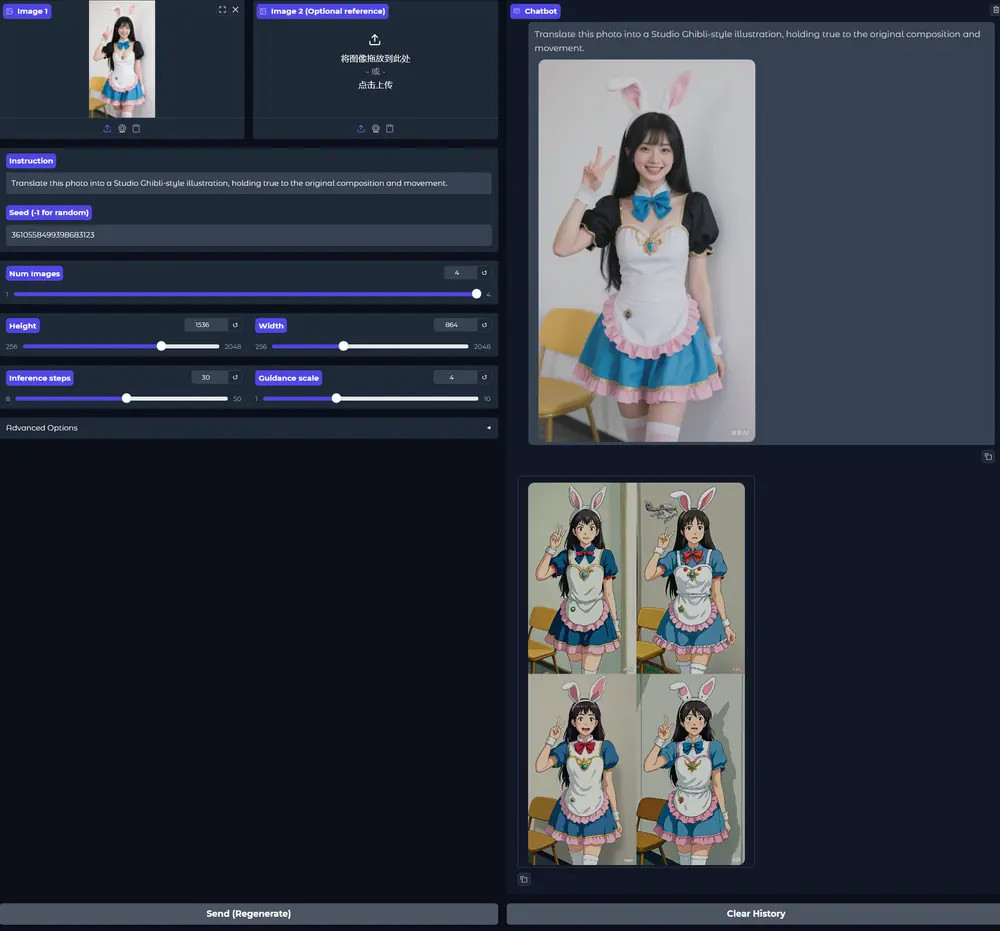
自回归模型Lumina-mGPT 2.0:支持文生图、多轮图像编辑、可控生成等上海人工智能实验室和香港中文大学的研究人员之前推出了新型多模态自回归模型Lumina-mGPT,研究团队在今天推出了一种独立的、仅解码器的自回归模型Lumina-mGPT 2.0,从头开始训练,统一了...图像模型# Lumina-mGPT 2.0# 自回归模型10个月前03960
图像修复模型PixelHacker:基于潜在类别引导并结合扩散模型,显著提升图像修复质量图像修复(Image Inpainting)是计算机视觉领域的重要研究方向,旨在通过生成合理的图像内容填补缺失或损坏的部分。然而,现有方法在处理复杂结构(如纹理、形状和空间关系)以及语义一致性(如颜色...图像模型# PixelHacker# 图像修复模型9个月前03920
混合自回归变换器HART:高效生成高分辨率图像现有的自回归(AR)视觉生成模型在生成高分辨率图像时面临两大挑战:离散分词器的图像重建质量较差,以及生成1024px图像的训练成本过高。为了解决这些问题,麻省理工学院、英伟达和清华大学的研究人员提出了...图像模型# HART# 混合自回归变换器12个月前03920
统一视觉理解与生成框架UniWorld:支持 20+语义图片编辑任务北京大学深圳研究生院、鹏城实验室、兔展AI的研究人员推出统一视觉理解与生成框架UniWorld,它基于强大的视觉-语言模型和对比语义编码器,能够同时处理图像感知和图像操控任务。 GitHub:http...图像模型# UniWorld# 图像生成# 图像编辑8个月前03910
基于扩散模型的微调协议Marigold:用于各种图像分析任务,例如单目深度估计、表面法线预测和内在图像分解苏黎世联邦理工学院的研究人员推出一个基于扩散模型(diffusion-based models)的微调协议Marigold,用于各种图像分析任务,例如单目深度估计、表面法线预测和内在图像分解。Mari...图像模型# Marigold# 扩散模型9个月前03910
新型图像编码器FlexTok:能够将二维图像重新采样为长度可变的一维离散标记(token)序列苹果和瑞士洛桑联邦理工学院的研究人员推出新型图像编码器FlexTok,它能够将二维图像重新采样为长度可变的一维离散标记(token)序列。FlexTok 的核心思想是通过灵活的标记长度来适应图像的复杂...图像模型# FlexTok# 图像编码器10个月前03910
