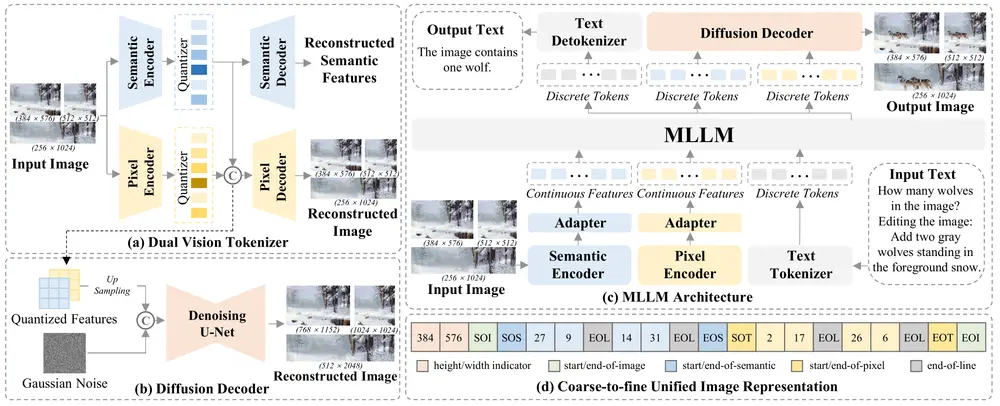
增强版多模态大语言模型ILLUME+ :通过双视觉标记化和扩散解码器来提升深度语义理解和高保真图像生成的能力近年来,多模态大语言模型(MLLMs)在图像理解、生成和编辑任务中取得了显著进展。然而,现有的统一模型在同时处理这三种任务时面临挑战。例如,早期的模型(如 Chameleon 和 EMU3)使用 VQ...多模态模型# ILLUME# 图像生成# 多模态大语言模型1年前05700
新型图像生成技术MaskBit:根据一些简单的描述或者标签,自动创造出相对应的图像字节跳动、慕尼黑工业大学、MCML和卡内基梅隆大学的研究人员推出新型图像生成技术MaskBit,这个技术能够自动创造出新的图像,而且不需要像传统方法那样依赖于大量的预训练数据或者复杂的数学模型。Mas...新技术# MaskBit# 图像生成2年前05620
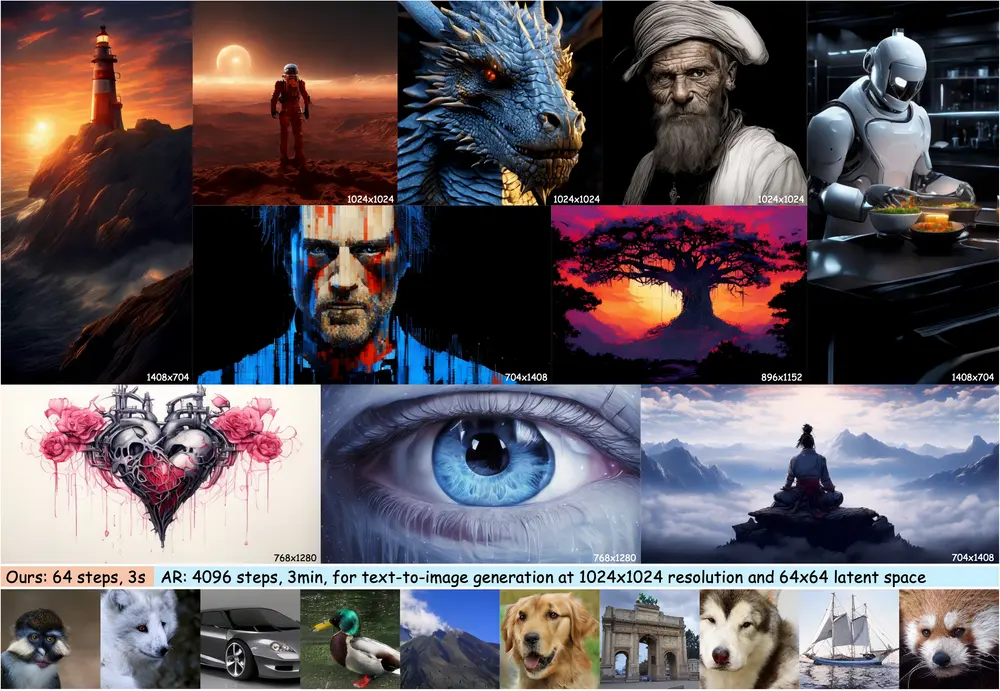
