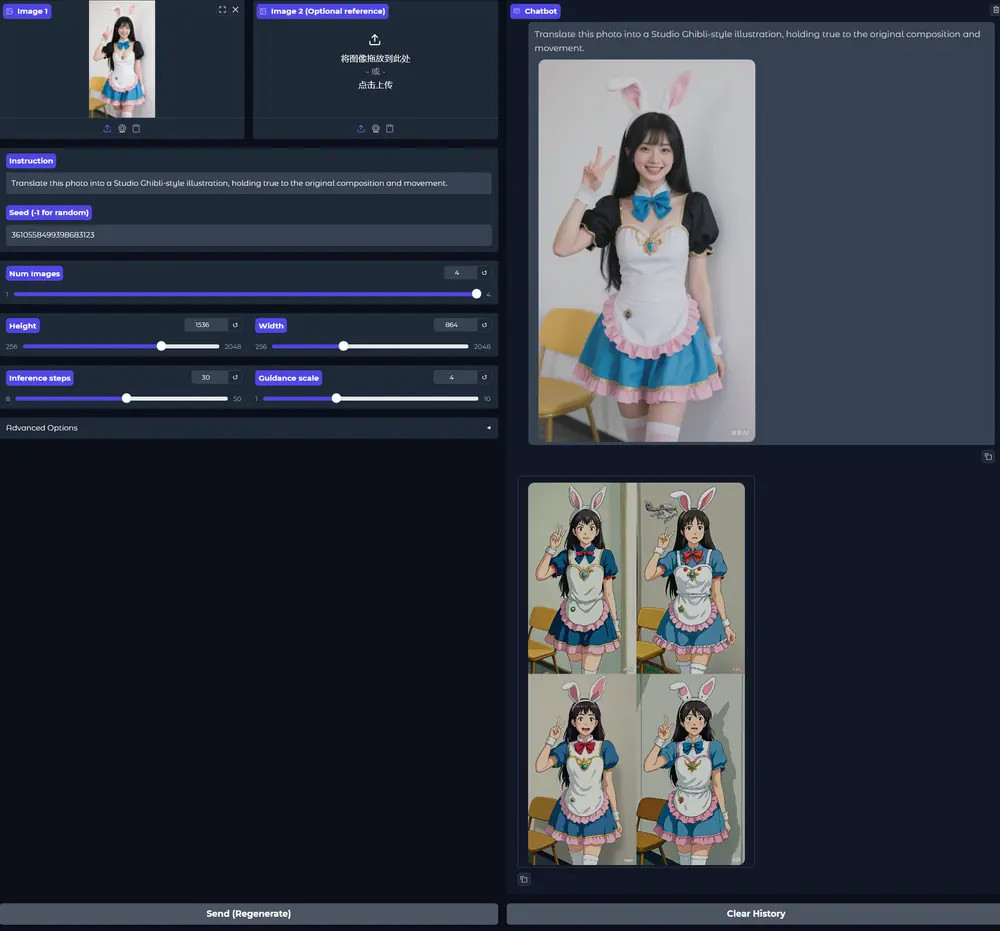
Ollama 新增图像生成功能!macOS 率先体验,双模型(Z-Image Turbo 与 FLUX.2 Klein)支持中英文本渲染 + 高精度创作Ollama 正式上线图像生成实验性功能,目前已在 macOS 系统开放使用,Windows 和 Linux 版本也即将推出。该功能无需复杂配置,仅需一行终端命令就能调用文生图模型生成图像,支持直接在...工具# LUX.2 Klein# Ollama# Z-Image-Turbo2个月前0560
DreamOmni2:支持图文指令的统一图像生成与编辑模型香港中文大学、香港科技大学与字节跳动联合推出开源模型 DreamOmni2,旨在突破当前 AI 图像编辑与生成的两大瓶颈:纯文本指令表达力有限,以及现有模型难以处理抽象概念(如风格、纹理、妆容等)。 ...图像模型# DreamOmni2# 图像生成6个月前01790
