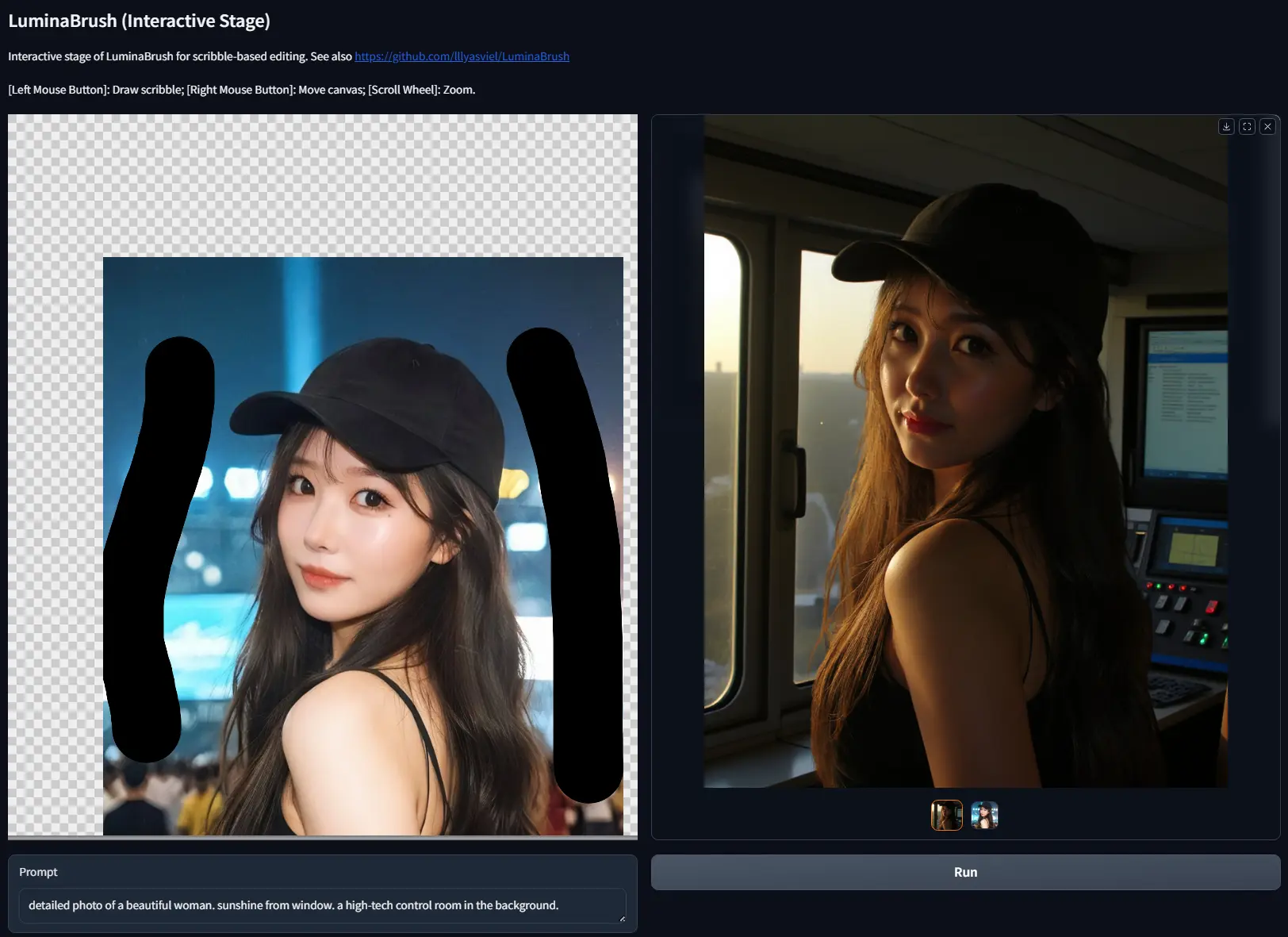
lllyasviel推出交互式图像光照绘制新框架LuminaBrushControlNet的作者lllyasviel继推出IC-Light系列之后,再次推出了一个全新的项目——LuminaBrush。这个项目旨在为用户提供一种简单而强大的方式,在图像上绘制和调整光照效果...图像模型# LuminaBrush# 光照绘制1年前03470
三阶段扩散模型框架ColorFlow:专门用于解决黑白图像的自动着色问题ColorFlow 是由清华大学和腾讯ARC实验室提出的一个创新性三阶段扩散模型框架,专门用于解决黑白图像序列的自动着色问题。该模型旨在确保角色和对象的身份(ID)在着色过程中得到一致保留,同时生成高...图像模型# ColorFlow1年前03410
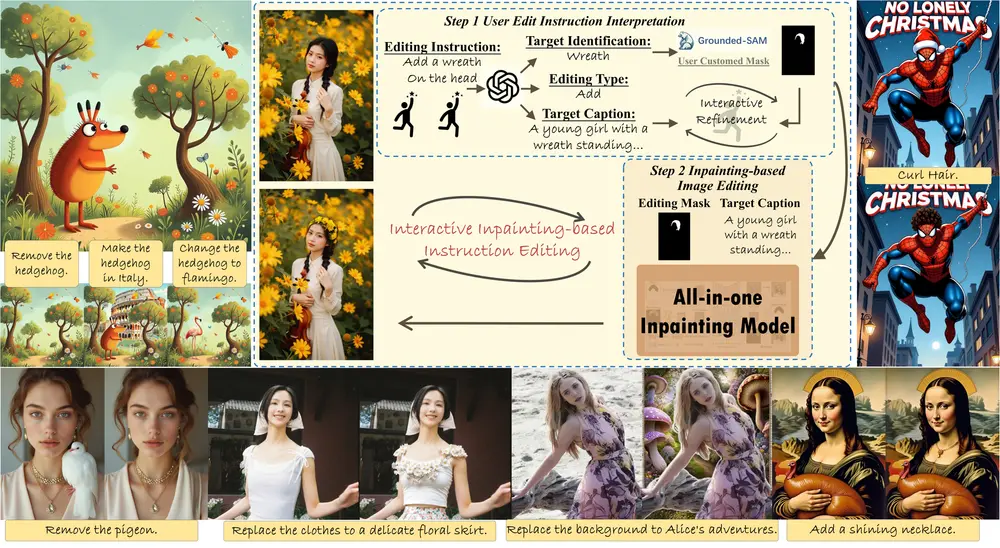
基于修复的指令引导图像编辑框架BrushEdit:通过自然语言指令进行无缝编辑,包括添加对象、移除元素或进行结构性更改等多样化编辑操作图像编辑技术近年来在基于反演(inversion-based)和基于指令(instruction-based)的方法上取得了显著进步。