阶跃星辰发布 NextStep-1:140 亿参数自回归模型,用“连续令牌”重塑图像生成在图像生成领域,自回归模型长期被视作“文本专家,视觉弱项”——它们擅长逐词生成语言,却难以像扩散模型那样精细构建图像。而如今,阶跃星辰(StepFun)正试图打破这一边界。 GitHub:https...图像模型# NextStep-1# 图像生成# 图像编辑8个月前05350
新型端到端模型DnD-Transformer:提高了图像生成任务的质量和效率,为图像生成领域带来了新的可能北京大学、阿里巴巴集团、威斯康星大学麦迪逊分校和北京理工大学的研究人员推出新型端到端模型DnD-Transformer,这是一种用于高效细粒度图像生成的二维自回归Transformer。简单来说,这个...新技术# DnD-Transformer# 图像生成1年前04870
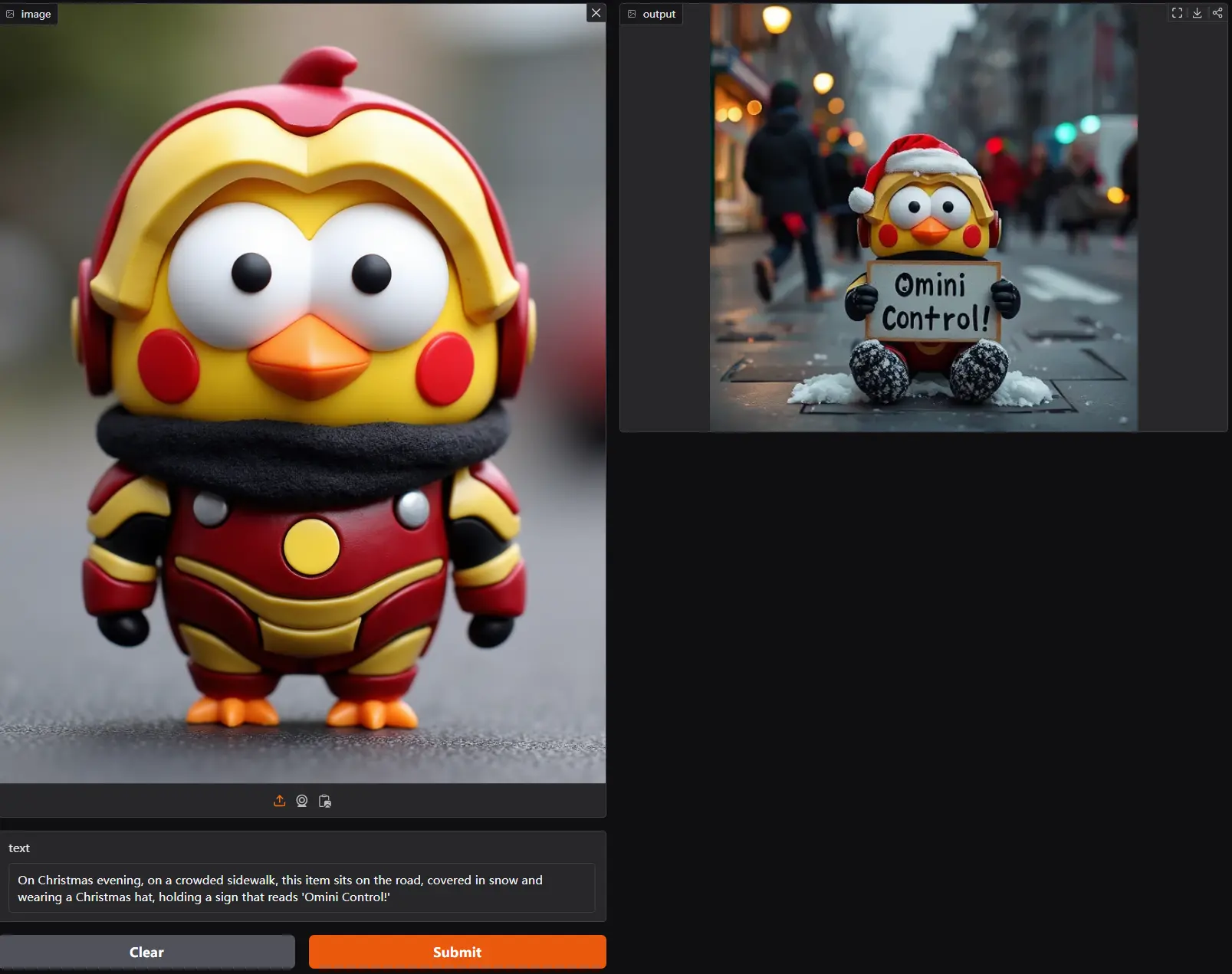
适用于FLUX模型的新型框架OminiControl:通过整合图像条件,使得DiT模型能够处理各种图像生成任务新加坡国立大学的研究团队提出了一种名为OminiControl的新型框架,它旨在为预训练的DiT模型(FLUX模型)提供最小化和通用的控制。