ITF SkinDiffDDS v1:专为处理 DDS 压缩后皮肤漫反射纹理的质量问题而设计的模型ITF SkinDiffDDS v1 是一款专为处理 DDS 压缩后皮肤漫反射纹理的质量问题而设计的模型。这款模型的主要目标是去除压缩过程中产生的条带、块状、抖动、走样、噪点和颜色偏移等瑕疵,从而提升...图像模型# ITF SkinDiffDDS v1# 皮肤12个月前03910
高效、可扩展框架CtrLoRA:结合了基础 ControlNet 和条件特定 LoRAs 的可控图像生成框架来自中国科学院计算技术研究所和中国科学院大学的研究人员推出一种用于可控图像生成的高效、可扩展框架CtrLoRA,这是一个结合了基础 ControlNet 和条件特定 LoRAs 的可控图像生成框架。简...图像模型# ControlNe# CtrLoRA# LoRAs12个月前03870
上海大学联合vivo推出新型交互式图像抠图方法SDMatte:用扩散模型重新定义交互式抠图上海大学与 vivo 联合研究团队近期提出一种名为 SDMatte 的新型交互式图像抠图方法。该方法基于稳定扩散模型(Stable Diffusion),支持点、框和掩码三种视觉提示,能够从自然图像中...图像模型# SDMatte# 图像抠图6个月前03860
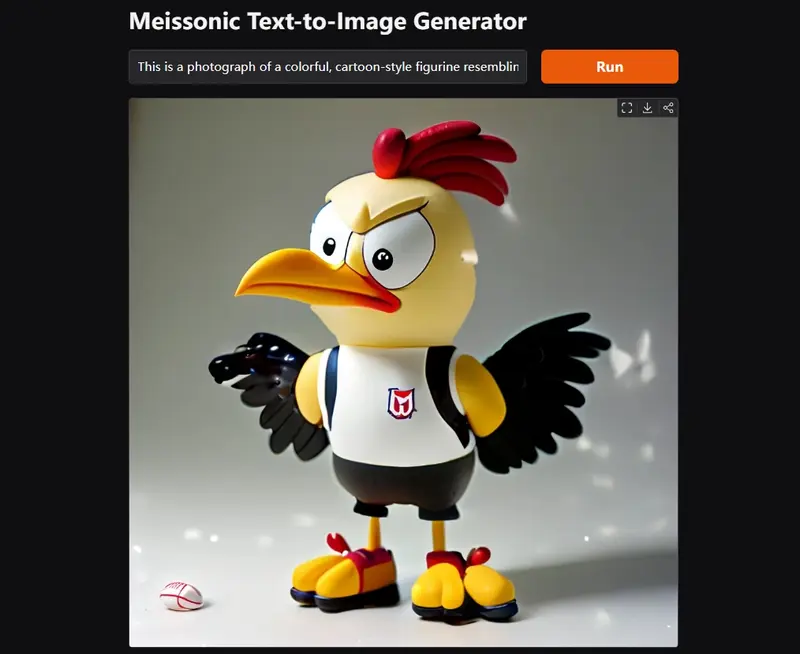
非自回归 MIM 文生图合成模型Meissonic:生成高质量、高分辨率的图像随着大语言模型(LLMs)在自然语言处理任务中的显著进步,研究人员开始探索类似的文本到图像合成方法。与此同时,扩散模型已经成为视觉生成的主流方法。然而,由于语言和视觉任务之间存在显著的操作差异,开发统...图像模型# Meissonic# 文生图合成模型12个月前03860
URAE:基于 Flux的超高分辨率图像生成的高效解决方案在图像生成领域,高分辨率图像的生成一直是一个极具挑战性的问题,尤其是在训练数据和计算资源有限的情况下。新加坡国立大学的研究人员推出了一种名为 URAE(Ultra-Resolution Adaptat...图像模型# FLUX# URAE10个月前03800
用文生图的新型规模感知变换器SWITTI:基于现有的下一代规模预测自回归(AR)模型Yandex Research、俄罗斯国立研究型大学高等经济学院、莫斯科物理技术学院和Skoltech科大的研究人员推出新型规模感知变换器SWITTI,它用于文本到图像的合成。SWITTI基于现有的下...图像模型# AR模型# SWITTI12个月前03750