阶跃星辰发布 NextStep-1:140 亿参数自回归模型,用“连续令牌”重塑图像生成在图像生成领域,自回归模型长期被视作“文本专家,视觉弱项”——它们擅长逐词生成语言,却难以像扩散模型那样精细构建图像。而如今,阶跃星辰(StepFun)正试图打破这一边界。 GitHub:https...图像模型# NextStep-1# 图像生成# 图像编辑8个月前05350
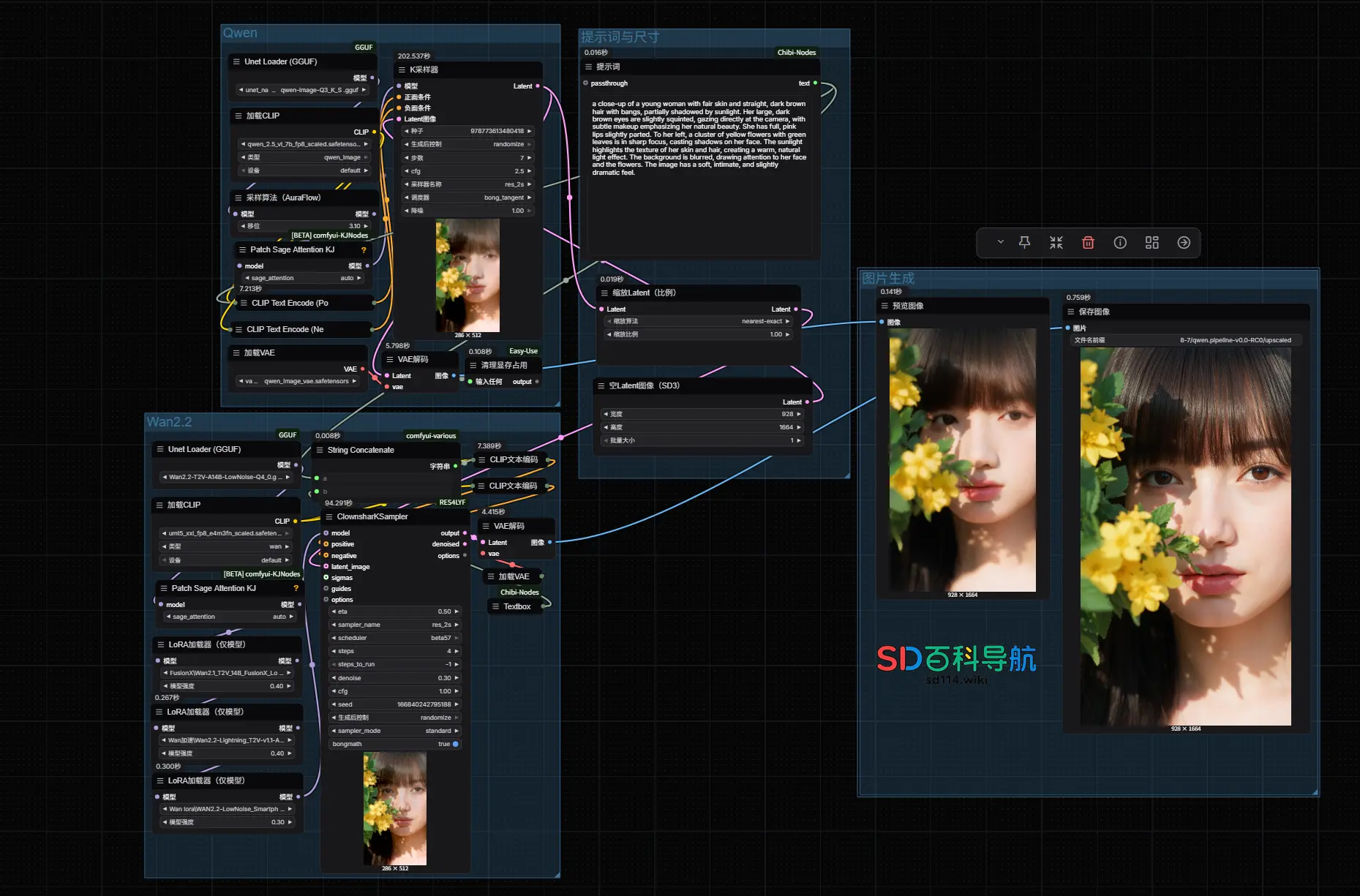
如何兼顾“创意”与“真实”?用 Qwen-Image + Wan 2.2 实现高质量图像生成阿里Qwen项目组近期发布的两款模型Qwen-Image和Wan 2.2都具有图像生成功能,但两款模型在生成图片的时候具有局限性: Qwen-Image 擅长创意构图,想象力丰富,但人物细节 AI 感...工作流# Qwen-Image# WAN 2.2# 图像生成8个月前01,6120
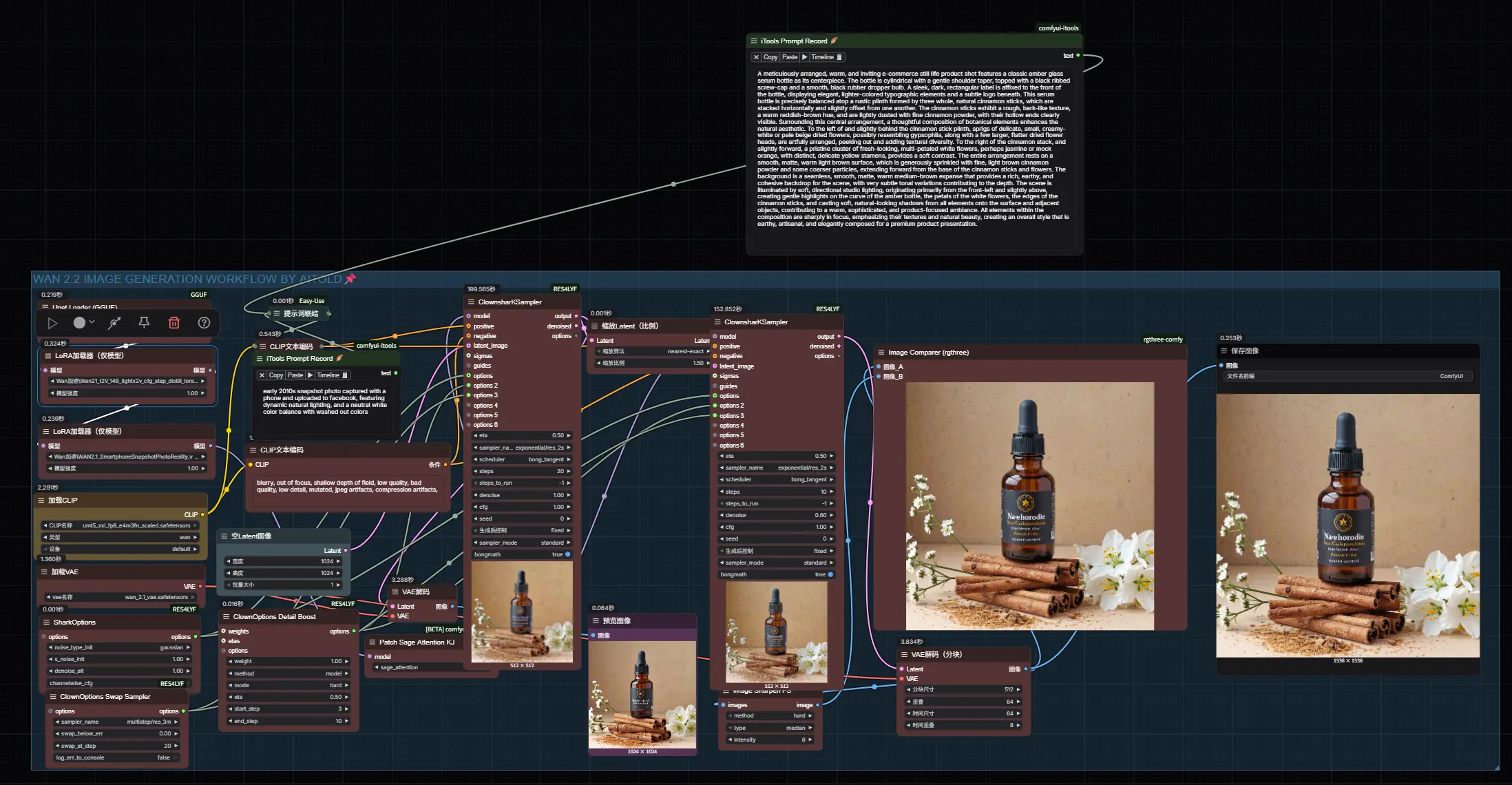