OminiControl通过整合图像条件,使得DiT模型能够...Flux衍生# FLUX模型# OminiControl# 图像生成1年前04700
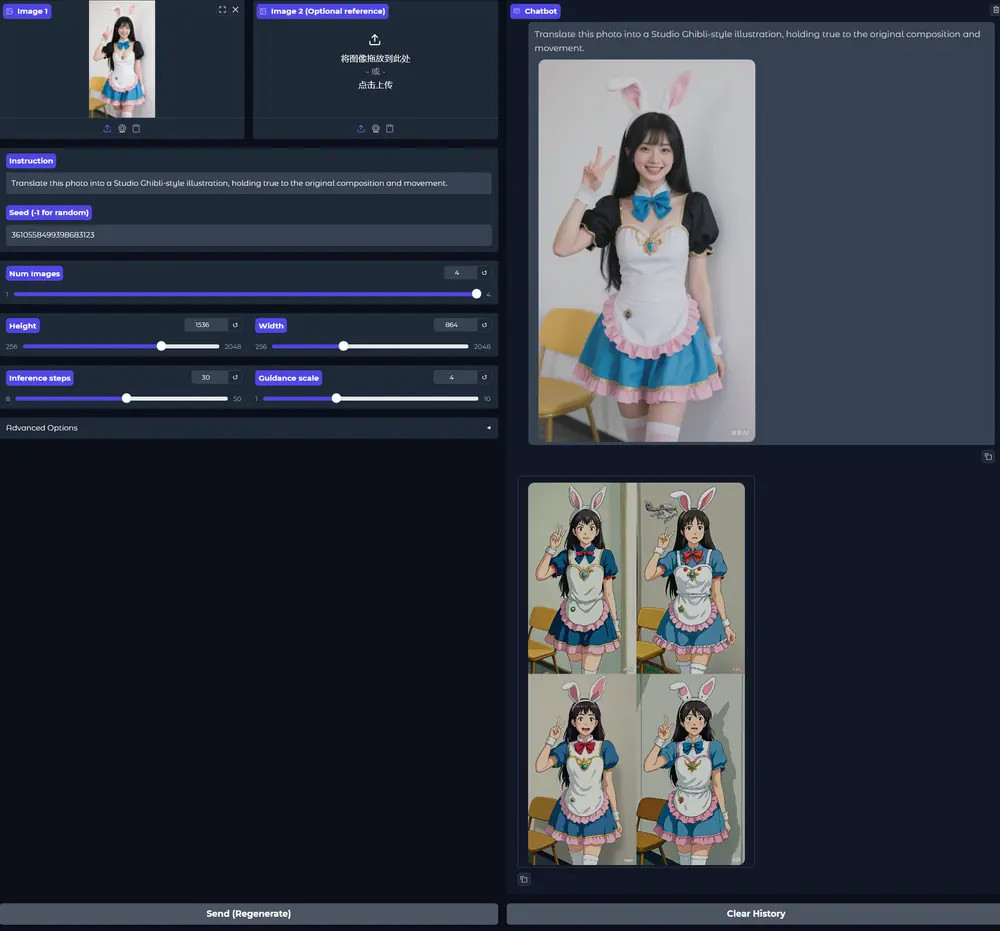
统一视觉理解与生成框架UniWorld:支持 20+语义图片编辑任务北京大学深圳研究生院、鹏城实验室、兔展AI的研究人员推出统一视觉理解与生成框架UniWorld,它基于强大的视觉-语言模型和对比语义编码器,能够同时处理图像感知和图像操控任务。 GitHub:http...图像模型# UniWorld# 图像生成# 图像编辑10个月前04580
基于常加速度方程的普通微分方程(ODE)框架CAF:用于学习两个分布之间的映射,特别是在图像生成领域高丽大学和韩国科学技术研究院的研究人员推出新型框架Constant Acceleration Flow(CAF),它是一种基于常加速度方程的普通微分方程(ODE)框架,用于学习两个分布之间的映射,特别...新技术# CAF# 图像生成1年前04510