然而,这些方法各自存在局限性: 基于反演的方法:在处理重大修改(如...图像模型# BrushEdit# 图像编辑1年前03370
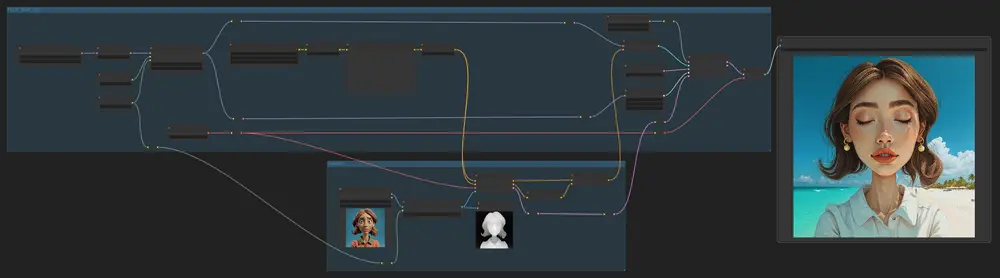
新型插件式适应方法EasyRef:允许扩散模型根据多个参考图像和文本提示进行条件生成在个性化生成任务中,扩散模型(Diffusion Models)已经取得了显著的成就。传统的无需调优的方法通常通过平均多个参考图像的图像嵌入作为注入条件来编码,但这种与图像无关的操作无法在图像之间进行...图像模型# EasyRef# 扩散模型1年前03160
FLUX.1 Tools 系列模型FP8量化版本,适合小显存用户使用黑森林实验室(Black Forest Labs)在上个月发布了 FLUX.1 Tools 系列开源模型,旨在为图像处理和生成任务提供强大的工具。该系列包括以下三个主要模型: FLUX.1 Fill...图像模型# FLUX.1 Canny# FLUX.1 Depth# FLUX.1 Fill1年前03430