WAN 2.2 图像生成 + 高分辨率修复工作流指南尽管阿里发布的 WAN 2.1 和 WAN 2.2 主要定位为视频生成模型,但其强大的视觉建模能力同样适用于高质量静态图像生成任务。 网盘下载:https://www.123865.com/s/hyQ...工作流# WAN 2.2# 图像生成8个月前06040
黑森林实验室联合 KREA AI 发布 FLUX.1 Krea [dev]: 实现更真实、更自然的图像生成黑森林实验室(Black Forest Labs, BFL)与创意 AI 平台 KREA AI 正式宣布推出 FLUX.1 Krea [dev] —— 一个全新的开源文本到图像生成模型,也是 Krea...图像模型# FLUX.1 Krea [dev]# 图像生成# 黑森林实验室8个月前05780
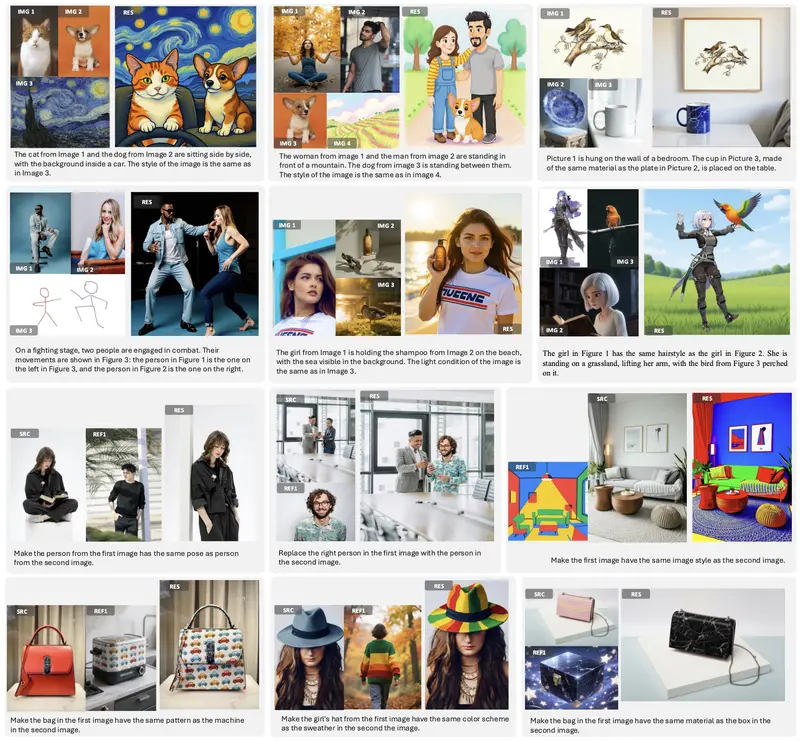