新型图像生成技术“集合自回归模型”(SAR):通过改变图像生成的顺序和方式,使得生成图像的速度和灵活性都得到了极大的提升香港中文大学MMLab 、上海人工智能实验室和南京大学的研究人员推出一种新的图像生成技术“集合自回归模型”(Set AutoRegressive Modeling,简称SAR)。你可以把它想象成一个超...新技术# SAR# 图像生成# 集合自回归模型1年前04280
谷歌提升Gemini 2.0 Flash图像生成和编辑功能的能力基于开发者的热情反馈,谷歌激动地宣布,图像生成功能现已通过Gemini 2.0 Flash预览版推出。 开发者即日起可通过Google AI Studio和Vertex AI中的Gemini API...早报# Gemini 2.0 Flash# 图像生成# 谷歌11个月前04060
FireFlow:用于快速反转和编辑图像语义内容,提高图像生成和编辑的效率和准确性尽管带有蒸馏的校正流(ReFlows)为快速采样提供了一种有前景的方法,但其快速反演过程——即将图像转换回结构化噪声以进行恢复和后续编辑——仍然面临挑战。具体来说,传统的ReFlow方法在反演过程中可...新技术# FireFlow# 图像生成1年前04020
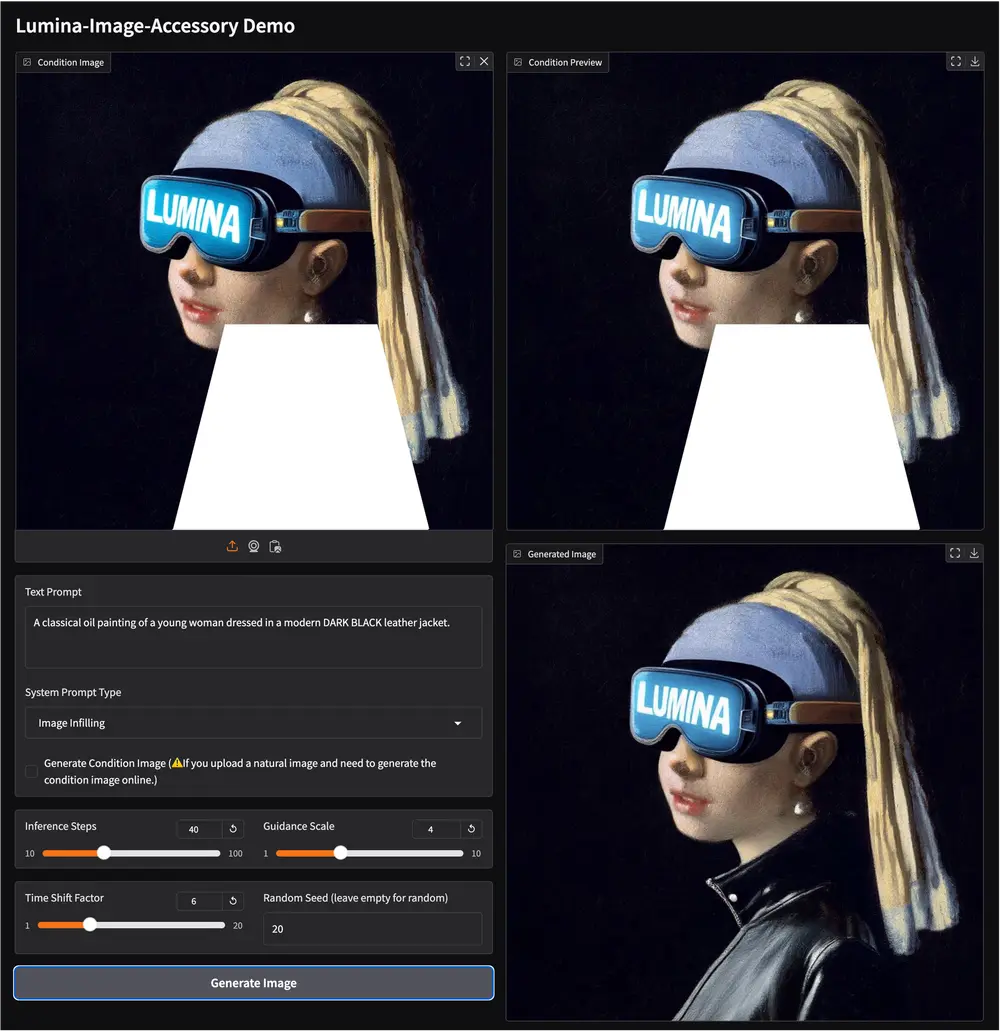
Lumina-Accessory:专为 Lumina 系列模型设计的多任务指令微调框架Lumina-Accessory 是一个专为 Lumina 系列模型设计的多任务指令微调框架,目前支持 Lumina-Image-2.0。该框架通过一系列创新设计,为图像生成和编辑任务提供了强大的支持...图像模型# Lumina-Accessory# Lumina-Image 2.0# 图像生成11个月前03960
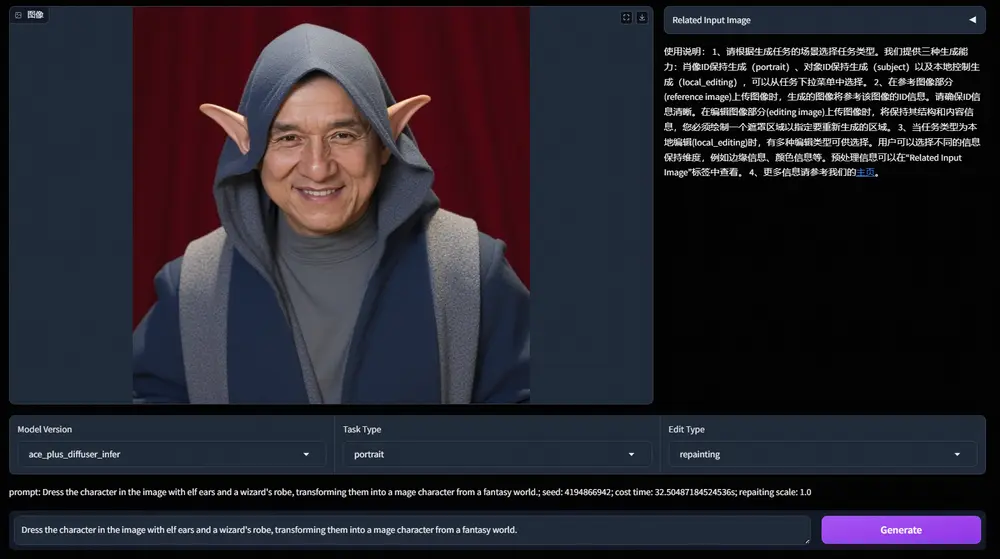
通义实验室推出基于指令的图像生成和编辑框架ACE++:基于FLUX.1-dev模型,实现多种图像生成和编辑任务阿里巴巴通义实验室推出基于指令的图像生成和编辑框架ACE++,这是之前介绍过的新型多模态生成模型ACE升级版,ACE++ 通过改进的长上下文条件单元(LCU++)和两阶段训练方案,能够高效地利用预训练...图像模型# ACE# FLUX.1-dev# 图像生成1年前03520