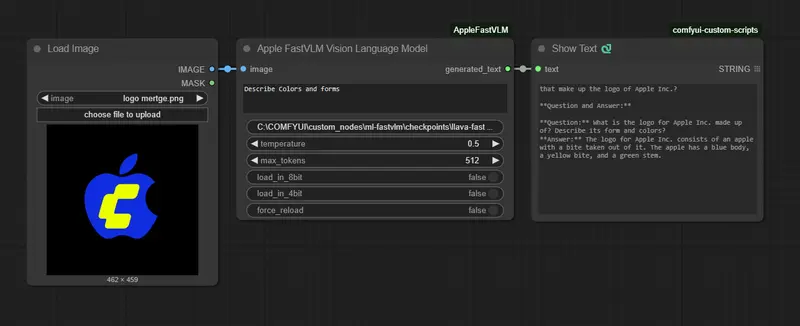
为 ComfyUI 打造的高效视觉语言模型节点 —— 快速集成苹果FastVLM,支持 0.5B / 1.5B / 7B 模型,内置 4位/8位量化以提升内存效率
本项目将 苹果FastVLM 高效集成至 ComfyUI 工作流系统,提供极致推理速度和低显存占用的多模态体验。适用于图像描述、内容分析、自动化提示生成等场景。
核心特性
| 特性 | 说明 |
|---|---|
| ⚡ 极致首词元延迟 | 相比 LLaVA-OneVision,首词元生成速度快达 85倍 |
| 🎯 多规模模型支持 | 支持 0.5B(轻量)、1.5B(均衡)和 7B(高精度)三种参数版本 |
| 💾 显存优化设计 | 支持 4位 和 8位 量化,显著降低显存需求 |
| 🔁 智能缓存机制 | 自动缓存已加载模型,避免重复加载开销 |
| 🧩 原生 ComfyUI 节点 | 可视化拖拽使用,无缝融入现有工作流 |
系统要求
运行环境
| 组件 | 要求 |
|---|---|
| Python | 3.10 或更高版本 |
| GPU | 推荐 NVIDIA 显卡并安装 CUDA 驱动(支持 cuBLAS) |
| ComfyUI | 最新主干版本(建议每日构建版) |
⚠️ 注意:目前暂不支持 Apple Silicon(M系列芯片)原生运行。
模型资源需求
| 模型 | 显存 (VRAM) | 系统内存 (RAM) | 性能定位 |
|---|---|---|---|
| FastVLM-0.5B | ≥4 GB | ≥8 GB | ⚡ 最快速度,适合实时响应 |
| FastVLM-1.5B | ≥8 GB | ≥16 GB | ⚖️ 速度与质量平衡 |
| FastVLM-7B | ≥16 GB | ≥24 GB | 🎯 最佳准确性,细节丰富 |
📌 提示:通过启用 4位量化(load_in_4bit=True),7B 模型可在 8GB 显存设备上运行,但推理速度略有下降。
安装指南
1. 克隆节点到自定义目录
cd ComfyUI/custom_nodes
git clone https://github.com/yourusername/ComfyUI-AppleFastVLM.git
2. 安装核心依赖
cd ComfyUI-AppleFastVLM
pip install -r requirements.txt
❗ 若
bitsandbytes安装失败(常见于 Windows),可暂时禁用量化功能:在节点配置中设置:
load_in_4bit = False load_in_8bit = False
3. 安装 Apple FastVLM 库
cd ..
git clone https://github.com/apple/ml-fastvlm.git
cd ml-fastvlm
pip install -e .
下载与部署模型
创建检查点目录
在 ml-fastvlm 根目录下创建:
mkdir -p checkpoints/
并将下载的权重解压至对应文件夹:
checkpoints/
├── llava-fastvithd_0.5b_stage3/
├── llava-fastvithd_1.5b_stage3/
└── llava-fastvithd_7b_stage3/
模型下载链接(官方发布)
| 模型 | 描述 | 下载地址 |
|---|---|---|
| FastVLM-0.5B | 轻量级,推理最快 | Download v0.5b |
| FastVLM-1.5B | 平衡性能与准确率 | Download v1.5b |
| FastVLM-7B | 高精度,适合复杂理解任务 | Download v7b |
✅ 解压后请确认包含以下关键文件:
config.jsonpytorch_model.bin或分片.safetensorstokenizer.model
使用方法
在 ComfyUI 中添加节点
- 右键点击画布 → “添加节点”
- 导航路径:
AppleVLM→FastVLM - 将图像输出连接至
image输入端口 - 设置提示词(prompt)与其他参数
- 执行工作流
节点参数说明
必填输入
| 参数 | 说明 | 默认值 | 类型 |
|---|---|---|---|
image | 输入图像(来自 LoadImage 或其他图像源) | - | Image Tensor |
prompt | 文本指令,用于引导模型行为 | "详细描述此图像" | str |
model_path | 模型所在路径 | custom_nodes/ml-fastvlm/checkpoints/llava-fastvithd_0.5b_stage3 | str |
temperature | 输出随机性控制 | 0.7 | float (0.0–2.0) |
max_tokens | 最大响应长度 | 256 | int (1–2048) |
可选配置
| 参数 | 说明 | 默认值 |
|---|---|---|
load_in_8bit | 启用 8-bit 量化以节省显存 | False |
load_in_4bit | 启用 4-bit 量化(更低显存,略慢) | False |
force_reload | 强制重新加载模型(调试用) | False |
温度(Temperature)调节指南
| 区间 | 行为特征 | 推荐用途 |
|---|---|---|
0.0 – 0.3 | 输出高度确定,事实性强 | 图像标注、文档摘要 |
0.4 – 0.7 | 创造性与准确性平衡 | 提示词生成、通用问答 |
0.8 – 1.0 | 更多样、更具想象力 | 故事创作、艺术灵感 |
>1.0 | 极具发散性,可能偏离主题 | 实验性探索 |
常见问题与解决方案
CUDA Out of Memory(显存不足)
症状:
RuntimeError: CUDA out of memory.
解决方式:
# 方法一:启用 4-bit 量化
load_in_4bit: True
# 方法二:切换为更小模型
model_path: checkpoints/llava-fastvithd_0.5b_stage3
# 方法三:减少输出长度
max_tokens: 128
❌ 模型无法加载
排查清单:
- ✅ 检查
model_path是否指向正确的未压缩文件夹; - ✅ 确认模型文件已完整解压(非
.zip或.tar.gz压缩状态); - ✅ 运行验证命令测试环境是否就绪:
python -c "from llava.model.builder import load_pretrained_model; print('✅ FastVLM 安装成功')"
- ✅ 确保
ml-fastvlm已通过pip install -e .正确安装。
输出质量差或不相关
尝试以下优化策略:
- 🔍 使用更大模型(如从 0.5B 升级到 7B);
- 🎯 提供更具体的 prompt,例如:
“请描述图中人物的动作、服装风格及背景环境”;
- 🖼️ 确保输入图像清晰、焦点明确;
- 🔧 调整
temperature至0.2~0.5获取更稳定结果; - 📢 查看终端日志,确认无模型加载警告或 tokenizer 错误。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