统一视觉理解与生成框架UniWorld:支持 20+语义图片编辑任务北京大学深圳研究生院、鹏城实验室、兔展AI的研究人员推出统一视觉理解与生成框架UniWorld,它基于强大的视觉-语言模型和对比语义编码器,能够同时处理图像感知和图像操控任务。 GitHub:http...图像模型# UniWorld# 图像生成# 图像编辑10个月前04580
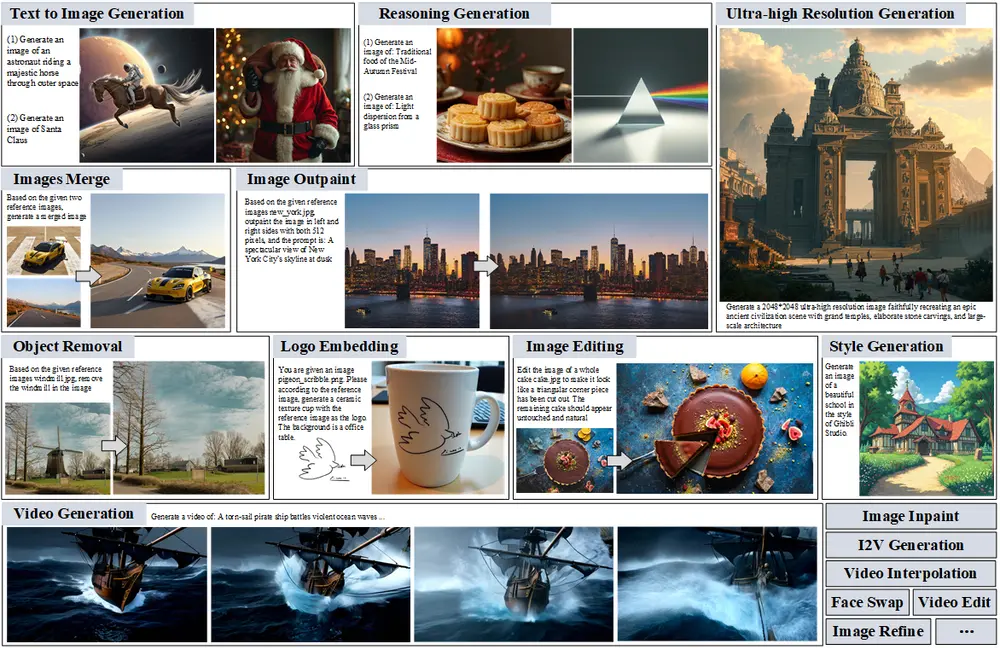
基于 ComfyUI 平台构建的协作式 AI 系统ComfyMind:打造稳定、灵活、可扩展的通用生成平台随着生成模型的飞速发展,“通用生成(General-Purpose Generation)”正成为 AI 领域的新焦点。它旨在通过一个统一系统,支持图像、视频、文本等多种模态任务的生成与编辑,为复杂创...新技术# ComfyMind# 图像生成# 视频生成10个月前03410
谷歌提升Gemini 2.0 Flash图像生成和编辑功能的能力基于开发者的热情反馈,谷歌激动地宣布,图像生成功能现已通过Gemini 2.0 Flash预览版推出。 