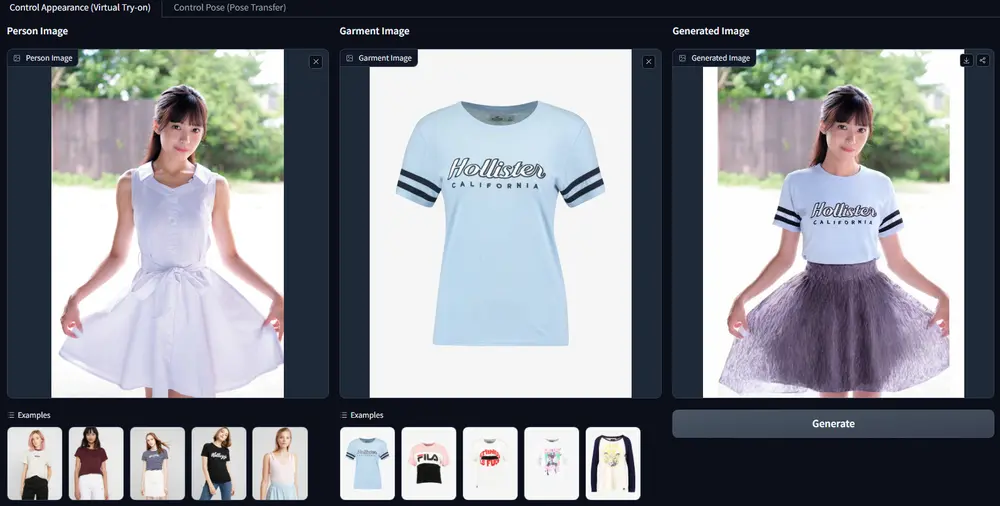
Leffa:通过参考图像生成人物图像,允许对人物的外观或姿势进行精确控制可控人物图像生成的目标是根据参考图像生成高质量的人物图像,同时允许对人物的外观或姿势进行精确控制。尽管现有的方法在整体图像质量上取得了显著进展,但它们往往会在生成过程中扭曲参考图像中的细粒度纹理细节...图像模型# Leffa# 虚拟试穿1年前03260
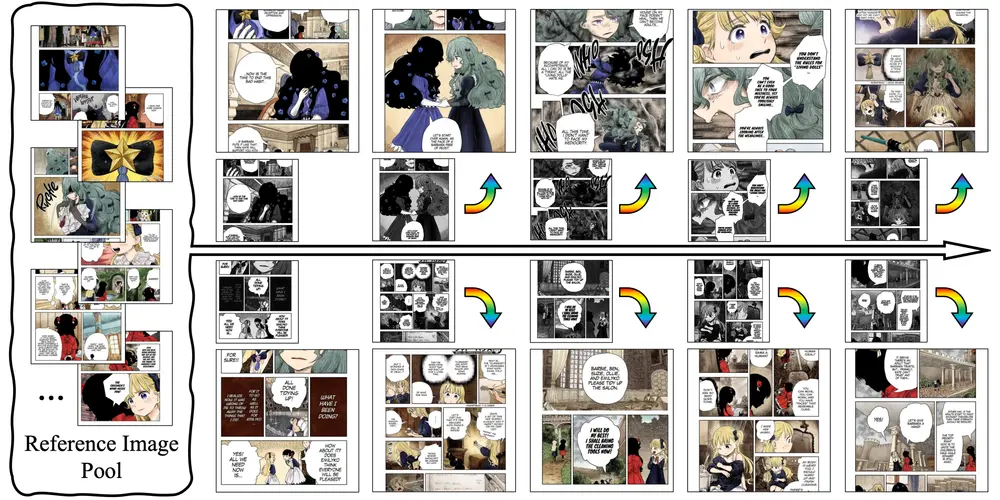
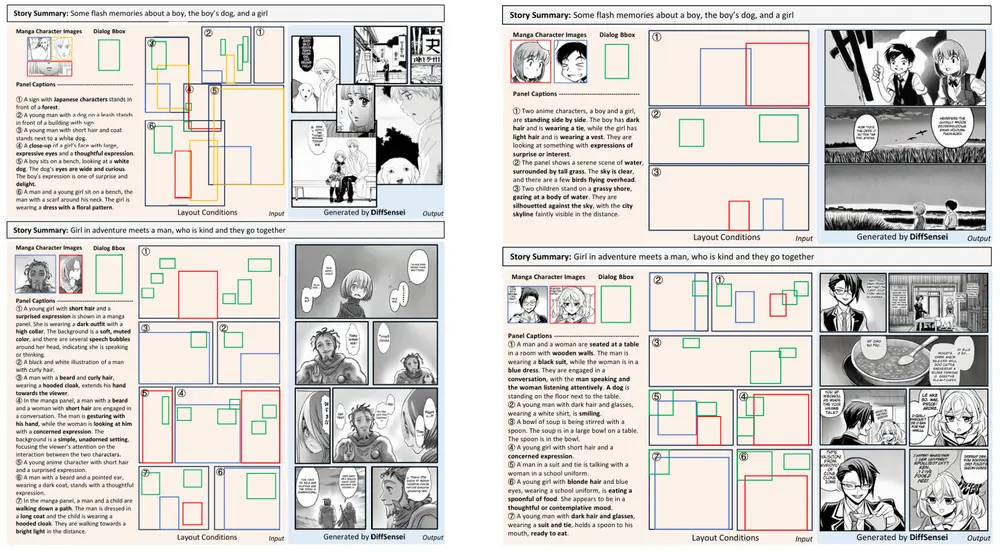
用于定制漫画生成的新框架DiffSensei:将多模态大语言模型和扩散模型结合起来,以实现对漫画角色形象和布局的精确控制故事可视化,即将文本描述转化为视觉叙事的任务,近年来随着文本到图像生成模型的发展取得了显著进展。然而,现有的模型在处理多角色场景时,特别是在控制角色外观和互动方面,仍然存在局限性。具体来说,这些模型难...图像模型# DiffSensei# 定制漫画1年前03270
单步扩散方法NitroFusion:通过动态对抗框架实现高质量的图像生成萨里大学和NetMind.AI的研究人员提出了NitroFusion,这是一种根本不同的单步扩散方法,旨在通过动态对抗框架实现高质量的图像生成。尽管单步方法在速度上具有显著优势,但它们通常在生成质量上...图像模型# NitroFusion# 单步扩散1年前03720
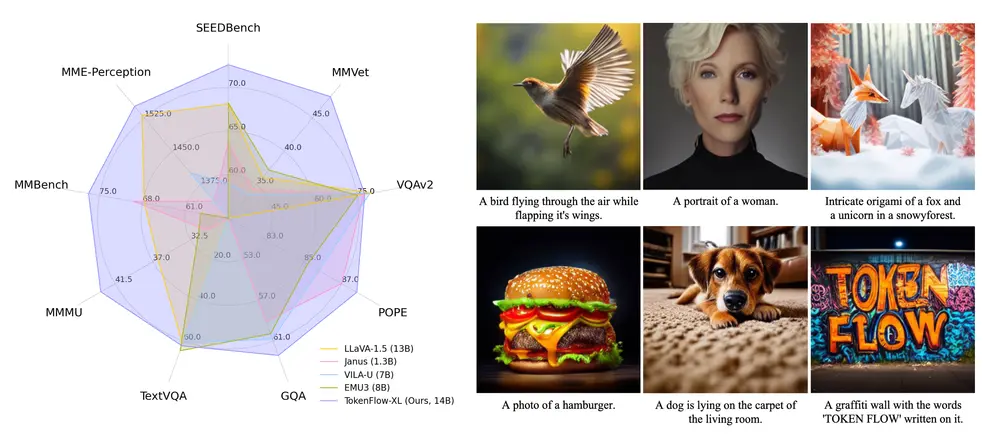
字节跳动推出新型统一图像标记器TokenFlow:弥合多模态理解和生成之间的长期存在的差距字节跳动的研究团队提出了TokenFlow,这是一种新颖的统一图像标记器,旨在弥合多模态理解和生成之间的长期存在的差距。先前的方法尝试使用单一的重建导向向量量化(VQ)编码器来统一这两项任务,但这种做...图像模型# TokenFlow# 统一图像标记器1年前03420
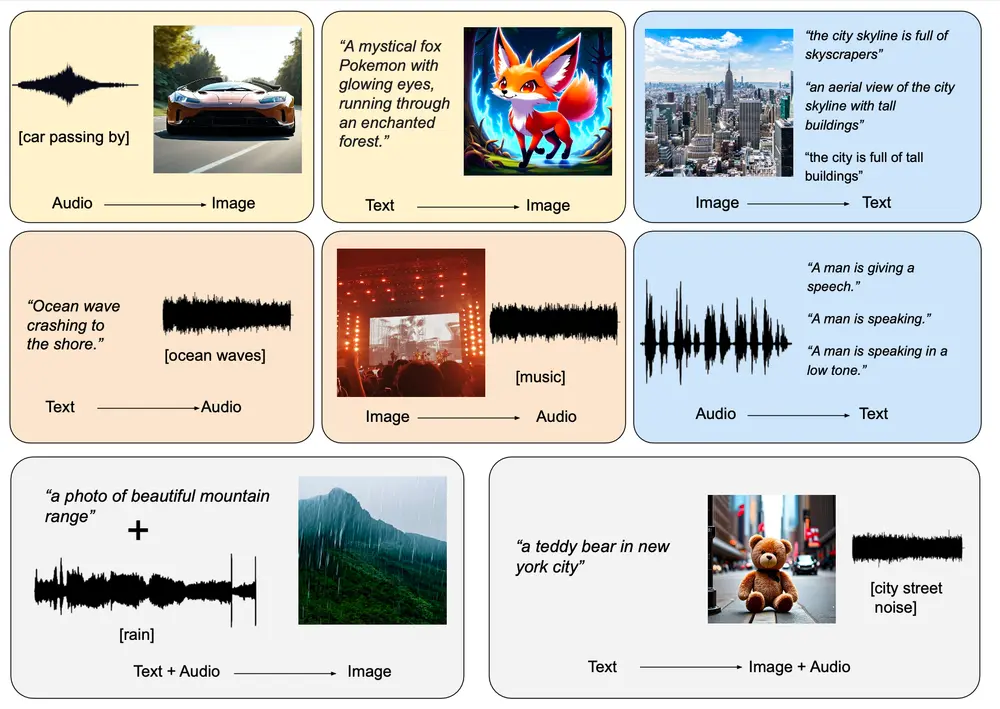
新型生成模型OmniFlow:用于处理任何到任何(any-to-any)的多模态生成任务,例如文本到图像、文本到音频以及音频到图像的合成加州大学洛杉矶分校、松下AI研究院和Salesforce