开发者即日起可通过Google AI Studio和Vertex AI中的Gemini API...早报# Gemini 2.0 Flash# 图像生成# 谷歌11个月前04060
Meta AI 推出高效图像生成新方法Token-Shuffle:在 Transformer 中减少图像 Token自回归(AR)模型在语言生成领域取得了巨大成功,但在高分辨率图像合成中的应用却面临严峻挑战。与文本不同,图像需要数千个 token 来表示,导致计算成本呈二次方增长。这使得大多数基于 AR 的多模态模...新技术# Meta AI# Token-Shuffle# 图像生成11个月前02910
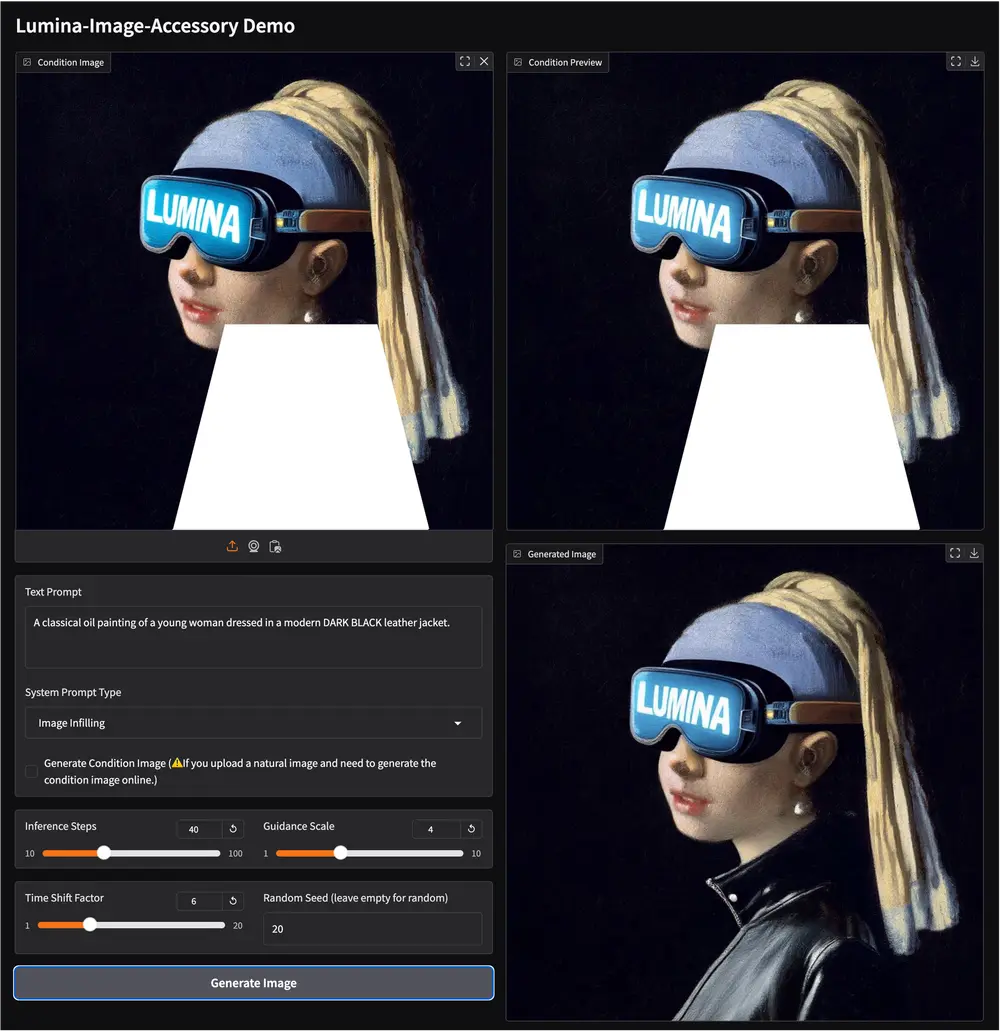
Lumina-Accessory:专为 Lumina 系列模型设计的多任务指令微调框架Lumina-Accessory 是一个专为 Lumina 系列模型设计的多任务指令微调框架,目前支持 Lumina-Image-2.0。该框架通过一系列创新设计,为图像生成和编辑任务提供了强大的支持...图像模型# Lumina-Accessory# Lumina-Image 2.0# 图像生成11个月前03960
新型框架 EliGen:用于实现图像生成中的实体级控制浙江大学控制科学与工程学院、阿里巴巴集团ModelScope团队和华东师范大学的研究人员推出新型框架 EliGen,用于实现图像生成中的实体级控制。EliGen 通过引入区域注意力(Regional ...图像模型# EliGen# 图像生成1年前02380


![黑森林实验室联合 KREA AI 发布 FLUX.1 Krea [dev]: 实现更真实、更自然的图像生成](https://pic.sd114.wiki/wp-content/uploads/2025/08/1753986665-1753986665-FLUX-Krea-2.webp~tplv-o4t1hxlaqv-image.image)