AI研究院的研究人员共同提出了OmniFlow,这是一种新颖的生成模型,专为处理“任何到任何”(any-to-any)生成任务设计,如文本到图...图像模型# OmniFlow# 多模态生成1年前03190
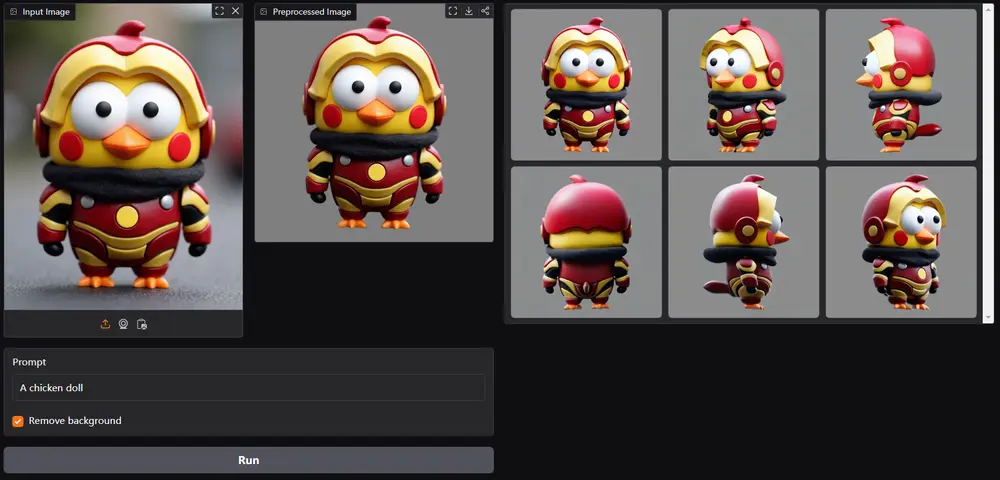
多功能即插即用适配器MV-Adapter:将SDXL模型及其衍生模型适配为多视图生成器。现有的多视图图像生成方法通常对预训练的文生图模型进行侵入性修改,并需要全面微调,导致高计算成本和图像质量下降。为了解决这些问题,北京航空航天大学、VAST 和上海交通大学的研究人员提出了 MV-Ada...图像模型# MV-Adapter# SDXL模型# 多视图1年前03570
SWITTI:用于文本到图像合成的新型规模感知变换器模型Yandex Research、HSE 大学、MIPT 和 Skoltech 的研究人员提出了 Switti,这是一个专门设计用于文本到图像(T2I)生成的尺度变换器。Switti 从现有的下一尺度预...图像模型# SWITTI# 文生图模型1年前03190